Nondeterministic finite state machine
From Wikipedia, the free encyclopedia
In the theory of computation, a nondeterministic finite state machine or nondeterministic finite automaton (NFA) is a finite state machine where for each pair of state and input symbol there may be several possible next states. This distinguishes it from the deterministic finite automaton (DFA), where the next possible state is uniquely determined. Although the DFA and NFA have distinct definitions, it may be shown in the formal theory that they are equivalent, in that, for any given NFA, one may construct an equivalent DFA, and vice-versa: this is the powerset construction. Both types of automata recognize only regular languages. Non-deterministic finite state machines are sometimes studied by the name subshifts of finite type. Non-deterministic finite state machines are generalized by probabilistic automata, which assign a probability to each state transition.
Nondeterministic finite automata were introduced by Michael O. Rabin and Dana Scott in 1959[1], who showed their equivalence to deterministic automata.
Contents |
[edit] Intuitive introduction
An NFA, just as a DFA, consumes a string of input symbols. For each input symbol it transitions to a new state until all input symbols have been consumed.
Unlike a DFA, it is non-deterministic in that, for any input symbol, its next state may be any one of several possible states. Thus, in the formal definition, the next state is an element of the power set of states. This element, itself a set, represents some subset of all possible states to be considered at once.
An extension of the NFA is the NFA-lambda (also known as NFA-epsilon or the NFA with epsilon moves), which allows a transformation to a new state without consuming any input symbols. For example, if it is in state 1, with the next input symbol an a, it can move to state 2 without consuming any input symbols, and thus there is an ambiguity: is the system in state 1, or state 2, before consuming the letter a? Because of this ambiguity, it is more convenient to talk of the set of possible states the system may be in. Thus, before consuming letter a, the NFA-epsilon may be in any one of the states out of the set {1,2}. Equivalently, one may imagine that the NFA is in state 1 and 2 'at the same time': and this gives an informal hint of the powerset construction: the DFA equivalent to an NFA is defined as the one that is in the state q={1,2}. Transformations to new states without consuming an input symbol are called lambda transitions or epsilon transitions. They are usually labeled with the Greek letter λ or ε.
The notion of accepting an input is similar to that for the DFA. When the last input symbol is consumed, the NFA accepts if and only if there is some set of transitions that will take it to an accepting state. Equivalently, it rejects, if, no matter what transitions are applied, it would not end in an accepting state.
[edit] Formal definition
Two similar types of NFA's are commonly defined: the NFA and the NFA with ε-moves. The ordinary NFA is defined as a 5-tuple, (Q, Σ, T, q0, F), consisting of
- a finite set of states Q
- a finite set of input symbols Σ
- a transition function T : Q × Σ → P(Q).
- an initial (or start) state q0 ∈ Q
- a set of states F distinguished as accepting (or final) states F ⊆ Q.
Here, P(Q) denotes the power set of Q. The NFA with ε-moves (also sometimes called NFA-epsilon or NFA-lambda) replaces the transition function with one that allows the empty string ε as a possible input, so that one has instead
- T : Q × (Σ ∪{ε}) → P(Q).
It can be shown that ordinary NFA and NFA with epsilon moves are equivalent, in that, given either one, one can construct the other, which recognizes the same language.
[edit] Properties
The machine starts in the specified initial state and reads in a string of symbols from its alphabet. The automaton uses the state transition function T to determine the next state using the current state, and the symbol just read or the empty string. However, "the next state of an NFA depends not only on the current input event, but also on an arbitrary number of subsequent input events. Until these subsequent events occur it is not possible to determine which state the machine is in" [2]. If, when the automaton has finished reading, it is in an accepting state, the NFA is said to accept the string, otherwise it is said to reject the string.
The set of all strings accepted by an NFA is the language the NFA accepts. This language is a regular language.
For every NFA a deterministic finite state machine (DFA) can be found that accepts the same language. Therefore it is possible to convert an existing NFA into a DFA for the purpose of implementing a (perhaps) simpler machine. This can be performed using the powerset construction, which may lead to an exponential rise in the number of necessary states. A formal proof of the powerset construction is given here.
For non-deterministic automata with a countably infinite set of states, the powerset construction gives a deterministic automaton with a continuum of states (since the powerset of the countable infinity is the continuum:  ). In such a case, the set of states must be endowed with a topology in order for the state transitions to be meaningful. Such systems are studied as topological automata.
). In such a case, the set of states must be endowed with a topology in order for the state transitions to be meaningful. Such systems are studied as topological automata.
[edit] Properties of NFA-ε
For all  one writes
one writes  if and only if q can be reached from p by going along zero or more ε arrows. In other words, if and only if there exists
if and only if q can be reached from p by going along zero or more ε arrows. In other words, if and only if there exists  where
where 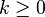 such that
such that
 .
.
For any  , the set of states that can be reached from p is called the epsilon-closure or ε-closure of p, and is written as
, the set of states that can be reached from p is called the epsilon-closure or ε-closure of p, and is written as
 .
.
For any subset  , define the ε-closure of P as
, define the ε-closure of P as
 .
.
The epsilon-transitions are transitive, in that it may be shown that, for all  and , if
and , if  and
and  , then
, then  .
.
Similarly, if  and then
and then 
Let x be a string over the alphabet Σ∪{ε}. An NFA-ε M accepts the string x if there exist both a representation of x of the form x1x2 ... xn, where xi ∈ (Σ ∪{ε}), and a sequence of states p0,p1, ..., pn, where pi ∈ Q, meeting the following conditions:
- p0
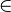 E({q0})
E({q0}) - pi E(T(pi-1, xi )) for i = 1, ..., n
- pn F.
[edit] Implementation
There are many ways to implement a NFA:
- Convert to the equivalent DFA. In some cases this may cause exponential blowup in the size of the automaton and thus auxiliary space proportional to the number of states in the NFA (as storage of the state value requires at most one bit for every state in the NFA)
- Keep a set data structure of all states which the machine might currently be in. On the consumption of the last input symbol, if one of these states is a final state, the machine accepts the string. In the worst case, this may require auxiliary space proportional to the number of states in the NFA; if the set structure uses one bit per NFA state, then this solution is exactly equivalent to the above.
- Create multiple copies. For each n way decision, the NFA creates up to n − 1 copies of the machine. Each will enter a separate state. If, upon consuming the last input symbol, at least one copy of the NFA is in the accepting state, the NFA will accept. (This, too, requires linear storage with respect to the number of NFA states, as there can be one machine for every NFA state.)
- Explicitly propagate tokens through the transition structure of the NFA and match whenever a token reaches the final state. This is sometimes useful when the NFA should encode additional context about the events that triggered the transition. (For an implementation that uses this technique to keep track of object references have a look at Tracematches [3].)
[edit] Example
The following example explains a NFA M, with a binary alphabet, which determines if the input contains an even number of 0s or an even number of 1s. Let M = (Q, Σ, T, s0, F) where
- Σ = {0, 1},
- Q = {s0, s1, s2, s3, s4},
- E({s0}) = { s0, s1, s3 }
- F = {s1, s3}, and
- The transition function T can be defined by this state transition table:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The state diagram for M is:
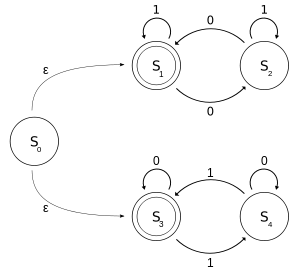
M can be viewed as the union of two DFAs: one with states {S1, S2} and the other with states {S3, S4}.
The language of M can be described by the regular language given by this regular expression:

[edit] Application of NFA-ε
NFAs and DFAs are equivalent in that if a language is recognized by an NFA, it is also recognized by a DFA and vice versa. The establishment of such equivalence is important and useful. It is useful because constructing an NFA to recognize a given language is sometimes much easier than constructing a DFA for that language. It is important because NFA's can be used to reduce the complexity of the mathematical work required to establish many important properties in the theory of computation. For example, it is much easier to prove the following properties using NFAs than DFAs:
(i) The union of two regular languages is regular.
(ii) The concatenation of two regular languages is regular.
(iii) The Kleene Closure of a regular language is regular.
[edit] Notes
- ^ M. O. Rabin and D. Scott, "Finite Automata and their Decision Problems", IBM Journal of Research and Development, 3:2 (1959) pp.115-125.
- ^ FOLDOC Free Online Dictionary of Computing, Finite State Machine
- ^ Allan, C., Avgustinov, P., Christensen, A. S., Hendren, L., Kuzins, S., Lhoták, O., de Moor, O., Sereni, D., Sittampalam, G., and Tibble, J. 2005. Adding trace matching with free variables to AspectJ. In Proceedings of the 20th Annual ACM SIGPLAN Conference on Object Oriented Programming, Systems, Languages, and Applications (San Diego, CA, USA, October 16 - 20, 2005). OOPSLA '05. ACM, New York, NY, 345-364.
[edit] References
- Michael Sipser, Introduction to the Theory of Computation. PWS, Boston. 1997. ISBN 0-534-94728-X. (see section 1.2: Nondeterminism, pp.47–63.)
- John E. Hopcroft and Jeffrey D. Ullman, Introduction to Automata Theory, Languages and Computation, Addison-Wesley Publishing, Reading Massachusetts, 1979. ISBN 0-201-029880-X. (See chapter 2.)
|
||||||||||||||||||||||||||||||||||||||||||||||||

