Automata theory
From Wikipedia, the free encyclopedia
In theoretical computer science, automata theory is actually the study of abstract machines and problems which they are able to solve. Automata theory is closely related to formal language theory as the automata are often classified by the class of formal languages they are able to recognize.
An automaton is a mathematical model for a finite state machine (FSM). A FSM is a machine that, given an input of symbols, "jumps", or transitions, through a series of states according to a transition function (which can be expressed as a table). In the common "Mealy" variety of FSMs, this transition function tells the automaton which state to go to next given a current state and a current symbol.
The input is read symbol by symbol, until it is consumed completely (similar to a tape with a word written on it, which is read by a reading head of the automaton; the head moves forward over the tape, reading one symbol at a time). Once the input is depleted, the automaton is said to have stopped.
Depending on the state in which the automaton stops, it's said that the automaton either accepts or rejects the input. If it landed in an accept state, then the automaton accepts the word. If, on the other hand, it lands on a reject state, the word is rejected. The set of all the words accepted by an automaton is called the language accepted by the automaton.
Note, however, that, in general, an automaton need not have a finite number of states, or even a countable number of states. Thus, for example, the quantum finite automaton has an uncountable infinity of states, as the set of all possible states is the set of all points in complex projective space. Thus, quantum finite automata, as well as finite state machines, are special cases of a more general idea, that of a topological automaton, where the set of states is a topological space, and the state transition functions are taken from the set of all possible functions on the space. Topological automata are often called M-automata, and are simply the augmentation of a semiautomaton with a set of accept states, where set intersection determines whether the initial state is accepted or rejected.
In general, an automaton need not strictly accept or reject an input; it may accept it with some probability between zero and one. Again this is illustrated by the quantum finite automaton, which only accepts input with some probability. This idea is again a special case of a more general notion, the geometric automaton or metric automaton, where the set of states is a metric space, and a language is accepted by the automaton if the distance between the initial point, and the set of accept states is sufficiently small with respect to the metric.
Automata play a major role in compiler design and parsing.
Contents |
[edit] Vocabulary
The basic concepts of symbols, words, alphabets and strings are common to most descriptions of automata. These are:
- Symbol
- An arbitrary datum which has some meaning to or effect on the machine. Symbols are sometimes just called "letters" or "atoms"[1].
- Word
- A finite string formed by the concatenation of a number of symbols.
- Alphabet
- A finite set of symbols. An alphabet is frequently denoted by Σ, which is the set of letters in an alphabet.
- Language
- A set of words, formed by symbols in a given alphabet. May or may not be infinite.
- Kleene closure
- A language may be thought of as a subset of all possible words. The set of all possible words may, in turn, be thought of as the set of all possible concatenations of strings. Formally, this set of all possible strings is called a free monoid. It is denoted as Σ * , and the superscript * is called the Kleene star.
[edit] Formal description
An automaton is represented by the 5-tuple  , where:
, where:
- Q is a set of states.
- ∑ is a finite set of symbols, that we will call the alphabet of the language the automaton accepts.
- δ is the transition function, that is
-
- (For non-deterministic automata, the empty string is an allowed input).

- q0 is the start state, that is, the state in which the automaton is when no input has been processed yet, where q0∈ Q.
- F is a set of states of Q (i.e. F⊆Q) called accept states.
Given an input letter  , one may write the transition function as
, one may write the transition function as  , using the simple trick of currying, that is, writing δ(q,a) = δa(q) for all
, using the simple trick of currying, that is, writing δ(q,a) = δa(q) for all 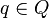 . This way, the transition function can be seen in simpler terms: it's just something that "acts" on a state in Q, yielding another state. One may then consider the result of function composition repeatedly applied to the various functions δa, δb, and so on. Repeated function composition forms a monoid. For the transition functions, this monoid is known as the transition monoid, or sometimes the transformation semigroup.
. This way, the transition function can be seen in simpler terms: it's just something that "acts" on a state in Q, yielding another state. One may then consider the result of function composition repeatedly applied to the various functions δa, δb, and so on. Repeated function composition forms a monoid. For the transition functions, this monoid is known as the transition monoid, or sometimes the transformation semigroup.
Given a pair of letters  , one may define a new function
, one may define a new function  , by insisting that
, by insisting that  , where
, where  denotes function composition. Clearly, this process can be recursively continued, and so one has a recursive definition of a function
denotes function composition. Clearly, this process can be recursively continued, and so one has a recursive definition of a function  that is defined for all words
that is defined for all words  , so that one has a map
, so that one has a map

The construction can also be reversed: given a , one can reconstruct a δ, and so the two descriptions are equivalent.
The triple 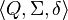 is known as a semiautomaton. Semiautomata underlay automata, in that they are just automata where one has ignored the starting state and the set of accept states. The additional notions of a start state and an accept state allow automata to do something the semiautomata cannot: they can recognize a formal language. The language L accepted by a deterministic finite automaton is:
is known as a semiautomaton. Semiautomata underlay automata, in that they are just automata where one has ignored the starting state and the set of accept states. The additional notions of a start state and an accept state allow automata to do something the semiautomata cannot: they can recognize a formal language. The language L accepted by a deterministic finite automaton is:

That is, the language accepted by an automaton is the set of all words w, over the alphabet Σ, that, when given as input to the automaton, will result in its ending in some state from F. Languages that are accepted by automata are called recognizable languages.
When the set of states Q is finite, then the automaton is known as a finite state automaton, and the set of all recognizable languages are the regular languages. In fact, there is a strong equivalence: for every regular language, there is a finite state automaton, and vice versa.
As noted above, the set Q need not be finite or countable; it may be taken to be a general topological space, in which case one obtains topological automata. Another possible generalization is the metric automata or geometric automata. In this case, the acceptance of a language is altered: instead of a set inclusion of the final state in 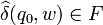 , the acceptance criteria are replaced by a probability, given in terms of the metric distance between the final state
, the acceptance criteria are replaced by a probability, given in terms of the metric distance between the final state  and the set F. Certain types of probabilistic automata are metric automata, with the metric being a measure on a probability space.
and the set F. Certain types of probabilistic automata are metric automata, with the metric being a measure on a probability space.
[edit] Classes of finite automata
The following are three kinds of finite automata
- Deterministic finite automata (DFA)
- Each state of an automaton of this kind has a transition for every symbol in the alphabet.

- Nondeterministic finite automata (NFA)
- States of an automaton of this kind may or may not have a transition for each symbol in the alphabet, or can even have multiple transitions for a symbol. The automaton accepts a word if there exists at least one path from q0 to a state in F labeled with the input word. If a transition is undefined, so that the automaton does not know how to keep on reading the input, the word is rejected.

- Nondeterministic finite automata, with ε transitions (FND-ε or ε-NFA)
- Besides of being able to jump to more (or none) states with any symbol, these can jump on no symbol at all. That is, if a state has transitions labeled with ε, then the NFA can be in any of the states reached by the ε-transitions, directly or through other states with ε-transitions. The set of states that can be reached by this method from a state q, is called the ε-closure of q.
It can be shown, though, that all these automata can accept the same languages. You can always construct some DFA M' that accepts the same language as a given NFA M.
[edit] Extensions of finite automata
The family of languages accepted by the above-described automata is called the family of regular languages. More powerful automata can accept more complicated languages. Such automata include:
- Pushdown automata (PDA)
- Such machines are identical to DFAs (or NFAs), except that they additionally carry memory in the form of a stack. The transition function δ will now also depend on the symbol(s) on top of the stack, and will specify how the stack is to be changed at each transition. Non-determinstic PDAs accept the context-free languages.
- Linear Bounded Automata (LBA)
- An LBA is a limited Turing machine; instead of an infinite tape, the tape has an amount of space proportional to the size of the input string. LBAs accept the context-sensitive languages.
- Turing machines
- These are the most powerful computational machines. They possess an infinite memory in the form of a tape, and a head which can read and change the tape, and move in either direction along the tape. Turing machines are equivalent to algorithms, and are the theoretical basis for modern computers. Turing machines decide/accept recursive languages and recognize the recursively enumerable languages.
[edit] External links
- Visual Automata Simulator
- JFLAP
- dk.brics.automaton
- libfa
- Proyecto SEPa (in Spanish)
- Exorciser (in German)
[edit] References
- John E. Hopcroft, Rajeev Motwani, Jeffrey D. Ullman - Introduction to Automata Theory, Languages, and Computation (2nd Edition)
- Michael Sipser (1997). Introduction to the Theory of Computation. PWS Publishing. ISBN 0-534-94728-X. Part One: Automata and Languages, chapters 1–2, pp.29–122. Section 4.1: Decidable Languages, pp.152–159. Section 5.1: Undecidable Problems from Language Theory, pp.172–183.
- James P. Schmeiser, David T. Barnard (1995). Producing a top-down parse order with bottom-up parsing. Elsevier North-Holland.
|
||||||||||||||||||||||||||||||||||||||||||||||||

