k-means clustering
From Wikipedia, the free encyclopedia
In statistics and machine learning, k-means clustering is a method of cluster analysis which aims to partition n objects into k clusters in which each object belongs to the cluster with the nearest mean. It is similar to the expectation-maximization algorithm for mixtures of Gaussians in that they both attempt to find the centers of natural clusters in the data.
Contents |
[edit] Description
Given a set of observations (x1,x2,…,xn), where each observation is a d-dimensional real vector, then k-means clustering aims to partition this set into k partitions (k<n) S={S1,S2,…,Sk} so as to minimize total intra-cluster variance, or, the squared error function

where μi is the mean of Si.
[edit] History
The k-means clustering was invented in 1956.[1] The most common form of the algorithm uses an iterative refinement heuristic known as Lloyd's algorithm.[2] Lloyd's algorithm starts by partitioning the input points into k initial sets, either at random or using some heuristic data. It then calculates the mean point, or centroid, of each set. It constructs a new partition by associating each point with the closest centroid. Then the centroids are recalculated for the new clusters, and algorithm repeated by alternate application of these two steps until convergence, which is obtained when the points no longer switch clusters (or alternatively centroids are no longer changed).
Lloyd's algorithm and k-means are often used synonymously, but in reality Lloyd's algorithm is a heuristic for solving the k-means problem,[3] as with certain combinations of starting points and centroids, Lloyd's algorithm can in fact converge to the wrong answer (i.e. a different and locally optimal answer to the minimization function above exists.)
Other variations exist,[4] but Lloyd's algorithm has remained popular because it converges extremely quickly in practice. In fact, many have observed that the number of iterations is typically much less than the number of points. Recently, however, David Arthur and Sergei Vassilvitskii showed that there exist certain point sets on which k-means takes superpolynomial time: 2Ω(√n) to converge.[5]
Approximate k-means algorithms have been designed that make use of coresets: small subsets of the original data.
In terms of performance the algorithm is not guaranteed to return a global optimum. The quality of the final solution depends largely on the initial set of clusters, and may, in practice, be much poorer than the global optimum[6]. Since the algorithm is extremely fast, a common method is to run the algorithm several times and return the best clustering found.
A drawback of the k-means algorithm is that the number of clusters k is an input parameter. An inappropriate choice of k may yield poor results. The algorithm also assumes that the variance is an appropriate measure of cluster scatter.
[edit] Demonstration of the algorithm
The following images demonstrate the k-means clustering algorithm in action, for the two-dimensional case. The initial centres are generated randomly to demonstrate the stages in more detail. The background space partitions are only for illustration and are not generated by the k-means algorithm.
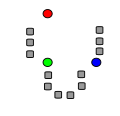 First, k initial points (in this case k=3) are randomly selected from the data set (shown in color). |
 k groupings are created by associating every individual point with the nearest initial randomized point. |
 The centroid points of each of the k clusters becomes the new initial randomized points. |
 Steps 2 & 3 are repeated until a suitable level of convergence has been reached. |
[edit] Pseudocode
Initialize the algorithm either heuristically or randomly. Iterate the following steps until convergence (stopping criteria met):
- For each data point x, compute its membership in clusters by choosing the nearest centroid
- For each centroid, recompute its location according to members
var m = initialCentroids(x, K);
var N = x.length;
while (!stoppingCriteria) {
var w = [][];
// calculate membership in clusters
for (var n = 1; n <= N; n++) {
v = arg min (v0) dist(m[v0], x[n]);
w[v].push(n);
}
// recompute the centroids
for (var k = 1; k <= K; k++) {
m[k] = avg(x in w[k]);
}
}
return m;
[edit] Applications of the algorithm
[edit] Image segmentation
The k-means clustering algorithm is commonly used in computer vision as a form of image segmentation. The results of the segmentation are used to aid border detection and object recognition. In this context, the standard Euclidean distance is usually insufficient in forming the clusters. Instead, a weighted distance measure utilizing pixel coordinates, RGB pixel color and/or intensity, and image texture is commonly used.[7]
[edit] Relation to PCA
It has been shown[8][9] that the relaxed solution of k-means clustering, specified by the cluster indicators, is given by the PCA (principal component analysis) principal components, and the PCA subspace spanned by the principal directions is identical to the cluster centroid subspace specified by the between-class scatter matrix.
[edit] Variations
The set of squared error minimizing cluster functions also includes the k-medoids algorithm, an approach which forces the center point of each cluster to be one of the actual points, i.e. it uses medoids in place of centroids.
An alternative method for choosing the initial centers was proposed in 2006 [3], dubbed "k-means++". The idea is to select centers in a way that they are already initially close to large quantities of points. The authors use L2 norm in selecting the centers, but general Ln may be used to tune the aggressiveness of the seeding.
[edit] See also
[edit] Notes
- ^ H. Steinhaus. Sur la division des corp materiels en parties. Bull. Acad. Polon. Sci., C1. III vol IV:801– 804, 1956.
- ^ S. Lloyd, Last square quantization in PCM’s. Bell Telephone Laboratories Paper (1957). Published in journal much later: S. P. Lloyd. Least squares quantization in PCM. Special issue on quantization, IEEE Trans. Inform. Theory, 28:129–137, 1982.
- ^ a b D. Arthur, S. Vassilvitskii: "k-means++ The Advantages of Careful Seeding" 2007 Symposium on Discrete Algorithms (SODA).
- ^ T. Kanungo, D. M. Mount, N. Netanyahu, C. Piatko, R. Silverman, and A. Y. Wu: "An efficient k-means clustering algorithm: Analysis and implementation" IEEE Trans. Pattern Analysis and Machine Intelligence, 24 (2002), 881-892.
- ^ David Arthur & Sergei Vassilvitskii (2006). "How Slow is the k-means Method?". Proceedings of the 2006 Symposium on Computational Geometry (SoCG).
- ^ Kryzysztof Cios, Witold Pedrycz, Roman Swiniarski - "Data Mining Methods for Knowledge Discover", 1998, Kluwer Acadmenic Publishers, page 383 to 384
- ^ Shapiro, Linda G. & Stockman, George C. (2001). Computer Vision. Upper Saddle River, NJ: Prentice Hall.
- ^ H. Zha, C. Ding, M. Gu, X. He and H.D. Simon. "Spectral Relaxation for K-means Clustering", Neural Information Processing Systems vol.14 (NIPS 2001). pp. 1057-1064, Vancouver, Canada. Dec. 2001.
- ^ Chris Ding and Xiaofeng He. "K-means Clustering via Principal Component Analysis". Proc. of Int'l Conf. Machine Learning (ICML 2004), pp 225-232. July 2004.
[edit] References
- MacQueen, J. B. (1967). "Some Methods for classification and Analysis of Multivariate Observations" in Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability. 1: 281–297, University of California Press. MR0214227. Retrieved on 2009-04-07.
- J. A. Hartigan (1975) "Clustering Algorithms". Wiley.
- Hartigan, J. A.; Wong, M. A. (1979). "Algorithm AS 136: A K-Means Clustering Algorithm". Applied Statistics 28 (1): 100–108. JSTOR: 2346830.
- MacKay, David (2003). "Chapter 20. An Example Inference Task: Clustering". Information Theory, Inference and Learning Algorithms. Cambridge University Press. ISBN 0-521-64298-1. http://www.inference.phy.cam.ac.uk/mackay/itprnn/ps/284.292.pdf.
- Data Mining (1998): "Methods for Knowledge Discovery" Kluwer Academic Publishers
[edit] External links
- Application to Web Site clustering in PHP
- Numerical Example of K-means clustering
- Application example which uses K-means clustering to reduce the number of colors in images
- Interactive demo of the K-means-algorithm(Applet)
- An example of multithreaded application which uses K-means in Java
- K-means application in php
- Another animation of the K-means-algorithm
- A fast implementation of the K-means algorithm which uses the triangle inequality to speed up computation
- K-means clustering using Perl. Online clustering.
- K-means clustering using C++
- K-means clustering implementation in Ruby (AI4R)

