Cluster analysis
From Wikipedia, the free encyclopedia
Clustering is the assignment of objects into groups (called clusters) so that objects from the same cluster are more similar to each other than objects from different clusters. Often similarity is assessed according to a distance measure. Clustering is a common technique for statistical data analysis, which is used in many fields, including machine learning, data mining, pattern recognition, image analysis and bioinformatics.
Besides the term data clustering (or just clustering), there are a number of terms with similar meanings, including cluster analysis, automatic classification, numerical taxonomy, botryology and typological analysis.
Contents |
[edit] Types of clustering
Data clustering algorithms can be hierarchical. Hierarchical algorithms find successive clusters using previously established clusters. Hierarchical algorithms can be agglomerative ("bottom-up") or divisive ("top-down"). Agglomerative algorithms begin with each element as a separate cluster and merge them into successively larger clusters. Divisive algorithms begin with the whole set and proceed to divide it into successively smaller clusters.
Partitional algorithms typically determine all clusters at once, but can also be used as divisive algorithms in the hierarchical clustering.
Density-based clustering algorithms are devised to discover arbitrary-shaped clusters. In this approach, a cluster is regarded as a region in which the density of data objects exceeds a threshold. DBSCAN and OPTICS are two typical algorithms of this kind.
Two-way clustering, co-clustering or biclustering are clustering methods where not only the objects are clustered but also the features of the objects, i.e., if the data is represented in a data matrix, the rows and columns are clustered simultaneously.
Another important distinction is whether the clustering uses symmetric or asymmetric distances. A property of Euclidean space is that distances are symmetric (the distance from object A to B is the same as the distance from B to A). In other applications (e.g., sequence-alignment methods, see Prinzie & Van den Poel (2006)), this is not the case.
[edit] Distance measure
An important step in any clustering is to select a distance measure, which will determine how the similarity of two elements is calculated. This will influence the shape of the clusters, as some elements may be close to one another according to one distance and farther away according to another. For example, in a 2-dimensional space, the distance between the point (x=1, y=0) and the origin (x=0, y=0) is always 1 according to the usual norms, but the distance between the point (x=1, y=1) and the origin can be 2,![\sqrt[2]{2}](http://upload.wikimedia.org/math/4/9/0/4909b6bd770bacde08d5a68e38665804.png) or 1 if you take respectively the 1-norm, 2-norm or infinity-norm distance.
or 1 if you take respectively the 1-norm, 2-norm or infinity-norm distance.
Common distance functions:
- The Euclidean distance (also called distance as the crow flies or 2-norm distance). A review of cluster analysis in health psychology research found that the most common distance measure in published studies in that research area is the Euclidean distance or the squared Euclidean distance.
- The Manhattan distance (also called taxicab norm or 1-norm)
- The maximum norm
- The Mahalanobis distance corrects data for different scales and correlations in the variables
- The angle between two vectors can be used as a distance measure when clustering high dimensional data. See Inner product space.
- The Hamming distance measures the minimum number of substitutions required to change one member into another.
[edit] Hierarchical clustering
[edit] Creating clusters
Hierarchical clustering builds (agglomerative), or breaks up (divisive), a hierarchy of clusters. The traditional representation of this hierarchy is a tree (called a dendrogram), with individual elements at one end and a single cluster containing every element at the other. Agglomerative algorithms begin at the leaves of the tree, whereas divisive algorithms begin at the root. (In the figure, the arrows indicate an agglomerative clustering.)
Cutting the tree at a given height will give a clustering at a selected precision. In the following example, cutting after the second row will yield clusters {a} {b c} {d e} {f}. Cutting after the third row will yield clusters {a} {b c} {d e f}, which is a coarser clustering, with a smaller number of larger clusters.
[edit] Agglomerative hierarchical clustering
For example, suppose this data is to be clustered, and the euclidean distance is the distance metric.

The hierarchical clustering dendrogram would be as such:
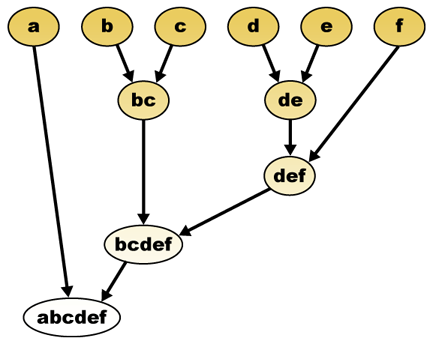
This method builds the hierarchy from the individual elements by progressively merging clusters. In our example, we have six elements {a} {b} {c} {d} {e} and {f}. The first step is to determine which elements to merge in a cluster. Usually, we want to take the two closest elements, according to the chosen distance.
Optionally, one can also construct a distance matrix at this stage, where the number in the i-th row j-th column is the distance between the i-th and j-th elements. Then, as clustering progresses, rows and columns are merged as the clusters are merged and the distances updated. This is a common way to implement this type of clustering, and has the benefit of caching distances between clusters. A simple agglomerative clustering algorithm is described in the single-linkage clustering page; it can easily be adapted to different types of linkage (see below).
Suppose we have merged the two closest elements b and c, we now have the following clusters {a}, {b, c}, {d}, {e} and {f}, and want to merge them further. To do that, we need to take the distance between {a} and {b c}, and therefore define the distance between two clusters. Usually the distance between two clusters  and
and 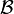 is one of the following:
is one of the following:
- The maximum distance between elements of each cluster (also called complete linkage clustering):
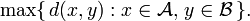
- The minimum distance between elements of each cluster (also called single-linkage clustering):
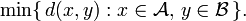
- The mean distance between elements of each cluster (also called average linkage clustering, used e.g. in UPGMA):
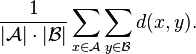
- The sum of all intra-cluster variance.
- The increase in variance for the cluster being merged (Ward's criterion).
- The probability that candidate clusters spawn from the same distribution function (V-linkage).
Each agglomeration occurs at a greater distance between clusters than the previous agglomeration, and one can decide to stop clustering either when the clusters are too far apart to be merged (distance criterion) or when there is a sufficiently small number of clusters (number criterion).
[edit] Concept clustering
Another variation of the agglomerative clustering approach is conceptual clustering.
[edit] Partitional clustering
[edit] K-means and derivatives
[edit] K-means clustering
The K-means algorithm assigns each point to the cluster whose center (also called centroid) is nearest. The center is the average of all the points in the cluster — that is, its coordinates are the arithmetic mean for each dimension separately over all the points in the cluster.
- Example: The data set has three dimensions and the cluster has two points: X = (x1, x2, x3) and Y = (y1, y2, y3). Then the centroid Z becomes Z = (z1, z2, z3), where z1 = (x1 + y1)/2 and z2 = (x2 + y2)/2 and z3 = (x3 + y3)/2.
The algorithm steps are [1]:
- Choose the number of clusters, k.
- Randomly generate k clusters and determine the cluster centers, or directly generate k random points as cluster centers.
- Assign each point to the nearest cluster center.
- Recompute the new cluster centers.
- Repeat the two previous steps until some convergence criterion is met (usually that the assignment hasn't changed).
The main advantages of this algorithm are its simplicity and speed which allows it to run on large datasets. Its disadvantage is that it does not yield the same result with each run, since the resulting clusters depend on the initial random assignments. It minimizes intra-cluster variance, but does not ensure that the result has a global minimum of variance. Another disadvantage is the requirement for the concept of a mean to be definable which is not always the case. For such datasets the k-medoids variant is appropriate.
[edit] Fuzzy c-means clustering
In fuzzy clustering, each point has a degree of belonging to clusters, as in fuzzy logic, rather than belonging completely to just one cluster. Thus, points on the edge of a cluster, may be in the cluster to a lesser degree than points in the center of cluster. For each point x we have a coefficient giving the degree of being in the kth cluster uk(x). Usually, the sum of those coefficients for any given x is defined to be 1:

With fuzzy c-means, the centroid of a cluster is the mean of all points, weighted by their degree of belonging to the cluster:

The degree of belonging is related to the inverse of the distance to the cluster center:

then the coefficients are normalized and fuzzyfied with a real parameter m > 1 so that their sum is 1. So

For m equal to 2, this is equivalent to normalising the coefficient linearly to make their sum 1. When m is close to 1, then cluster center closest to the point is given much more weight than the others, and the algorithm is similar to k-means.
The fuzzy c-means algorithm is very similar to the k-means algorithm:
- Choose a number of clusters.
- Assign randomly to each point coefficients for being in the clusters.
- Repeat until the algorithm has converged (that is, the coefficients' change between two iterations is no more than ε, the given sensitivity threshold) :
- Compute the centroid for each cluster, using the formula above.
- For each point, compute its coefficients of being in the clusters, using the formula above.
The algorithm minimizes intra-cluster variance as well, but has the same problems as k-means, the minimum is a local minimum, and the results depend on the initial choice of weights. The Expectation-maximization algorithm is a more statistically formalized method which includes some of these ideas: partial membership in classes. It has better convergence properties and is in general preferred to fuzzy-c-means.
[edit] QT clustering algorithm
QT (quality threshold) clustering (Heyer, Kruglyak, Yooseph, 1999) is an alternative method of partitioning data, invented for gene clustering. It requires more computing power than k-means, but does not require specifying the number of clusters a priori, and always returns the same result when run several times.
The algorithm is:
- The user chooses a maximum diameter for clusters.
- Build a candidate cluster for each point by including the closest point, the next closest, and so on, until the diameter of the cluster surpasses the threshold.
- Save the candidate cluster with the most points as the first true cluster, and remove all points in the cluster from further consideration. Must clarify what happens if more than 1 cluster has the maximum number of points ?
- Recurse with the reduced set of points.
The distance between a point and a group of points is computed using complete linkage, i.e. as the maximum distance from the point to any member of the group (see the "Agglomerative hierarchical clustering" section about distance between clusters).
[edit] Locality-sensitive hashing
Locality-sensitive hashing can be used for clustering. Feature space vectors are sets, and the metric used is the Jaccard distance. The feature space can be considered high-dimensional. The min-wise independent permutations LSH scheme (sometimes MinHash) is then used to put similar items into buckets. With just one set of hashing methods, there are only clusters of very similar elements. By seeding the hash functions several times (eg 20), it is possible to get bigger clusters. [2]
[edit] Graph-theoretic methods
Formal concept analysis is a technique for generating clusters of objects and attributes, given a bipartite graph representing the relations between the objects and attributes. Other methods for generating overlapping clusters (a cover rather than a partition) are discussed by Jardine and Sibson (1968) and Cole and Wishart (1970).
[edit] Determining the number of clusters
Many clustering algorithms require that you specify up front the number of clusters to find. If that number is not apparent from prior knowledge, it should be chosen in some way. Several methods for this have been suggested within the statistical literature,[3] where one rule of thumb sets the number to

with n as the number of objects (data points).

Another rule of thumb looks at the percentage of variance explained as a function of the number of clusters: You should choose a number of clusters so that adding another cluster doesn't give much better modeling of the data. More precisely, if you graph the percentage of variance explained by the clusters against the number of clusters, the first clusters will add much information (explain a lot of variance), but at some point the marginal gain will drop, giving an angle in the graph. The number of clusters are chosen at this point, hence the "elbow criterion". This "elbow" cannot always be unambiguously identified.[4] Percentage of variance explained is the ratio of the between-group variance to the total variance. A slight variation of this method plots the curvature of the within group variance.[5] The method can be traced to Robert L. Thorndike in 1953.[6]
Other ways to determine the number of clusters use Akaike information criterion (AIC) or Bayesian information criterion (BIC) — if it is possible to make a likelihood function for the clustering model. For example: The k-means model is "almost" a Gaussian mixture model and one can construct a likelihood for the Gaussian mixture model and thus also determine AIC and BIC values.[7]
The average silhouette of the data is a useful criterion for assessing the natural number of clusters. The silhouette of a datum is a measure of how closely it is matched to data within its cluster and how loosely it is matched to data of the neighbouring cluster, i.e. the cluster whose average distance from the datum is lowest[8]. A silhouette close to 1 implies the datum is in an appropriate cluster, whilst a silhouette close to − 1 implies the datum is in the wrong cluster. Optimization techniques such as genetic algorithms are useful in determining the number clusters that gives rise to the largest silhouette[9].
[edit] Spectral clustering
Given a set of data points A, the similarity matrix may be defined as a matrix S where Sij represents a measure of the similarity between points  . Spectral clustering techniques make use of the spectrum of the similarity matrix of the data to perform dimensionality reduction for clustering in fewer dimensions.
. Spectral clustering techniques make use of the spectrum of the similarity matrix of the data to perform dimensionality reduction for clustering in fewer dimensions.
One such technique is the Shi-Malik algorithm, commonly used for image segmentation. It partitions points into two sets (S1,S2) based on the eigenvector v corresponding to the second-smallest eigenvalue of the Laplacian matrix
- L = I − D − 1 / 2SD − 1 / 2
of S, where D is the diagonal matrix
-
Dii = ∑ Sij. j
This partitioning may be done in various ways, such as by taking the median m of the components in v, and placing all points whose component in v is greater than m in S1, and the rest in S2. The algorithm can be used for hierarchical clustering by repeatedly partitioning the subsets in this fashion.
A related algorithm is the Meila-Shi algorithm, which takes the eigenvectors corresponding to the k largest eigenvalues of the matrix P = SD − 1 for some k, and then invokes another (e.g. k-means) to cluster points by their respective k components in these eigenvectors.
[edit] Applications
[edit] Biology
In biology clustering has many applications
- In imaging, data clustering may take different form based on the data dimensionality. For example, the SOCR EM Mixture model segmentation activity and applet shows how to obtain point, region or volume classification using the online SOCR computational libraries.
- In the fields of plant and animal ecology, clustering is used to describe and to make spatial and temporal comparisons of communities (assemblages) of organisms in heterogeneous environments; it is also used in plant systematics to generate artificial phylogenies or clusters of organisms (individuals) at the species, genus or higher level that share a number of attributes
- In computational biology and bioinformatics:
- In transcriptomics, clustering is used to build groups of genes with related expression patterns (also known as coexpressed genes). Often such groups contain functionally related proteins, such as enzymes for a specific pathway, or genes that are co-regulated. High throughput experiments using expressed sequence tags (ESTs) or DNA microarrays can be a powerful tool for genome annotation, a general aspect of genomics.
- In sequence analysis, clustering is used to group homologous sequences into gene families. This is a very important concept in bioinformatics, and evolutionary biology in general. See evolution by gene duplication.
- In high-throughput genotyping platforms clustering algorithms are used to automatically assign genotypes.
- In QSAR and molecular modeling studies as also chemoinformatics
[edit] Medicine
In medical imaging, such as PET scans, cluster analysis can be used to differentiate between different types of tissue and blood in a three dimensional image. In this application, actual position does not matter, but the voxel intensity is considered as a vector, with a dimension for each image that was taken over time. This technique allows, for example, accurate measurement of the rate a radioactive tracer is delivered to the area of interest, without a separate sampling of arterial blood, an intrusive technique that is most common today.
[edit] Market research
Cluster analysis is widely used in market research when working with multivariate data from surveys and test panels. Market researchers use cluster analysis to partition the general population of consumers into market segments and to better understand the relationships between different groups of consumers/potential customers.
- Segmenting the market and determining target markets
- Product positioning
- New product development
- Selecting test markets (see : experimental techniques)
[edit] Other applications
- Social network analysis
- In the study of social networks, clustering may be used to recognize communities within large groups of people.
- Image segmentation
- Clustering can be used to divide a digital image into distinct regions for border detection or object recognition.
- Data mining
- Many data mining applications involve partitioning data items into related subsets; the marketing applications discussed above represent some examples. Another common application is the division of documents, such as World Wide Web pages, into genres.
- Search result grouping
- In the process of intelligent grouping of the files and websites, clustering may be used to create a more relevant set of search results compared to normal search engines like Google. There are currently a number of web based clustering tools such as Clusty.
- Slippy map optimization
- Flickr's map of photos and other map sites use clustering to reduce the number of markers on a map. This makes it both faster and reduces the amount of visual clutter.
- IMRT segmentation
- Clustering can be used to divide a fluence map into distinct regions for conversion into deliverable fields in MLC-based Radiation Therapy.
- Grouping of Shopping Items
- Clustering can be used to group all the shopping items available on the web into a set of unique products. For example, all the items on eBay can be grouped into unique products. (eBay doesn't have the concept of a SKU)
- Mathematical chemistry
- To find structural similarity, etc., for example, 3000 chemical compounds were clustered in the space of 90 topological indices.[10]
- Petroleum Geology
- Cluster Analysis is used to reconstruct missing bottom hole core data or missing log curves in order to evaluate reservoir properties.
- Fysical Geography
- The clustering of chemical properties in different sample locations.
[edit] Comparisons between data clusterings
There have been several suggestions for a measure of similarity between two clusterings. Such a measure can be used to compare how well different data clustering algorithms perform on a set of data. Many of these measures are derived from the matching matrix (aka confusion matrix), e.g., the Rand measure and the Fowlkes-Mallows Bk measures.[11] With small variations, such kind of measures also include set matching based clustering criteria, e.g., the Meila and Heckerman.
Several different clustering systems based on mutual information have been proposed. One is Marina Meila's 'Variation of Information' metric (see ref below); another provides hierarchical clustering[12].
Recently, a new Mallows Distance based metric was also proposed for soft clustering comparisons.
[edit] Algorithms
In recent years considerable effort has been put into improving algorithm performance (Z. Huang, 1998). Among the most popular are CLARANS (Ng and Han,1994), DBSCAN (Ester et al., 1996) and BIRCH (Zhang et al., 1996).
[edit] See also
- Artificial neural network (ANN)
- Canopy clustering algorithm
- Cluster-weighted modeling
- Consensus clustering
- Constrained clustering
- Cophenetic correlation
- Datamining
- Expectation maximization (EM)
- FLAME clustering
- K-means
- Multidimensional scaling
- Neighbourhood components analysis
- Self-organizing map
- Silhouette
- Structured data analysis (statistics)
[edit] Bibliography
- ^ J. MacQueen, 1967
- ^ Google News personalization: scalable online collaborative filtering
- ^ Kanti Mardia et al. (1979). Multivariate Analysis. Academic Press.
- ^ See, e.g., David J. Ketchen, Jr & Christopher L. Shook (1996). "The application of cluster analysis in Strategic Management Research: An analysis and critique". Strategic Management Journal 17 (6): 441–458. http://www3.interscience.wiley.com/cgi-bin/fulltext/17435/PDFSTART.
- ^ See, e.g., Figure 6 in
- Cyril Goutte, Peter Toft, Egill Rostrup, Finn Årup Nielsen, Lars Kai Hansen (March 1999). "On Clustering fMRI Time Series". NeuroImage 9 (3): 298–310. doi:. PMID 10075900.
- ^ Robert L. Thorndike (December 1953). "Who Belong in the Family?". Psychometrika 18 (4).
- ^ Cyril Goutte, Lars Kai Hansen, Matthew G. Liptrot & Egill Rostrup (2001). "Feature-Space Clustering for fMRI Meta-Analysis". Human Brain Mapping 13 (3): 165–183. http://www3.interscience.wiley.com/cgi-bin/fulltext/82002382/. see especially Figure 14 and appendix.
- ^ Peter J. Rousseuw (1987). "Silhouettes: a Graphical Aid to the Interpretation and Validation of Cluster Analysis". Computational and Applied Mathematics 20: 53–65.
- ^ R. Lleti, M.C. Ortiz, L.A. Sarabia, M.S. Sánchez (2004). "Selecting Variables for k-Means Cluster Analysis by Using a Genetic Algorithm that Optimises the Silhouettes". Analytica Chimica Acta 515: 87–100.
- ^ Basak S.C., Magnuson V.R., Niemi C.J., Regal R.R. "Determing Structural Similarity of Chemicals Using Graph Theoretic Indices". Discr. Appl. Math., 19, 1988: 17-44.
- ^ E. B. Fowlkes & C. L. Mallows (September 1983). "A Method for Comparing Two Hierarchical Clusterings". Journal of the American Statistical Association 78 (383): 553–584. doi:.
- ^ Alexander Kraskov, Harald Stögbauer, Ralph G. Andrzejak, and Peter Grassberger, "Hierarchical Clustering Based on Mutual Information", (2003) ArXiv q-bio/0311039
[edit] Others
- Clatworthy, J., Buick, D., Hankins, M., Weinman, J., & Horne, R. (2005). The use and reporting of cluster analysis in health psychology: A review. British Journal of Health Psychology 10: 329-358.
- Cole, A. J. & Wishart, D. (1970). An improved algorithm for the Jardine-Sibson method of generating overlapping clusters. The Computer Journal 13(2):156-163.
- Ester, M., Kriegel, H.P., Sander, J., and Xu, X. 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, Oregon, USA: AAAI Press, pp. 226–231.
- Heyer, L.J., Kruglyak, S. and Yooseph, S., Exploring Expression Data: Identification and Analysis of Coexpressed Genes, Genome Research 9:1106-1115.
- S. Kotsiantis, P. Pintelas, Recent Advances in Clustering: A Brief Survey, WSEAS Transactions on Information Science and Applications, Vol 1, No 1 (73-81), 2004.
- Huang, Z. (1998). Extensions to the K-means Algorithm for Clustering Large Datasets with Categorical Values. Data Mining and Knowledge Discovery, 2, p. 283-304.
- Jardine, N. & Sibson, R. (1968). The construction of hierarchic and non-hierarchic classifications. The Computer Journal 11:177.
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay includes chapters on k-means clustering, soft k-means clustering, and derivations including the E-M algorithm and the variational view of the E-M algorithm.
- MacQueen, J. B. (1967). Some Methods for classification and Analysis of Multivariate Observations, Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, University of California Press, 1:281-297
- Ng, R.T. and Han, J. 1994. Efficient and effective clustering methods for spatial data mining. Proceedings of the 20th VLDB Conference, Santiago, Chile, pp. 144–155.
- Prinzie A., D. Van den Poel (2006), Incorporating sequential information into traditional classification models by using an element/position-sensitive SAM. Decision Support Systems 42 (2): 508-526.
- Romesburg, H. Clarles, Cluster Analysis for Researchers, 2004, 340 pp. ISBN 1-4116-0617-5, reprint of 1990 edition published by Krieger Pub. Co... A Japanese language translation is available from Uchida Rokakuho Publishing Co., Ltd., Tokyo, Japan.
- Sheppard, A. G. (1996). The sequence of factor analysis and cluster analysis: Differences in segmentation and dimensionality through the use of raw and factor scores. Tourism Analysis, 1(Inaugural Volume), 49-57.
- Zhang, T., Ramakrishnan, R., and Livny, M. 1996. BIRCH: An efficient data clustering method for very large databases. Proceedings of ACM SIGMOD Conference, Montreal, Canada, pp. 103–114.
For spectral clustering:
- Jianbo Shi and Jitendra Malik, "Normalized Cuts and Image Segmentation", IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8), 888-905, August 2000. Available on Jitendra Malik's homepage
- Marina Meila and Jianbo Shi, "Learning Segmentation with Random Walk", Neural Information Processing Systems, NIPS, 2001. Available from Jianbo Shi's homepage
- see referenced articles here
For estimating number of clusters:
- I. O. Kyrgyzov, O. O. Kyrgyzov, H. Maître and M. Campedel. Kernel MDL to Determine the Number of Clusters, MLDM, pp. 203-217, 2007.
- Stan Salvador and Philip Chan, Determining the Number of Clusters/Segments in Hierarchical Clustering/Segmentation Algorithms, Proc. 16th IEEE Intl. Conf. on Tools with AI, pp. 576-584, 2004.
- Can, F., Ozkarahan, E. A. (1990) "Concepts and effectiveness of the cover coefficient-based clustering methodology for text databases." ACM Transactions on Database Systems. 15 (4) 483-517.
For discussion of the elbow criterion:
- Aldenderfer, M.S., Blashfield, R.K, Cluster Analysis, (1984), Newbury Park (CA): Sage.
[edit] External links
|
|
This article's external links may not follow Wikipedia's content policies or guidelines. Please improve this article by removing excessive or inappropriate external links. |
- COMPACT - Comparative Package for Clustering Assessment. A free Matlab package, 2006.
- P. Berkhin, Survey of Clustering Data Mining Techniques, Accrue Software, 2002.
- Jain, Murty and Flynn: Data Clustering: A Review, ACM Comp. Surv., 1999.
- Clustering web documents using PHP
- for another presentation of hierarchical, k-means and fuzzy c-means see this introduction to clustering. Also has an explanation on mixture of Gaussians.
- David Dowe, Mixture Modelling page - other clustering and mixture model links.
- A tutorial on clustering [1]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay includes chapters on k-means clustering, soft k-means clustering, and derivations including the E-M algorithm and the variational view of the E-M algorithm.
- Numerical example of Hierarchical Clustering
- kernlab - R package for kernel based machine learning (includes spectral clustering implementation)
- Tutorial - Tutorial with introduction of Clustering Algorithms (k-means, fuzzy-c-means, hierarchical, mixture of gaussians) + some interactive demos (java applets)
- Data Mining Software at the Open Directory Project
- Java Competitive Learning Application A suite of Unsupervised Neural Networks for clustering. Written in Java. Complete with all source code.
- Machine Learning Software - Also contains much clustering software.
- Cluster Computing and MapReduce Lecture 4
- FactoMineR (free exploratory multivariate data analysis software linked to R)
- The Journal of Classification. A publication of the Classification Society of North America that specializes on the mathematical and statistical theory of cluster analysis.
- Data clustering algorithms implementation in Ruby (AI4R)

