Singular value decomposition
From Wikipedia, the free encyclopedia
In linear algebra, the singular value decomposition (SVD) is an important factorization of a rectangular real or complex matrix, with several applications in signal processing and statistics. Applications which employ the SVD include computing the pseudoinverse, least squares fitting of data, matrix approximation, and determining the rank, range and null space of a matrix.
[edit] Statement of the theorem
Suppose M is an m-by-n matrix whose entries come from the field K, which is either the field of real numbers or the field of complex numbers. Then there exists a factorization of the form

where U is an m-by-m unitary matrix over K, the matrix Σ is m-by-n diagonal matrix with nonnegative real numbers on the diagonal, and V* denotes the conjugate transpose of V, an n-by-n unitary matrix over K. Such a factorization is called a singular-value decomposition of M.
A common convention is to order the diagonal entries Σi,i in non-increasing fashion. In this case, the diagonal matrix Σ is uniquely determined by M (though the matrices U and V are not). The diagonal entries of Σ are known as the singular values of M.
[edit] Intuitive explanation
In
- the columns of V form a set of orthonormal "input" or "analysing" basis vector directions for M
- the columns of U form a set of orthonormal "output" basis vector directions for M
- the matrix Σ contains the singular values, which can be thought of as scalar "gain controls" by which each corresponding input is multiplied to give a corresponding output.
[edit] Example
Consider the matrix
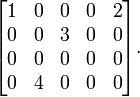
A singular value decomposition of this matrix is given by

that is

Notice above that Σ has non-zero values only in its diagonal. Furthermore, because the matrices U and V * are unitary, multiplying by their respective transpose yields the identity matrix, as shown below. In this case, because U and V * are real valued, they each are an orthogonal matrix.

and
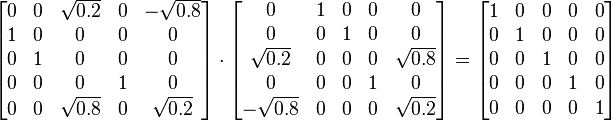
It should also be noted that this singular value decomposition is not unique. For example, choosing V such that

is also a valid singular value decomposition
[edit] Singular values, singular vectors, and their relation to the SVD
A non-negative real number σ is a singular value for M if and only if there exist unit-length vectors u in Km and v in Kn such that

The vectors u and v are called left-singular and right-singular vectors for σ, respectively.
In any singular value decomposition

the diagonal entries of Σ are necessarily equal to the singular values of M. The columns of U and V are, respectively, left- and right-singular vectors for the corresponding singular values. Consequently, the above theorem states that
- An m × n matrix M has at least one and at most p = min(m,n) distinct singular values.
- It is always possible to find a unitary basis for Km consisting of left-singular vectors of M.
- It is always possible to find a unitary basis for Kn consisting of right-singular vectors of M.
A singular value for which we can find two left (or right) singular vectors that are linearly independent is called degenerate.
Non-degenerate singular values always have unique left and right singular vectors, up to multiplication by a unit phase factor eiφ (for the real case up to sign). Consequently, if all singular values of M are non-degenerate and non-zero, then its singular value decomposition is unique, up to multiplication of a column of U by a unit phase factor and simultaneous multiplication of the corresponding column of V by the same unit phase factor.
Degenerate singular values, by definition, have non-unique singular vectors. Furthermore, if u1 and u2 are two left-singular vectors which both correspond to the singular value σ, then any normalized linear combination of the two vectors is also a left singular vector corresponding to the singular value σ. The similar statement is true for right singular vectors. Consequently, if M has degenerate singular values, then its singular value decomposition is not unique.
[edit] Applications of the SVD
[edit] Pseudoinverse
The singular value decomposition can be used for computing the pseudoinverse of a matrix. Indeed, the pseudoinverse of the matrix M with singular value decomposition M = UΣV * is

where Σ+ is the pseudoinverse of Σ, which is formed by replacing every nonzero entry by its reciprocal. The pseudoinverse is one way to solve linear least squares problems.
[edit] Solving homogeneous linear equations
A set of homogeneous linear equations can be written as  for a matrix
for a matrix 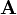 and vector
and vector 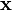 . A typical situation is that is known and a non-zero is to be determined which satisfies the equation. Such a belongs to 's null space and is sometimes called a (right) null vector of . can be characterized as a right singular vector corresponding to a singular value of that is zero. This observation means that if has no vanishing singular value, the equation has no non-zero as a solution. It also means that if there are several vanishing singular values, any linear combination of the corresponding right singular vectors is a valid solution. Analogously to the definition of a (right) null vector, a non-zero satisfying
. A typical situation is that is known and a non-zero is to be determined which satisfies the equation. Such a belongs to 's null space and is sometimes called a (right) null vector of . can be characterized as a right singular vector corresponding to a singular value of that is zero. This observation means that if has no vanishing singular value, the equation has no non-zero as a solution. It also means that if there are several vanishing singular values, any linear combination of the corresponding right singular vectors is a valid solution. Analogously to the definition of a (right) null vector, a non-zero satisfying 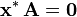 , with
, with  denoting the conjugate transpose of , is called a left null vector of .
denoting the conjugate transpose of , is called a left null vector of .
[edit] Total least squares minimization
A total least squares problem refers to determining the vector which minimizes the 2-norm of a vector  under the constraint
under the constraint  . The solution turns out to be the right singular vector of corresponding to the smallest singular value.
. The solution turns out to be the right singular vector of corresponding to the smallest singular value.
[edit] Range, null space and rank
Another application of the SVD is that it provides an explicit representation of the range and null space of a matrix M. The right singular vectors corresponding to vanishing singular values of M span the null space of M. The left singular vectors corresponding to the non-zero singular values of M span the range of M. As a consequence, the rank of M equals the number of non-zero singular values which is the same as the number of non-zero elements in Σ.
In numerical linear algebra the singular values can be used to determine the effective rank of a matrix, as rounding error may lead to small but non-zero singular values in a rank deficient matrix.
[edit] Matrix approximation
Some practical applications need to solve the problem of approximating a matrix M with another matrix 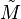 which has a specific rank r. In the case that the approximation is based on minimizing the Frobenius norm of the difference between M and under the constraint that
which has a specific rank r. In the case that the approximation is based on minimizing the Frobenius norm of the difference between M and under the constraint that  it turns out that the solution is given by the SVD of M, namely
it turns out that the solution is given by the SVD of M, namely

where  is the same matrix as Σ except that it contains only the r largest singular values (the other singular values are replaced by zero). This is known as the Eckart–Young theorem, as it was proved by those two authors in 1936 (although it was later found to have been known to earlier authors; see G. W. Stewart, "On the early history of the singular value decomposition," SIAM Review 35, p. 551-556, 1993).
is the same matrix as Σ except that it contains only the r largest singular values (the other singular values are replaced by zero). This is known as the Eckart–Young theorem, as it was proved by those two authors in 1936 (although it was later found to have been known to earlier authors; see G. W. Stewart, "On the early history of the singular value decomposition," SIAM Review 35, p. 551-556, 1993).
Quick proof: We hope to minimize 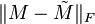 subject to .
subject to .
Suppose the SVD of M = UΣV * . Since the Frobenius norm is unitarily invariant, we have an equivalent statement:
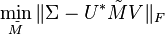
Note that since Σ is diagonal,  should be diagonal in order to minimize the Frobenius norm. Remember that the Frobenius norm is the square-root of the summation of the squared modulus of all entries. This implies that U and V are also singular matrices of
should be diagonal in order to minimize the Frobenius norm. Remember that the Frobenius norm is the square-root of the summation of the squared modulus of all entries. This implies that U and V are also singular matrices of  . Thus we can assume that to minimize the above statement has the form:
. Thus we can assume that to minimize the above statement has the form:

where S is diagonal. The diagonal entries si of S are not necessarily ordered as in SVD.
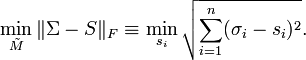
From the rank constraint, i.e. S has r non-zero diagonal entries, the minimum of the above statement is obtained as follows:

Therefore, of rank r is the best approximation of M in the Frobenius norm sense when  and the corresponding singular vectors are same as those of M.
and the corresponding singular vectors are same as those of M.
In addition to being the best approximation of a given rank to the matrix under the Frobenius norm, as defined above is also the best approximation of that rank under the L2 norm (see e.g. Trefethen and Bau, Numerical Linear Algebra).
Another example of matrix approximation by SVD is the solution to the orthogonal Procrustes problem of approximating any given matrix by an orthogonal matrix.
[edit] Separable models
The SVD can be thought of as decomposing a matrix into a weighted, ordered sum of separable matrices. By separable, we mean that a matrix can be written as an outer product of two vectors 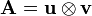 , or, in coordinates,
, or, in coordinates,  ; this is also called a simple tensor. Specifically, the matrix M can be decomposed as:
; this is also called a simple tensor. Specifically, the matrix M can be decomposed as:
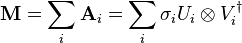
Here Ui and Vi are the ith columns of the corresponding SVD matrices, σi are the ordered singular values, and each 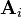 is separable. The SVD can be used to find the decomposition of an image processing filter into separable horizontal and vertical filters.[1] Note that the number of non-zero σi is exactly the tensor rank: the rank of M, thought of as a tensor.
is separable. The SVD can be used to find the decomposition of an image processing filter into separable horizontal and vertical filters.[1] Note that the number of non-zero σi is exactly the tensor rank: the rank of M, thought of as a tensor.
Separable models often arise in biological systems, and the SVD decomposition is useful to analyze such systems. For example, some visual area V1 simple cells receptive fields can be well described [2] by a Gabor filter in the space domain multiplied by a modulation function in the time domain. Thus, given a linear filter evaluated through, for example, reverse correlation, one can rearrange the two spatial dimensions into one dimension, thus yielding a two dimensional filter (space, time) which can be decomposed through SVD. The first column of U in the SVD decomposition is then a Gabor while the first column of V represents the time modulation (or vice-versa). One may then define an index of separability,  , which is the fraction of the power in the matrix M which is accounted for by the first separable matrix in the decomposition [3].
, which is the fraction of the power in the matrix M which is accounted for by the first separable matrix in the decomposition [3].
[edit] Other examples
The SVD is also applied extensively to the study of linear inverse problems, and is useful in the analysis of regularization methods such as that of Tikhonov. It is widely used in statistics where it is related to principal component analysis, and in signal processing and pattern recognition. It is also used in output-only modal analysis, where the non-scaled mode shapes can be determined from the singular vectors. Yet another usage is latent semantic indexing in natural language text processing.
The SVD also plays a crucial role in the field of Quantum information, in a form often referred to as the Schmidt decomposition. Through it, states of two quantum systems are naturally decomposed, providing a necessary and sufficient condition for them to be entangled : if the rank of the Σ matrix is larger than one.
One application of SVD to rather large matrices is in numerical weather prediction, where Lanczos methods are used to estimate the most linearly quickly growing few perturbations to the central numerical weather prediction over a given initial forward time period — i.e. the singular vectors corresponding to the largest singular values of the linearised propagator for the global weather over that time interval. The output singular vectors in this case are entire weather systems! These perturbations are then run through the full nonlinear model to generate an ensemble forecast, giving a handle on some of the uncertainty that should be allowed for around the current central prediction.
[edit] Relation to eigenvalue decomposition
The singular value decomposition is very general in the sense that it can be applied to any m × n matrix. The eigenvalue decomposition, on the other hand, can only be applied to certain classes of square matrices. Nevertheless, the two decompositions are related.
Given an SVD of M, as described above, the following two relations hold:


The right hand sides of these relations describe the eigenvalue decompositions of the left hand sides. Consequently, the squares of the non-zero singular values of M are equal to the non-zero eigenvalues of either M * M or MM * . Furthermore, the columns of U (left singular vectors) are eigenvectors of MM * and the columns of V (right singular vectors) are eigenvectors of M * M.
In the special case that M is a normal matrix, which by definition must be square, the spectral theorem says that it can be unitarily diagonalized using a basis of eigenvectors, so that it can be written M = UDU * for a unitary matrix U and a diagonal matrix D. When M is Hermitian positive semi-definite, the decomposition M = UDU * is also a singular value decomposition. However, the eigenvalue decomposition and the singular value decomposition differ for all other matrices M: the eigenvalue decomposition is M = UDU − 1 where U is not necessarily unitary and D is not necessarily positive semi-definite, while the SVD is M = UΣV * where Σ is a diagonal positive semi-definite, and U and V are unitary matrices that are not necessarily related except through the matrix M.
[edit] Existence
An eigenvalue λ of a matrix is characterized by the algebraic relation M u = λ u. When M is Hermitian, a variational characterization is also available. Let M be a real n × n symmetric matrix. Define f :Rn → R by f(x) = xT M x. This continuous function attains a maximum at some u when restricted to the closed unit sphere {||x|| ≤ 1}. By the Lagrange multipliers theorem, u necessarily satisfies

A short calculation shows the above leads to M u = λ u (symmetry of M is needed here). Therefore λ is the largest eigenvalue of M. The same calculation performed on the orthogonal complement of u gives the next largest eigenvalue and so on. The complex Hermitian case is similar; there f(x) = x* M x is a real-valued function of 2n real variables.
Singular values are similar in that they can be described algebraically or from variational principles. Although, unlike the eigenvalue case, Hermiticity, or symmetry, of M is no longer required.
This section gives these two arguments for existence of singular value decomposition.
[edit] Based on the spectral theorem
Let M be an m-by-n matrix with complex entries. M*M is positive semidefinite and Hermitian. By the spectral theorem, there exists a unitary n-by-n matrix V such that

where D is diagonal and positive definite. Partition V appropriately so we can write
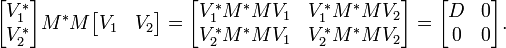
Therefore V*1M*MV1 = D, and MV2 = 0. Define
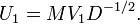
Then

We see that this is almost the desired result, except that U1 and V1 are not unitary in general. U1 is a partial isometry (U1U*1 = I ) while V1 is an isometry (V*1V1 = I ). To finish the argument, one simply has to "fill out" these matrices to obtain unitaries. V2 already does this for V1. Similarly, one can choose U2 such that
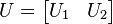
is unitary.
Define
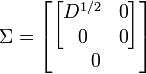
where the extra 0 rows are added one row for each column of U2. Then

which is the desired result:
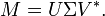
Notice the argument could begin with diagonalizing MM* rather than M*M (This shows directly that MM* and M*M have the same non-zero eigenvalues).
[edit] Based on variational characterization
The singular values can also be characterized as the maxima of uTMv, considered as a function of u and v, over particular subspaces. The singular vectors are the values of u and v where these maxima are attained.
Let M denote an m × n matrix with real entries. Let Sm − 1 and Sn − 1 denote the sets of unit 2-norm vectors in Rm and Rn respectively. Define the function
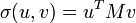
for vectors u ∈ Sm − 1 and v ∈ Sn − 1. Consider the function σ restricted to Sm − 1 × Sn − 1. Since both Sm − 1 and Sn − 1 are compact sets, their product is also compact. Furthermore, since σ is continuous, it attains a largest value for at least one pair of vectors u ∈ Sm − 1 and v ∈ Sn − 1. This largest value is denoted σ1 and the corresponding vectors are denoted u1 and v1. Since σ1 is the largest value of σ(u,v) it must be non-negative. If it were negative, changing the sign of either u1 or v1 would make it positive and therefore larger.
Statement: u1, v1 are left and right singular vectors of M with corresponding singular value σ1.
Proof: Similar to the eigenvalues case, by assumption the two vectors satisfy the Lagrange multiplier equation:

After some algebra, this becomes

and

Multiplying the first equation from left by 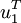 and the second equation from left by
and the second equation from left by  and taking ||u|| = ||v|| = 1 into account gives
and taking ||u|| = ||v|| = 1 into account gives

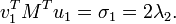
So σ1 = 2 λ1 = 2 λ2. By properties of the functional φ defined by

we have

Similarly,

This proves the statement.
More singular vectors and singular values can be found by maximizing σ(u, v) over normalized u, v which are orthogonal to u1 and v1, respectively.
The passage from real to complex is similar to the eigenvalue case.
[edit] Geometric meaning
Because U and V are unitary, we know that the columns u1,...,um of U yield an orthonormal basis of Km and the columns v1,...,vn of V yield an orthonormal basis of Kn (with respect to the standard scalar products on these spaces).
The linear transformation T :Kn → Km that takes a vector x to Mx has a particularly simple description with respect to these orthonormal bases: we have T(vi) = σi ui, for i = 1,...,min(m,n), where σi is the i-th diagonal entry of Σ, and T(vi) = 0 for i > min(m,n).
The geometric content of the SVD theorem can thus be summarized as follows: for every linear map T :Kn → Km one can find orthonormal bases of Kn and Km such that T maps the i-th basis vector of Kn to a non-negative multiple of the i-th basis vector of Km, and sends the left-over basis vectors to zero. With respect to these bases, the map T is therefore represented by a diagonal matrix with non-negative real diagonal entries.
To get a more visual flavour of singular values and SVD decomposition —at least when working on real vector spaces— consider the sphere S of radius one in Rn. The linear map T maps this sphere onto an ellipsoid in Rm. Non-zero singular values are simply the lengths of the semi-axes of this ellipsoid. Especially when n=m, and all the singular values are distinct and non-zero, the SVD decomposition of the linear map T can be easily analysed as a succession of three consecutive moves : consider the ellipsoid T(S) and specifically its axes ; then consider the directions in Rn sent by T onto these axes. These directions happen to be mutually orthogonal. Apply first an isometry v* sending these directions to the coordinate axes of Rn. On a second move, apply an endomorphism d diagonalized along the coordinate axes and stretching or shrinking in each direction, using the semi-axes lengths of T(S) as stretching coefficients. The composition d o v* then sends the unit-sphere onto an ellipsoid isometric to T(S). To define the third and last move u, just apply an isometry to this ellipsoid so as to carry it over T(S). As can be easily checked, the composition u o d o v* coincides with T.
[edit] Calculating the SVD
The SVD of a matrix M is typically computed by a two-step procedure. In the first step, the matrix is reduced to a bidiagonal matrix. This takes O(mn2) flops, assuming that m ≥ n (this formulation uses the big O notation). The second step is to compute the SVD of the bidiagonal matrix. This step can only be done with an iterative method, so the second step is in principle infinite (just as for eigenvalue algorithms). However, in practice it suffices to compute the SVD up to a certain precision, like the machine epsilon. If this precision is considered constant, then the second step takes O(n) iterations, each costing O(n) flops. Thus, the first step is more expensive, and the overall cost is O(mn2) flops (Bau III & Trefethen 1997, Lecture 31).
The first step can be done using Householder reflections for a cost of 4mn2 − 4n3/3 flops, assuming that only the singular values are needed and not the singular vectors. If m is much larger than n then it is advantageous to first reduce the matrix M to a triangular matrix with the QR decomposition and then use Householder reflections to further reduce the matrix to bidiagonal form; the combined cost is 2mn2 + 2n3 flops (Bau III & Trefethen 1997, Lecture 31).
The second step can be done by a variant of the QR algorithm for the computation of eigenvalues, which was first described by Golub & Kahan (1965). The LAPACK subroutine DBDSQR implements this iterative method, with some modifications to cover the case the singular values are very small (Demmel & Kahan 1990). Together with a first step using Householder reflections and, if appropriate, QR decomposition, this forms the DGESVD routine for the computation of the singular value decomposition.
The same algorithm is implemented in the GNU Scientific Library (GSL). The GSL also offers an alternative method, which uses a one-sided Jacobi orthogonalization in step 2 (GSL Team 2007). This method computes the SVD of the bidiagonal matrix by solving a sequence of 2-by-2 SVD problems, similar to how the Jacobi eigenvalue algorithm solves a sequence of 2-by-2 eigenvalue methods (Golub & Van Loan 1996, §8.6.3). Yet another method for step 2 uses the idea of divide-and-conquer eigenvalue algorithms (Bau III & Trefethen 1997, Lecture 31).
[edit] Reduced SVDs
In applications it is quite unusual for the full SVD, including a full unitary decomposition of the null-space of the matrix, to be required. Instead, it is often sufficient (as well as faster, and more economical for storage) to compute a reduced version of the SVD. The following can be distinguished for an m×n matrix M of rank r:
[edit] Thin SVD

Only the n column vectors of U corresponding to the row vectors of V* are calculated. The remaining column vectors of U are not calculated. This is significantly quicker and more economical than the full SVD if n<<m. The matrix Un is thus m×n, Σn is n×n diagonal, and V is n×n.
The first stage in the calculation of a thin SVD will usually be a QR decomposition of M, which can make for a significantly quicker calculation if n<<m.
[edit] Compact SVD
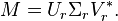
Only the r column vectors of U and r row vectors of V* corresponding to the non-zero singular values Σr are calculated. The remaining vectors of U and V* are not calculated. This is quicker and more economical than the thin SVD if r<<n. The matrix Ur is thus m×r, Σr is r×r diagonal, and Vr* is r×n.
[edit] Truncated SVD

Only the t column vectors of U and t row vectors of V* corresponding to the t largest singular values Σr are calculated. The rest of the matrix is discarded. This can be much quicker and more economical than the thin SVD if t<<r. The matrix Ut is thus m×t, Σt is t×t diagonal, and Vt* is t×n'.
Of course the truncated SVD is no longer an exact decomposition of the original matrix M, but as discussed below, the approximate matrix is in a very useful sense the closest approximation to M that can be achieved by a matrix of rank t.
[edit] Norms
[edit] Ky Fan norms
The sum of the k largest singular values of M is a matrix norm, the Ky Fan k-norm of M.
The first of the Ky Fan norms, the Ky Fan 1-norm is the same as the operator norm of M as a linear operator with respect to the Euclidean norms of Km and Kn. In other words, the Ky Fan 1-norm is the operator norm induced by the standard l2 Euclidean inner product. For this reason, it is also called the operator 2-norm. One can easily verify the relationship between the Ky Fan 1-norm and singular values. It is true in general, for a bounded operator M on (possibly infinite dimensional) Hilbert spaces
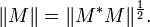
But, in the matrix case, M*M½ is a normal matrix, so ||M* M||½ is the largest eigenvalue of M* M½, i.e. the largest singular value of M.
The last of the Ky Fan norms, the sum of all singular values, is the trace norm, defined by ||M|| = Tr[(M*M)½] (the diagonal entries of M* M are the squares of the singular values).
[edit] Hilbert-Schmidt norm
The singular values are related to another norm on the space of operators. Consider the Hilbert-Schmidt inner product on the n × n matrices, defined by  . So the induced norm is
. So the induced norm is  . Since trace is invariant under unitary equivalence, this shows
. Since trace is invariant under unitary equivalence, this shows

where si are the singular values of M. This is called the Frobenius norm, Schatten 2-norm, or Hilbert-Schmidt norm of M. Direct calculation shows that if
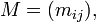
the Frobenius norm of M coincides with

[edit] 2DSVD
SVD computes the low-rank approximation of a single matrix (or a set of 1D vectors). This can be generalized to two-dimensional singular value decomposition (2DSVD) to do low-rank approximation of a set of 2D matrices such as a set of images or 2D weather maps.
[edit] HOSVD
Higher order singular value decomposition (HOSVD) is a generalization of SVD for multidimensional arrays (tensors). It is able to give optimal low-rank approximation in given dimensions of a tensor. In the case of a 3 dimensional array (array of matrices) executing HOSVD in 2 dimensions gives the same result as 2DSVD.
[edit] Bounded operators on Hilbert spaces
The factorization M = UΣV * can be extended to a bounded operator M on a separable Hilbert space H. Namely, for any bounded operator M, there exist a partial isometry U, a unitary V, a measure space (X, μ), and a non-negative measurable f such that

where Tf is the multiplication by f on L2(X, μ).
This can be shown by mimicking the linear algebraic argument for the matricial case above. VTf V* is the unique positive square root of M*M, as given by the Borel functional calculus for self adjoint operators. The reason why U need not be unitary is because, unlike the finite dimensional case, given an isometry U1 with non trivial kernel, a suitable U2 may not be found such that

is a unitary operator.
As for matrices, the singular value factorization is equivalent to the polar decomposition for operators: we can simply write

and notice that U V* is still a partial isometry while VTf V* is positive.
[edit] Singular values and compact operators
To extend notion of singular values and left/right-singular eigenvectors to the operator case, one needs to restrict to compact operators. It is a general fact that compact operators on Banach spaces, therefore Hilbert spaces, have only discrete spectrum: If T is compact, every nonzero λ in its spectrum is an eigenvalue. Furthermore, a compact self adjoint operator can be diagonalized by its eigenvectors. If M is compact, so is M*M. Applying the diagonalization result, the unitary image of its positive square root Tf has a set of orthonormal eigenvectors {ei} corresponding to strictly positive eigenvalues {σi}. For any ψ ∈ H,
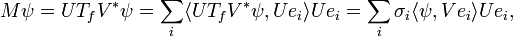
where the series converges in the norm topology on H. Notice how this resembles the expression from the finite dimensional case. The σi 's are called the singular values of M. {U ei} and {V ei} can be considered the left- and right-singular vectors of M respectively.
Compact operators on a Hilbert space are the closure of finite rank operators in the uniform operator topology. The above series expression gives an explicit such representation. An immediate consequence of this is:
Theorem M is compact if and only if M*M is compact.
[edit] History
The singular value decomposition was originally developed by differential geometers, who wished to determine whether a real bilinear form could be made equal to another by independent orthogonal transformations of the two spaces it acts on. Eugenio Beltrami and Camille Jordan discovered independently, in 1873 and 1874 respectively, that the singular values of the bilinear forms, represented as a matrix, form a complete set of invariants for bilinear forms under orthogonal substitutions. James Joseph Sylvester also arrived at the singular value decomposition for real square matrices in 1889, apparently independent of both Beltrami and Jordan. Sylvester called the singular values the canonical multipliers of the matrix A. The fourth mathematician to discover the singular value decomposition independently is Autonne in 1915, who arrived at it via the polar decomposition. The first proof of the singular value decomposition for rectangular and complex matrices seems to be by Eckart and Young in 1936; they saw it as a generalization of the principal axis transformation for Hermitian matrices.
In 1907, Erhard Schmidt defined an analog of singular values for integral operators (which are compact, under some weak technical assumptions); it seems he was unaware of the parallel work on singular values of finite matrices. This theory was further developed by Émile Picard in 1910, who is the first to call the numbers σk singular values (or rather, valeurs singulières).
Practical methods for computing the SVD date back to Kogbetliantz in 1954, 1955 and Hestenes in 1958 resembling closely the Jacobi eigenvalue algorithm, which uses plane rotations or Givens rotations. However, these were replaced by the method of Gene Golub and William Kahan published in 1965 (Golub & Kahan 1965), which uses Householder transformations or reflections. In 1970, Golub and Christian Reinsch published a variant of the Golub/Kahan algorithm that is still the one most-used today.
[edit] See also
- matrix decomposition
- Canonical form
- Singular value
- eigendecomposition
- generalized singular value decomposition
- polar decomposition
- principal components analysis (PCA)
- empirical orthogonal functions (EOFs)
- canonical correlation analysis (CCA)
- latent semantic analysis
[edit] Notes
- ^ Separable convolution: Part 2 | Steve on Image Processing
- ^ DeAngelis et al., Receptive-field dynamics in the central visual pathways, Trends Neurosci. 1995, Entrez Pubmed 8545912
- ^ Depireux et al., Spectro-temporal response field characterization with dynamic ripples in ferret primary auditory cortex, J. Neurophysiol. 2001, Entrez Pubmed 11247991
[edit] References
- Bau III, David; Trefethen, Lloyd N. (1997), Numerical linear algebra, Philadelphia: Society for Industrial and Applied Mathematics, ISBN 978-0-89871-361-9.
- Demmel, James; Kahan, William (1990), "Accurate singular values of bidiagonal matrices", Society for Industrial and Applied Mathematics. Journal on Scientific and Statistical Computing 11 (5): 873–912, doi:, ISSN 0196-5204.
- Eckart, C., & Young, G. (1936). The approximation of one matrix by another of lower rank. Psychometrika, I, 211-218.
- Golub, Gene H.; Kahan, William (1965), "Calculating the singular values and pseudo-inverse of a matrix", Journal of the Society for Industrial and Applied Mathematics: Series B, Numerical Analysis 2 (2): 205–224, http://www.jstor.org/stable/2949777.
- Golub, Gene H.; Van Loan, Charles F. (1996), Matrix Computations (3rd ed.), Johns Hopkins, ISBN 978-0-8018-5414-9.
- GSL Team (2007), "§13.4 Singular Value Decomposition", GNU Scientific Library. Reference Manual.
- Halldor, Bjornsson and Venegas, Silvia A. (1997). "A manual for EOF and SVD analyses of climate data". McGill University, CCGCR Report No. 97-1, Montréal, Québec, 52pp.
- Hansen, P. C. (1987). The truncated SVD as a method for regularization. BIT, 27, 534-553.
- Horn, Roger A. and Johnson, Charles R (1985). "Matrix Analysis". Section 7.3. Cambridge University Press. ISBN 0-521-38632-2.
- Horn, Roger A. and Johnson, Charles R (1991). Topics in Matrix Analysis, Chapter 3. Cambridge University Press. ISBN 0-521-46713-6.
- Strang G (1998). "Introduction to Linear Algebra". Section 6.7. 3rd ed., Wellesley-Cambridge Press. ISBN 0-9614088-5-5.
- Stewart, G. W. (1993), "On the Early History of the Singular Value Decomposition", SIAM Review 35 (4): 551–566, doi:, http://citeseer.ist.psu.edu/stewart92early.html.
- Wall, Michael E., Andreas Rechtsteiner, Luis M. Rocha (2003). "Singular value decomposition and principal component analysis". in A Practical Approach to Microarray Data Analysis. D.P. Berrar, W. Dubitzky, M. Granzow, eds. pp. 91-109, Kluwer: Norwell, MA.
[edit] External links
[edit] Implementations
[edit] Libraries that support complex and real SVD
- LAPACK (website), the Linear Algebra Package. The user manual gives details of subroutines to calculate the SVD (see also [1]).
[edit] Libraries that support real SVD
- GNU Scientific Library (website), a numerical C/C++ library supporting SVD (see [2]).
- Eigen2, a C++ open source library supporting SVD with an elegant API. It is released under licences LGPL3+ or LGPL2+.
- ALGLIB, includes a partial port of the LAPACK to C++, C#, Delphi, Visual Basic, etc.
- JAMA, a Java matrix package provided by the NIST.
- PROPACK, computes the SVD of large and sparse or structured matrices.
- SVDPACK, a library in ANSI FORTRAN 77 implementing four iterative SVD methods. Includes C and C++ interfaces.
- SVDLIBC, re-writing of SVDPACK in C.
- SVD-Python, pure Python SVD under GNU GPL.
- NumPy SVD part of the linalg module of the NumPy module for numerical computing in Python
[edit] Texts and demonstrations
- MIT Lecture series by Gilbert Strang. See Lecture #29 on the SVD (scroll down to the bottom till you see "Singular Value Decomposition"). The first 17 minutes give the overview. Then Prof. Strang works two examples. Then the last 4 minutes (min 36 to min 40) are a summary. You can probably fast forward the examples, but the first and last are an excellent concise visual presentation of the topic.
- Applications of SVD on PC Hansen's web site.
- Introduction to the Singular Value Decomposition by Todd Will of the University of Wisconsin--La Crosse. This site has animations for the visual minded as well as demonstrations of compression using SVD.
- Los Alamos group's book chapter has helpful gene data analysis examples.
- SVD, another explanation of singular value decomposition
- SVD Tutorial,yet another explanation of SVD. Very intuitive.
- Javascript script demonstrating the SVD more extensively, paste your data from a spreadsheet.
- Javascript script version 2 demonstrating the SVD featere AI-porperties to make a decision support.
- Chapter from "Numerical Recipes in C" gives more information about implementation and applications of SVD. (Acrobat DRM plug-in required)
- Online Matrix Calculator Performs singular value decomposition of matrices.
- A simple tutorial on SVD and applications of Spectral Methods
- Matrix and Tensor Decompositions in Genomic Signal Processing
- SVD on MathWorld, with image compression as an example application.
- If you liked this... New York Times article on SVD in movie-ratings and Netflix

