Power law
From Wikipedia, the free encyclopedia

A power law is a special kind of mathematical relationship between two quantities. If one quantity is the frequency of an event, the relationship is a power-law distribution, and the frequencies decrease very slowly as the size of the event increases. For instance, an earthquake twice as large is four times as rare. If this pattern holds for earthquakes of all sizes, then the distribution is said to "scale". Power laws also describe other kinds of relationships, such as the metabolic rate of a species and its body mass (called Kleiber's law), and the size of a city and the number of patents it produces. What this relationship means is that there is no typical size in the conventional sense. Power laws are found throughout the natural and manmade worlds, and are an active area of scientific research.
Contents |
[edit] Technical definition
A power law is any polynomial relationship that exhibits the property of scale invariance. The most common power laws relate two variables and have the form

where a and k are constants, and o(xk) is an asymptotically small function of x. Here, k is typically called the scaling exponent, where the word "scaling" denotes the fact that a power-law function satisfies 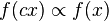 where c is a constant. Thus, a rescaling of the function's argument changes the constant of proportionality but preserves the shape of the function itself. This point becomes clearer if we take the logarithm of both sides:
where c is a constant. Thus, a rescaling of the function's argument changes the constant of proportionality but preserves the shape of the function itself. This point becomes clearer if we take the logarithm of both sides:
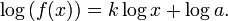
Notice that this expression has the form of a linear relationship with slope k. Rescaling the argument produces a linear shift of the function up or down but leaves both the basic form and the slope k unchanged.
Power-law relations characterize a staggering number of naturally occurring phenomena, and this is one of the principal reasons why they have attracted such wide interest. For instance, inverse-square laws, such as gravitation and the Coulomb force, are power laws, as are many common mathematical formulae such as the quadratic law of area of the circle. However much of the recent interest in power laws comes from the study of probability distributions: it's now known that the distributions of a wide variety of quantities seem to follow the power-law form, at least in their upper tail (large events). The behavior of these large events connects these quantities to the study of theory of large deviations (also called extreme value theory), which considers the frequency of extremely rare events like stock market crashes and large natural disasters. It is primarily in the study of statistical distributions that the name "power law" is used; in other areas the power-law functional form is more often referred to simply as a polynomial form or polynomial function.
Scientific interest in power law relations stems partly from the ease with which certain general classes of mechanisms generate them. The demonstration of a power-law relation in some data can point to specific kinds of mechanisms that might underlie the natural phenomenon in question, and can indicate a deep connection with other, seemingly unrelated systems (see the reference by Simon and the subsection on universality below). The ubiquity of power-law relations in physics is partly due to dimensional constraints, while in complex systems, power laws are often thought to be signatures of hierarchy or of specific stochastic processes. A few notable examples of power laws are the Gutenberg-Richter law for earthquake sizes, Pareto's law of income distribution, structural self-similarity of fractals, and scaling laws in biological systems. Research on the origins of power-law relations, and efforts to observe and validate them in the real world, is an active topic of research in many fields of science, including physics, computer science, linguistics, geophysics, sociology, economics and more.
[edit] Properties of power laws
[edit] Scale invariance
The main property of power laws that makes them interesting is their scale invariance. Given a relation f(x) = axk, or, indeed any homogeneous polynomial, scaling the argument x by a constant factor causes only a proportionate scaling of the function itself. That is,

That is, scaling by a constant simply multiplies the original power-law relation by the constant ck. Thus, it follows that all power laws with a particular scaling exponent are equivalent up to constant factors, since each is simply a scaled version of the others. This behavior is what produces the linear relationship when both logarithms are taken of both f(x) and x, and the straight-line on the log-log plot is often called the signature of a power law. Notably, however, with real data, such straightness is necessary, but not a sufficient condition for the data following a power-law relation. In fact, there are many ways to generate finite amounts of data that mimic this signature behavior, but, in their asymptotic limit, are not true power laws. Thus, accurately fitting and validating power-law models is an active area of research in statistics.
[edit] Universality
The equivalence of power laws with a particular scaling exponent can have a deeper origin in the dynamical processes that generate the power-law relation. In physics, for example, phase transitions in thermodynamic systems are associated with the emergence of power-law distributions of certain quantities, whose exponents are referred to as the critical exponents of the system. Diverse systems with the same critical exponents — that is, which display identical scaling behaviour as they approach criticality — can be shown, via renormalization group theory, to share the same fundamental dynamics. For instance, the behavior of water and CO2 at their boiling points fall in the same universality class because they have identical critical exponents. In fact, almost all material phase transitions are described by a small set of universality classes. Similar observations have been made, though not as comprehensively, for various self-organized critical systems, where the critical point of the system is an attractor. Formally, this sharing of dynamics is referred to as universality, and systems with precisely the same critical exponents are said to belong to the same universality class.
[edit] Power-law functions
The general power-law function follows the polynomial form given above, and is a ubiquitous form throughout mathematics and science. Notably, however, not all polynomial functions are power laws because not all polynomials exhibit the property of scale invariance. Typically, power-law functions are polynomials in a single variable, and are explicitly used to model the scaling behavior of natural processes. For instance, allometric scaling laws for the relation of biological variables are some of the best known power-law functions in nature. In this context, the o(xk) term is most typically replaced by a deviation term ε, which can represent uncertainty in the observed values (perhaps measurement or sampling errors) or provide a simple way for observations to deviate from the no power-law function (perhaps for stochastic reasons):
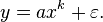
[edit] Examples of power law functions
- The Stefan-Boltzmann law
- The Gompertz Law of Mortality
- The Ramberg-Osgood stress-strain relationship
- The Inverse-square law of Newtonian gravity
- The Initial mass function
- Gamma correction relating light intensity with voltage
- Kleiber's law relating animal metabolism to size, and allometric laws in general
- Behaviour near second-order phase transitions involving critical exponents
- Proposed form of experience curve effects
- The differential energy spectrum of cosmic-ray nuclei
- Inverse-square law
- Square-cube law
- Constructal law
- Fractals
- The "80-20 rule", or Pareto principle
- Zipf's Law of city-size distributions (a city's population is proportional to its rank in population)
[edit] Power-law distributions
A power-law distribution is any that, in the most general sense, has the form

where α > 1, and L(x) is a slowly varying function, which is any function that satisfies 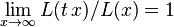 with t constant. This property of L(x) follows directly from the requirement that p(x) be asymptotically scale invariant; thus, the form of L(x) only controls the shape and finite extent of the lower tail. For instance, if L(x) is the constant function, then we have a power-law that holds for all values of x. In many cases, it is convenient to assume a lower bound xmin from which the law holds. Combining these two cases, and where x is a continuous variable, the power law has the form
with t constant. This property of L(x) follows directly from the requirement that p(x) be asymptotically scale invariant; thus, the form of L(x) only controls the shape and finite extent of the lower tail. For instance, if L(x) is the constant function, then we have a power-law that holds for all values of x. In many cases, it is convenient to assume a lower bound xmin from which the law holds. Combining these two cases, and where x is a continuous variable, the power law has the form
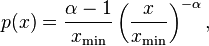
where the pre-factor to x − α is the normalizing constant. We can now consider several properties of this distribution. For instance, its moments are given by

which is only well defined for m < α − 1. That is, all moments  diverge: when α < 2, the average and all higher-order moments are infinite; when 2 < α < 3, the mean exists, but the variance and higher-order moments are infinite, etc. For finite-size samples drawn from such distribution, this behavior implies that the central moment estimators (like the mean and the variance) for diverging moments will never converge - as more data is accumulated, they continue to grow.
diverge: when α < 2, the average and all higher-order moments are infinite; when 2 < α < 3, the mean exists, but the variance and higher-order moments are infinite, etc. For finite-size samples drawn from such distribution, this behavior implies that the central moment estimators (like the mean and the variance) for diverging moments will never converge - as more data is accumulated, they continue to grow.
Another kind of power-law distribution, which does not satisfy the general form above, is the power law with an exponential cutoff

In this distribution, the exponential decay term e − λx eventually overwhelms the power-law behavior at very large values of x. This distribution does not scale and is thus not asymptotically a power law; however, it does approximately scale over a finite region before the cutoff. (Note that the pure form above is a subset of this family, with λ = 0.) This distribution is a common alternative to the asymptotic power-law distribution because it naturally captures finite-size effects. For instance, although the Gutenberg-Richter Law is commonly cited as an example of a power-law distribution, the distribution of earthquake magnitudes cannot scale as a power law in the limit 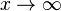 because there is a finite amount of energy in the Earth's crust and thus there must be some maximum size to an earthquake. As the scaling behavior approaches this size, it must taper off.
because there is a finite amount of energy in the Earth's crust and thus there must be some maximum size to an earthquake. As the scaling behavior approaches this size, it must taper off.
[edit] Plotting power-law distributions
In general, power-law distributions are plotted on doubly logarithmic axes, which emphasizes the upper tail region. The most convenient way to do this is via the (complementary) cumulative distribution (cdf), P(x) = Pr(X > x),

Note that the cdf is also a power-law function, but with a smaller scaling exponent. For data, an equivalent form of the cdf is the rank-frequency approach, in which we first sort the n observed values in ascending order, and plot them against the vector ![\left[1,\frac{n-1}{n},\frac{n-2}{n},\dots,\frac{1}{n}\right]](http://upload.wikimedia.org/math/b/c/6/bc687c349e1bc9bd909b7e3a33a4aa33.png) .
.
Although it can be convenient to log-bin the data, or otherwise smooth the probability density (mass) function directly, these methods introduce an implicit bias in the representation of the data, and thus should be avoided. The cdf, on the other hand, introduces no bias in the data and preserves the linear signature on doubly logarithmic axes.
[edit] Estimating the exponent from empirical data
There are many ways of estimating the value of the scaling exponent for a power-law tail, however not all of them yield unbiased and consistent answers. The most reliable techniques are often based on the method of maximum likelihood. Alternative methods are often based on making a linear regression on either the log-log probability, the log-log cumulative distribution function, or on log-binned data, but these approaches should be avoided as they can all lead to highly biased estimates of the scaling exponent (see the Clauset et al. reference below).
For real-valued data, we fit a power-law distribution of the form
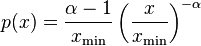
to the data 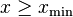 . Given a choice for xmin, a simple derivation by this method yields the estimator equation
. Given a choice for xmin, a simple derivation by this method yields the estimator equation
![\hat{\alpha} = 1 + n \left[ \sum_{i=1}^{n} \ln \frac{x_i}{x_\min} \right]^{-1}](http://upload.wikimedia.org/math/1/a/2/1a2cb17a0fb879e88f009ff9da9ce9bf.png)
where {xi} are the n data points  . (For a more detailed derivation, see Hall or Newman below.) This estimator exhibits a small finite sample-size bias of order O(n − 1), which is small when n > 100. Further, the uncertainty in the estimation can be derived from the maximum likelihood argument, and has the form
. (For a more detailed derivation, see Hall or Newman below.) This estimator exhibits a small finite sample-size bias of order O(n − 1), which is small when n > 100. Further, the uncertainty in the estimation can be derived from the maximum likelihood argument, and has the form  . This estimator is equivalent to the popular Hill estimator from quantitative finance and extreme value theory.
. This estimator is equivalent to the popular Hill estimator from quantitative finance and extreme value theory.
For a set of n integer-valued data points {xi}, again where each 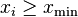 , the maximum likelihood exponent is the solution to the transcendental equation
, the maximum likelihood exponent is the solution to the transcendental equation
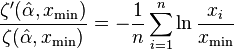
where ζ(α,xmin) is the incomplete zeta function. The uncertainty in this estimate follows the same formula as for the continuous equation. However, the two equations for 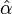 are not equivalent, and the continuous version should not be applied to discrete data, nor vice versa.
are not equivalent, and the continuous version should not be applied to discrete data, nor vice versa.
Further, both of these estimators require the choice of xmin. For functions with a non-trivial L(x) function, choosing xmin too small produces a significant bias in 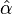 , while choosing it too large increases the uncertainty in , and reduces the statistical power of our model. In general, the best choice of xmin depends strongly on the particular form of the lower tail, represented by L(x) above.
, while choosing it too large increases the uncertainty in , and reduces the statistical power of our model. In general, the best choice of xmin depends strongly on the particular form of the lower tail, represented by L(x) above.
More about these methods, and the conditions under which they can be used, can be found in the Clauset et al. reference below. Further, this comprehensive review article provides usable code (Matlab and R) for estimation and testing routines for power-law distributions.
[edit] Examples of power-law distributions
- Pareto distribution (continuous)
- Zeta distribution (discrete)
- Yule–Simon distribution (discrete)
- Student's t-distribution (continuous), of which the Cauchy distribution is a special case
- Zipf's law and its generalization, the Zipf-Mandelbrot law (discrete)
- The scale-free network model
- Bibliograms
- Gutenberg-Richter law of earthquake magnitudes
- Horton's laws describing river systems
- Richardson's Law for the severity of violent conflicts (wars and terrorism)
- population of cities
- numbers of religious adherents
- net worth of individuals
- frequency of words in a text
A great many power-law distributions have been conjectured in recent years. For instance, power laws are thought to characterize the behavior of the upper tails for the popularity of websites, number of species per genus, the popularity of given names, the size of financial returns, and many others. However, much debate remains as to which of these tails are actually power-law distributed and which are not. For instance, it is commonly accepted now that the famous Gutenberg-Richter Law decays more rapidly than a pure power-law tail because of a finite exponential cutoff in the upper tail.
[edit] Validating power laws
Although power-law relations are attractive for many theoretical reasons, demonstrating that data do indeed follow a power-law relation requires more than simply fitting such a model to the data. In general, many alternative functional forms can appear to follow a power-law form for some extent. Thus, the preferred method for validation of power-law relations is by testing many orthogonal predictions of a particular generative mechanism against data, and not simply fitting a power-law relation to a particular kind of data. As such, the validation of power-law claims remains a very active field of research in many areas of modern science.
[edit] Notes
[edit] See also
|
|
The length of this "see also" section may adversely affect readability. Please ensure that the "see also" links are not mentioned elsewhere in the article, are not red links, are as few in number and as relevant as possible. |
[edit] Bibliography
- Simon, H. A. (1955). "On a Class of Skew Distribution Functions". Biometrika 42: 425–440. doi:. http://links.jstor.org/sici?sici=0006-3444%28195512%2942%3A3%2F4%3C425%3AOACOSD%3E2.0.CO%3B2-M.
- Hall, P. (1982). "On Some Simple Estimates of an Exponent of Regular Variation". Journal of the Royal Statistical Society, Series B (Methodological) 44 (1): 37–42. http://links.jstor.org/sici?sici=0035-9246(1982)44%3A1%3C37%3AOSSEOA%3E2.0.CO%3B2-4.
- Mitzenmacher, M. (2003). "A brief history of generative models for power law and lognormal distributions". Internet Mathematics 1: 226–251. http://www.internetmathematics.org/volumes/1/2/pp226_251.pdf.
- Newman, M. E. J. (2005). "Power laws, Pareto distributions and Zipf's law". Contemporary Physics 46: 323–351. doi:. http://www.journalsonline.tandf.co.uk/openurl.asp?genre=article&doi=10.1080/00107510500052444.
- Clauset, A., Shalizi, C. R. and Newman, M. E. J. (2007). Power-law distributions in empirical data. http://arxiv.org/abs/0706.1062.
- Ubiquity Mark Buchanan (2000) Wiedenfield & Nicholson ISBN 0 297 64376 2
[edit] External links
- Zipf's law
- Power laws, Pareto distributions and Zipf's law
- Zipf, Power-laws, and Pareto - a ranking tutorial
- Gutenberg-Richter Law
- Stream Morphometry and Horton's Laws
- Clay Shirky on Institutions & Collaboration: Power law in relation to the internet-based social networks
- Clay Shirky on Power Laws, Weblogs, and Inequality
- "How the Finance Gurus Get Risk All Wrong" by Benoit Mandelbrot & Nassim Nicholas Taleb. Fortune, July 11, 2005.
- "Million-dollar Murray": power-law distributions in homelessness and other social problems; by Malcolm Gladwell. The New Yorker, February 13, 2006.
- Benoit Mandelbrot & Richard Hudson: The Misbehaviour of Markets (2004)
- Philip Ball: Critical Mass: How one thing leads to another (2005)
- Tyranny of the Power Law from The Econophysics Blog

