Analysis of variance
From Wikipedia, the free encyclopedia
In statistics, analysis of variance (ANOVA) is a collection of statistical models, and their associated procedures, in which the observed variance is partitioned into components due to different explanatory variables. The initial techniques of the analysis of variance were developed by the statistician and geneticist R. A. Fisher in the 1920s and 1930s, and is sometimes known as Fisher's ANOVA or Fisher's analysis of variance, due to the use of Fisher's F-distribution as part of the test of statistical significance.
Contents |
[edit] Overview
There are three conceptual classes of such models:
- Fixed-effects models assumes that the data came from normal populations which may differ only in their means. (Model 1)
- Random effects models assume that the data describe a hierarchy of different populations whose differences are constrained by the hierarchy. (Model 2)
- Mixed-effect models describe situations where both fixed and random effects are present. (Model 3)
In practice, there are several types of ANOVA depending on the number of treatments and the way they are applied to the subjects in the experiment:
- One-way ANOVA is used to test for differences among two or more independent groups. Typically, however, the one-way ANOVA is used to test for differences among at least three groups, since the two-group case can be covered by a T-test (Gossett, 1908). When there are only two means to compare, the T-test and the F-test are equivalent; the relation between ANOVA and t is given by F = t2.
- One-way ANOVA for repeated measures is used when the subjects are subjected to repeated measures; this means that the same subjects are used for each treatment. Note that this method can be subject to carryover effects.
- Factorial ANOVA is used when the experimenter wants to study the effects of two or more treatment variables. The most commonly used type of factorial ANOVA is the 2×2 (read: two by two) design, where there are two independent variables and each variable has two levels or distinct values. Factorial ANOVA can also be multi-level such as 3×3, etc. or higher order such as 2×2×2, etc. but analyses with higher numbers of factors are rarely done by hand because the calculations are lengthy and the results are hard to interpret. However, since the introduction of data analytic software, the utilization of higher order designs and analyses has become quite common.
- When one wishes to test two or more independent groups subjecting the subjects to repeated measures, one may perform a factorial mixed-design ANOVA, in which one factor is a between-subjects variable and the other is within-subjects variable. This is a type of mixed-effect model.
- Multivariate analysis of variance (MANOVA) is used when there is more than one dependent variable.
[edit] Models
[edit] Fixed-effects models
The fixed-effects model of analysis of variance applies to situations in which the experimenter applies several treatments to the subjects of the experiment to see if the response variable values change. This allows the experimenter to estimate the ranges of response variable values that the treatment would generate in the population as a whole.
[edit] Random-effects models
Random effects models are used when the treatments are not fixed. This occurs when the various treatments (also known as factor levels) are sampled from a larger population. Because the treatments themselves are random variables, some assumptions and the method of contrasting the treatments differ from ANOVA model 1.
Most random-effects or mixed-effects models are not concerned with making inferences concerning the particular sampled factors. For example, consider a large manufacturing plant in which many machines produce the same product. The statistician studying this plant would have very little interest in comparing the three particular machines to each other. Rather, inferences that can be made for all machines are of interest, such as their variability and the overall mean.
[edit] Assumptions
- Independence of cases - this is a requirement of the design.
- Normality - the distributions in each of the groups are normal.
- Equality (or "homogeneity") of variances, called homoscedasticity — the variance of data in groups should be the same.
Levene's test for homogeneity of variances is typically used to confirm homoscedasticity. The Kolmogorov-Smirnov or the Shapiro-Wilk test may be used to confirm normality. Some authors claim that the F-test is unreliable if there are deviations from normality (Lindman, 1974) while others claim that the F-test is robust (Ferguson & Takane, 2005, pp.261-2). The Kruskal-Wallis test is a nonparametric alternative which does not rely on an assumption of normality.
These together form the common assumption that the errors are independently, identically, and normally distributed for fixed effects models, or:
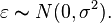
[edit] Logic of ANOVA
[edit] Partitioning of the sum of squares
The fundamental technique is a partitioning of the total sum of squares (abbreviated SS) into components related to the effects used in the model. For example, we show the model for a simplified ANOVA with one type of treatment at different levels.

The number of degrees of freedom (abbreviated df) can be partitioned in a similar way and specifies the chi-square distribution which describes the associated sums of squares.
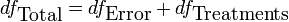
See also Lack-of-fit sum of squares.
[edit] The F-test
The F-test is used for comparisons of the components of the total deviation. For example, in one-way, or single-factor ANOVA, statistical significance is tested for by comparing the F test statistic
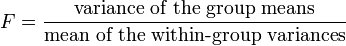
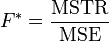
where:
 , I = number of treatments
, I = number of treatments
and
 , nT = total number of cases
, nT = total number of cases
to the F-distribution with I-1,nT degrees of freedom. Using the F-distribution is a natural candidate because the test statistic is the quotient of two mean sums of squares which have a chi-square distribution.
[edit] ANOVA on ranks
As first suggested by Conover and Iman in 1981, in many cases when the data do not meet the assumptions of ANOVA, one can replace each original data value by its rank from 1 for the smallest to N for the largest, then run a standard ANOVA calculation on the rank-transformed data. "Where no equivalent nonparametric methods have yet been developed such as for the two-way design, rank transformation results in tests which are more robust to non-normality, and resistant to outliers and non-constant variance, than is ANOVA without the transformation." (Helsel & Hirsch, 2002, Page 177). However Seaman et al. (1994) noticed that the rank transformation of Conover and Iman (1981) is not appropriate for testing interactions among effects in a factorial design as it can cause an increase in Type I error (alpha error). Furthermore, if both main factors are significant there is little power to detect interactions.
A variant of rank-transformation is 'quantile normalization' in which a further transformation is applied to the ranks such that the resulting values have some defined distribution (often a normal distribution with a specified mean and variance). Further analyses of quantile-normalized data may then assume that distribution to compute significance values.
- Conover, W. J. & Iman, R. L. (1981). Rank transformations as a bridge between parametric and nonparametric statistics. American Statistician, 35, 124-129. [1] [2]
- Helsel, D. R., & Hirsch, R. M. (2002). Statistical Methods in Water Resources: Techniques of Water Resourses Investigations, Book 4, chapter A3. U.S. Geological Survey. 522 pages.[3]
- Seaman, J. W., Walls, S. C., Wide, S. E., & Jaeger, R. G. (1994). Caveat emptor: Rank transform methods and interactions. Trends Ecol. Evol., 9, 261-263.
[edit] Effect size measures
Several standardised measures of effect are used within the context of ANOVA to describe the degree of relationship between a predictor or set of predictors and the dependent variable.
partial η2 ( Partial eta-squared ): Partial eta-squared describes the percentage of variance explained in the dependent variable by a predictor controlling for other predictors. It is a biased estimate of the variance explained in the population. The following rules of thumb have emerged: small = 0.01; medium = 0.06; large = 0.14 These rules were taken from: Kittler, J. E., Menard, W., & Phillips, K., A. (2007). Weight concerns in individuals with body dysmorphic disorder. Eating Behaviors, 8, 115-120. Since this ranking of effect size has been repeated from Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: Lawrence Earlbaum Associates with no change or comment over the years their validity is questionable outside of psychological/behavioral studies and questionable even then without a full understanding of the limitations ascribed by Cohen. The use of specific partial eta-square values for large medium or small as a "rule of thumb" should be avoided.
Omega Squared Omega squared provides a relatively unbiased estimate of the variance explained in the population by a predictor variable.
Cohen's f This measure of effect size is frequently encountered when performing power analysis calculations. Conceptually it represents the square root of variance explained over variance not explained.
[edit] Follow up tests
A statistically significant effect in ANOVA is often followed up with one or more different follow-up tests. This can be done in order to assess which groups are different from which other groups or to test various other focused hypotheses. Follow up tests are often distinguished in terms of whether they are planned (a priori) or post hoc. Planned tests are determined before looking at the data and post hoc tests are performed after looking at the data. Post hoc tests such as Tukey's test most commonly compare every group mean with every other group mean and typically incorporate some method of controlling of Type I errors. Comparisons, which are most commonly planned, can be either simple or compound. Simple comparisons compare one group mean with one other group mean. Compound comparisons typically compare two sets of groups means where one set has at two or more groups (e.g., compare average group means of group A, B and C with group D). Comparisons can also look at tests of trend, such as linear and quadratic relationships, when the independent variable involves ordered levels.
[edit] Power analysis
Power analysis is often applied in the context of ANOVA in order to assess the probability of successfully rejecting the null hypothesis if we assume a certain ANOVA design, effect size in the population, sample size and alpha level. Power analysis can assist in study design by determining what sample size would be required in order to have a reasonable chance of rejecting the null hypothesis.
[edit] Examples
Group A is given vodka, Group B is given gin, and Group C is given a placebo. All groups are then tested with a memory task. A one-way ANOVA can be used to assess the effect of the various treatments (that is, the vodka, gin, and placebo).
Group A is given vodka and tested on a memory task. The same group is allowed a rest period of five days and then the experiment is repeated with gin. The procedure is repeated using a placebo. A one-way ANOVA with repeated measures can be used to assess the effect of the vodka versus the impact of the placebo.
In an experiment testing the effects of expectations, subjects are randomly assigned to four groups:
- expect vodka—receive vodka
- expect vodka—receive placebo
- expect placebo—receive vodka
- expect placebo—receive placebo (the last group is used as the control group)
Each group is then tested on a memory task. The advantage of this design is that multiple variables can be tested at the same time instead of running two different experiments. Also, the experiment can determine whether one variable affects the other variable (known as interaction effects). A factorial ANOVA (2×2) can be used to assess the effect of expecting vodka or the placebo and the actual reception of either.
[edit] History
Ronald Fisher first used variance in his 1918 paper The Correlation Between Relatives on the Supposition of Mendelian Inheritance[1]. His first application of the analysis of variance was published in 1921[2]. Analysis of variance became widely known after being included in Fisher's 1925 book Statistical Methods for Research Workers.
[edit] See also
| Wikiversity has learning materials about Analysis of variance |
[edit] Notes
- ^ http://www.library.adelaide.edu.au/digitised/fisher/9.pdf
- ^ [Studies in Crop Variation. I. An examination of the yield of dressed grain from Broadbalk Journal of Agricultural Science, 11, 107-135 http://www.library.adelaide.edu.au/digitised/fisher/15.pdf]
[edit] References
- Ferguson, George A., Takane, Yoshio. (2005). "Statistical Analysis in Psychology and Education", Sixth Edition. Montréal, Quebec: McGraw-Hill Ryerson Limited.
- King, Bruce M., Minium, Edward W. (2003). Statistical Reasoning in Psychology and Education, Fourth Edition. Hoboken, New Jersey: John Wiley & Sons, Inc. ISBN 0-471-21187-7
- Lindman, H. R. (1974). Analysis of variance in complex experimental designs. San Francisco: W. H. Freeman & Co.
[edit] External links
- SOCR ANOVA Activity and interactive applet.
- A tutorial on ANOVA devised for Oxford University psychology students
- Examples of all ANOVA and ANCOVA models with up to three treatment factors, including randomized block, split plot, repeated measures, and Latin squares
- NIST/SEMATECH e-Handbook of Statistical Methods, section 7.4.3: "Are the means equal?"
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||

