Type inference
From Wikipedia, the free encyclopedia
Type inference, or implicit typing, refers to the ability to deduce automatically the type of a value in a programming language. It is a feature present in some strongly statically typed languages. It is often characteristic of — but not limited to — functional programming languages in general. Some languages that include type inference are: Ada, BitC, Boo, C# 3.0, Cayenne, Clean, Cobra, D, Epigram, F#, Haskell, ML, Nemerle, OCaml, Oxygene, Scala, and Visual Basic .NET 9.0. This feature is planned for Fortress, C++0x and Perl 6. The ability to infer types automatically makes many programming tasks easier, leaving the programmer free to omit type annotations while maintaining some level of type safety. Explicitly converting to another data type is called "casting" (or a "cast").
Contents |
[edit] Nontechnical explanation
In most programming languages, all values have a type which describes the kind of data a particular value describes. In some languages, the type is known only at runtime; these languages are dynamically typed. In other languages, the type is known at compile time; these languages are statically typed. In statically typed languages, the input and output types of functions and local variables ordinarily must be explicitly provided by type annotations. For example, in C:
int addone(int x) { int result; /*declare integer result (C language)*/ result = x+1; return result; }
The beginning of this function definition, int addone(int x) declares that addone is a function which takes one argument, an integer, and returns an integer. int result; declares that the local variable result is an integer. In a proposed language where type inference is available, the code might be written like this instead:
addone(x) {
val result; /*inferred-type result */
val result2; /*inferred-type result #2 */
result = x+1;
result2 = x+1.0; /* this line won't work (in the proposed language) */
return result;
}
This looks very similar to how code is written in a dynamically typed language, yet all types are known at compile time. In the imaginary language in which the last example is written, + always takes two integers and returns one integer (which is how it works in, for example, OCaml). From this, the type inferencer can infer that the value of x+1 is an integer, therefore result is an integer, therefore the return value of addone is an integer. Similarly, since + requires that both of its arguments be integers, x must be an integer, and therefore addone accepts one integer as an argument.
However, in the subsequent line, result2 is calculated by adding a decimal "1.0" with floating-point arithmetic, causing a conflict in the use of x for both integer and floating-point expressions. Such a situation would generate a compile-time error message. In older languages, result2 might have been implicitly declared as a floating-point variable, from implicitly converting integer x in the expression, simply because a decimal point was accidentally placed after the integer 1. Such a situation shows the difference between type inference, which does not involve type conversion, and implicit type conversion, which forces data to the higher-precision data type, often without restrictions.
[edit] Technical description
Type inference refers to the ability to deduce automatically, either partially or fully, the type of a value derived from the eventual evaluation of an expression. As this process is systematically performed at compile time, the compiler is often able to infer the type of a variable or the type signature of a function, without explicit type annotations having been given. In many cases, it is possible to omit type annotations from a program completely if the type inference system is robust enough, or the program or language simple enough.
To obtain the information required to infer correctly the type of an expression lacking an explicit type annotation, the compiler either gathers this information as an aggregate and subsequent reduction of the type annotations given for its subexpressions (which may themselves be variables or functions), or through an implicit understanding of the type of various atomic values (e.g., () : Unit; true : Bool; 42 : Integer; 3.14159 : Real; etc.). It is through recognition of the eventual reduction of expressions to implicitly typed atomic values that the compiler for a type inferring language is able to compile a program completely without type annotations. In the case of highly complex forms of higher order programming and polymorphism, it is not always possible for the compiler to infer as much, however, and type annotations are occasionally necessary for disambiguation.
[edit] Example
For example, let us consider the Haskell function map, which applies a procedure to each element of a list, and may be defined as:
map f [] = [] map f (first:rest) = f first : map f rest
From this, it is evident that the function map takes a list as its second argument, that its first argument f is a function that can be applied to the type of elements of that list, and that the result of map is constructed as a list with elements that are results of f. So assuming that a list contains elements of the same type, we can reliably construct a type signature
map :: (a -> b) -> [a] -> [b]
where the syntax "a -> b" denotes a function that takes an a as its parameter and produces a b. "a -> b -> c" is equivalent to "a -> (b -> c)".
Note that the inferred type of map is parametrically polymorphic: The type of the arguments and results of f are not inferred, but left as type variables, and so map can be applied to functions and lists of various types, as long as the actual types match in each invocation.
[edit] Hindley–Milner type inference algorithm
The common algorithm used to perform type inference is the one now commonly referred to as Hindley–Milner, Damas–Milner algorithm. It has been referred to in the past as polymorphic type checking or Algorithm W.
The origin of this algorithm is the type inference algorithm for the simply typed lambda calculus, which was devised by Haskell B. Curry and Robert Feys in 1958. In 1969 Roger Hindley extended this work and proved that their algorithm always inferred the most general type. In 1978 Robin Milner [1], independently of Hindley's work, provided an equivalent algorithm, Algorithm W. In 1982 Luis Damas [2] finally proved that Milner's algorithm is complete and extended it to support systems with polymorphic references.
[edit] The algorithm
The algorithm proceeds in two steps. First, we need to generate a number of equations to solve, then we need to solve them.
[edit] Generating the equations
The algorithm used for generating the equations is similar to a regular type checker, so let's consider first a regular type checker for the typed lambda calculus given by

and

where E is a primitive expression (such as "3") and T is a primitive type (such as "Integer").
We want to construct a function f which maps a pair (ε,t), where ε is a type environment and t is a term, to some type τ. We assume that this function is already defined on primitives. The other cases are:
- f(ε,v) = τ where (v,τ) is in ε
 where
where  and f(ε,e) = τ1
and f(ε,e) = τ1 where
where 
Note that so far we do not specify what to do when we fail to meet the various conditions. This is because, in the simple type checking algorithm, the check simply fails whenever anything goes wrong.
Now, we develop a more sophisticated algorithm that can deal with type variables and constraints on them. Therefore, we extend the set T of primitive types to include an infinite supply of variables, denoted by lowercase Greek letters α,β,...
See [3] for more details.
[edit] Solving the equations
Solving the equations proceeds by unification. This is—perhaps surprisingly—a rather simple algorithm. The function u operates on type equations and returns a structure called a "substitution". A substitution is simply a mapping from type variables to types. Substitutions can be composed and extended in the obvious ways.
Unifying the empty set of equations is easy enough:  , where
, where 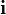 is the identity substitution.
is the identity substitution.
Unifying a variable with a type goes this way: ![u\, ([\alpha = T] \cup C) = u\, (C') \cdot (\alpha \mapsto T)](http://upload.wikimedia.org/math/e/3/4/e34da347a1ae0841e2602189dc0ba96b.png) , where
, where  is the substitution composition operator, and C' is the set of remaining constraints C with the new substitution
is the substitution composition operator, and C' is the set of remaining constraints C with the new substitution  applied to it.
applied to it.
Of course, ![u\, ([T = \alpha] \cup C) = u ([\alpha = T] \cup C)](http://upload.wikimedia.org/math/d/7/4/d74501f0284fa4327f2aeb4259544f14.png) .
.
The interesting case remains as ![u\, ([S \to S' = T \to T']\cup C) = u \, (\{[S = T], [S' = T']\}\cup C)](http://upload.wikimedia.org/math/1/7/f/17f83c89a3aa39b10d0b5e816244a490.png) .
.
A simple example would be a[i] = b[i] (assume this to be c-like syntax for this example). First Hindley-Milner would find that i must be of type int, further more that 'a' must be an "array of α" and 'b' must an "array of β". Now, since there is an assignment of β to α, α must be of the same type (assuming no implicit type conversions) as β. In the very least α must be a supertype of β.
[edit] References
- ^ Milner, Robin (1978), "A Theory of Type Polymorphism in Programming", Jcss 17: 348–375
- ^ Damas, Luis; Milner, Robin (1982), "Principal type-schemes for functional programs", POPL '82: Proceedings of the 9th ACM SIGPLAN-SIGACT symposium on Principles of programming languages, ACM, pp. 207--212, http://groups.csail.mit.edu/pag/6.883/readings/p207-damas.pdf
- ^ Pierce, Benjamin C. (2002). "Chapter 22". Types and Programming Languages. MIT Press. ISBN 0-262-16209-1.
[edit] See also
- Duck typing, an analogous concept in languages with dynamic or weak typing
[edit] External links
- Archived e-mail message by Roger Hindley explaining the history of type inference
- Implementation of Hindley-Milner in Perl 5, by Nikita Borisov (via Internet Archive, version Sep 11, 2005)

