Regular language
From Wikipedia, the free encyclopedia
In theoretical computer science, a regular language is a formal language (i.e., a possibly infinite set of finite sequences of symbols from a finite alphabet) that satisfies the following equivalent properties:
- it can be accepted by a deterministic finite state machine
- it can be accepted by a nondeterministic finite state machine
- it can be accepted by an alternating finite automaton
- it can be described by a formal regular expression. Note that the "regular expression" features provided with many programming languages are augmented with features that make them capable of recognizing languages which are not regular, and are therefore not strictly equivalent to formal regular expressions.
- it can be generated by a regular grammar
- it can be generated by a prefix grammar
- it can be accepted by a read-only Turing machine
- it can be defined in monadic second-order logic
- it is recognized by some finitely generated monoid
- it is the preimage of a subset of a finite monoid under a homomorphism from the free monoid on its alphabet
Contents |
[edit] Regular languages over an alphabet
The collection of regular languages over an alphabet Σ is defined recursively as follows:
- the empty language Ø is a regular language.
- the empty string language { ε } is a regular language.
- For each a ∈ Σ (belongs to), the singleton language { a } is a regular language.
- If A and B are regular languages, then A ∪ B (union), A • B (concatenation), and A* (Kleene star) are regular languages.
- No other languages over Σ are regular.
All finite languages are regular. Other typical examples include the language consisting of all strings over the alphabet {a, b} which contain an even number of as, or the language consisting of all strings of the form: several as followed by several bs.
A simple example of a language that is not regular is the set of strings  . Some additional examples are given below.
. Some additional examples are given below.
[edit] Complexity results
In computational complexity theory, the complexity class of all regular languages is sometimes referred to as REGULAR or REG and equals DSPACE(O(1)), the decision problems that can be solved in constant space (the space used is independent of the input size). REGULAR ≠ AC0, since it (trivially) contains the parity problem of determining whether the number of 1 bits in the input is even or odd and this problem is not in AC0.[1] On the other hand, it is not known to contain AC0.
If a language is not regular, it requires a machine with at least Ω(log log n) space to recognize (where n is the input size).[2] In other words, DSPACE(o(log log n)) equals the class of regular languages. In practice, most nonregular problems are solved by machines taking at least logarithmic space.
[edit] Closure properties
The regular languages are closed under the following operations: That is, if L and P are regular languages, the following languages are regular as well:
- the complement
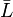 of L
of L - the Kleene star L * of L
- the image φ(L) of L under a string homomorphism
- the concatenation
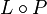 of L and P
of L and P - the union
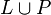 of L and P
of L and P - the intersection
 of L and P
of L and P - the difference L − P of L and P
- the reverse LR of L
[edit] Deciding whether a language is regular
To locate the regular languages in the Chomsky hierarchy, one notices that every regular language is context-free. The converse is not true: for example the language consisting of all strings having the same number of a's as b's is context-free but not regular. To prove that a language such as this is not regular, one uses the Myhill-Nerode theorem or the pumping lemma.
There are two purely algebraic approaches to define regular languages. If Σ is a finite alphabet and Σ* denotes the free monoid over Σ consisting of all strings over Σ, f : Σ* → M is a monoid homomorphism where M is a finite monoid, and S is a subset of M, then the set f −1(S) is regular. Every regular language arises in this fashion.
If L is any subset of Σ*, one defines an equivalence relation ~ (called the syntactic relation) on Σ* as follows: u ~ v is defined to mean
- uw ∈ L if and only if vw ∈ L for all w ∈ Σ*
The language L is regular if and only if the number of equivalence classes of ~ is finite (A proof of this is provided in the article on the syntactic monoid). When a language is regular, then the number of equivalence classes is equal to the number of states of the minimal deterministic finite automaton accepting L.
A similar set of statements can be formulated for a monoid  . In this case, equivalence over M leads to the concept of a recognizable language.
. In this case, equivalence over M leads to the concept of a recognizable language.
[edit] Finite languages
A specific subset within the class of regular languages is the finite languages – those containing only a finite number of words. These are obviously regular as one can create a regular expression that is the union of every word in the language, and thus are regular.
[edit] See also
[edit] References
|
|
This article may require cleanup to meet Wikipedia's quality standards. Please improve this article if you can. (December 2008) |
- Michael Sipser (1997). Introduction to the Theory of Computation. PWS Publishing. ISBN 0-534-94728-X. Chapter 1: Regular Languages, pp.31–90. Subsection "Decidable Problems Concerning Regular Languages" of section 4.1: Decidable Languages, pp.152–155.
- ^ M. Furst, J. B. Saxe, and M. Sipser. Parity, circuits, and the polynomial-time hierarchy. Math. Systems Theory, 17:13–27, 1984.
- ^ J. Hartmanis, P. L. Lewis II, and R. E. Stearns. Hierarchies of memory-limited computations. Proceedings of the 6th Annual IEEE Symposium on Switching Circuit Theory and Logic Design, pp. 179–190. 1965.
[edit] External links
|
||||||||||||||||||||||||||||||||||||||||||||||||

