Devanagari
From Wikipedia, the free encyclopedia
| Devanāgarī | |
 Rigveda manuscript in Devanāgarī (early 19th century) |
|
| Type | Abugida |
|---|---|
| Spoken languages | Several Indo-Aryan languages, including Sanskrit, Hindi, Marathi, Nepali, Bhili, Konkani, Bhojpuri, Magahi, Maithili, Newari and sometimes Sindhi and Kashmiri. Formerly used to write Gujarati. |
| Time period | c. 1200–present |
| Parent systems | |
| Child systems | Gujarati Moḍī Ranjana Canadian Aboriginal syllabics |
| Sister systems | Sharada, Eastern Nāgarī |
| Unicode range | U+0900–U+097F |
| ISO 15924 | Deva |
| Note: This page may contain IPA phonetic symbols in Unicode. | |
|
|
This article contains Indic text. Without proper rendering support, you may see question marks or boxes, misplaced vowels or missing conjuncts instead of Indic text. |
Devanāgarī (देवनागरी, pronounced /ˌdeɪvəˈnɑːɡəriː/ in English[1]), or Nāgarī, is an abugida alphabet of India and Nepal. It is written from left to right, lacks distinct letter cases, and is recognizable by a distinctive horizontal line running along the tops of the letters that links them together. Devanāgarī is the main script used to write Hindi, Marathi, and Nepali. Since the 19th century, it has been the most commonly used script for Sanskrit. Devanāgarī is also employed for Gujari, Bhili, Bhojpuri, Konkani, Magahi, Maithili, Marwari, Newari, Pahari (Garhwali and Kumaoni), Santhali, Tharu, and sometimes Sindhi, Panjabi, and Kashmiri. It was formerly used to write Gujarati.
|
||||||||||||||
Contents |
[edit] Origins
Devanāgarī is part of the Brahmic family of alphabets of Nepal, India, Tibet, and South-East Asia. It is a descendant of the Gupta script, along with Siddham and Sharada. Eastern variants of Gupta called Nāgarī are first attested from the 8th century; from c. 1200 these gradually replaced Siddham, which survived as a vehicle for Tantric Buddhism in East Asia, and Sharada, which remained in parallel use in Kashmir.
Sanskrit nāgarī is the feminine of nāgara "urban(e)", a vrddhi adjectival form of nagara "city". It is feminine from its original phrasing with lipi "script" as nāgarī lipi "urban(e) script", that is, the script of the cultured. There are several varieties of Nāgarī in use, one of which was distinguished by affixing Deva "god" or "deity" to form a tatpurusha compound meaning the "urban(e) [script] of the gods", or "divine urban(e) [script]".
The use of the name Devanāgarī is relatively recent, and the older term Nāgarī is still common. The rapid spread of the term Devanāgarī may be related to the almost exclusive use of this script to publish sacred Sanskrit texts in colonial times. This has led to such a close connection between Devanāgarī and Sanskrit that Devanāgarī is now widely thought to be the Sanskrit script; however, before the colonial period there was no standard script for Sanskrit, which was written in whichever script was familiar to the local populace.
[edit] Principles
As a Brahmic abugida, the fundamental principle of Devanāgarī is that each letter represents a consonant, which carries an inherent vowel a [ə].[2] For example, the letter क is read ka, the two letters कन are kana, the three कनय are kanaya, etc. Other vowels, or the absence of vowels, require modification of these consonants or their own letters:
- Consonant clusters are written with ligatures (saṃyuktākṣara "conjuncts"). For example, the three letters कनय kanaya may be joined to form क्नय knaya, कन्य kanya, or क्न्य knya.
- Vowels other than the inherent a are written with diacritics. From क ka we get के ke, कु ku, की kī, का kā, etc.
- For vowels without a consonant, either at the beginning of a word or after another vowel, there are full letters. Thus while the vowel ū is written with the diacritic ू in कू kū, it has its own letter ऊ in ऊक ūka and कऊ kaū.
- A final consonant is marked with the diacritic ्, called the virāma in Sanskrit, halanta in Hindi, and a "killer stroke" in English. This cancels the inherent vowel, so that from क्नय knaya we get क्नय् knay. The halanta will often be used for consonant clusters when typesetting ligatures is not feasible.
Such a letter or ligature, with its diacritics, is called an akṣara "syllable". For example, कनय kanaya is written with what are counted as three akshara, whereas क्न्य knya and कु ku are each written with one.
As far as handwriting is concerned, letters are usually written without the distinctive horizontal bar, which is only added once the word is finished being written. [3]
[edit] Letters
| This article contains IPA phonetic symbols. Without proper rendering support, you may see question marks, boxes, or other symbols instead of Unicode characters. |
The letter order of Devanāgarī, like nearly all Brahmi scripts, is based on phonetic principles which consider both the manner and place of articulation of the consonants and vowels they represent. This arrangement is usually referred to as the varṇamālā "garland of letters".[4] The format of Devanāgarī for Sanskrit serves as the prototype for its application, with minor variations or additions, to other languages.[5]
[edit] Vowels
The vowels and their arrangement are:[6]
| Independent form | Romanized | As diacritic with प | Independent form | Romanized | As diacritic with प | ||
|---|---|---|---|---|---|---|---|
| kaṇṭhya (Guttural) |
अ | a | प | आ | ā | पा | |
| tālavya (Palatal) |
इ | i | पि | ई | ī | पी | |
| oṣṭhya (Labial) |
उ | u | पु | ऊ | ū | पू | |
| mūrdhanya (Cerebral) |
ऋ | ṛ | पृ | ॠ | ṝ | पॄ | |
| dantya (Dental) |
ऌ | ḷ | पॢ | ॡ | ḹ | पॣ | |
| kaṇṭhatālavya (Palato-Guttural) |
ए | e | पे | ऐ | ai | पै | |
| kaṇṭhoṣṭhya (Labio-Guttural) |
ओ | o | पो | औ | au | पौ |
- Arranged with the vowels are two consonantal diacritics, the final nasal anusvāra ं ṃ and the final fricative visarga ः ḥ (called अं aṃ and अः aḥ). Masica (1991:146) notes of the anusvāra in Sankrit that "there is some controversy as to whether it represents a homorganic nasal consonant [...], a nasalized vowel, a nasalized semivowel, or all these according to context". The visarga represents post-vocalic voiceless glottal fricative [h], in Sanskrit an allophone of s, or less commonly r, usually in word-final position. Some traditions of recitation append an echo of the vowel after the breath:[7] इः [ihi]. Masica (1991:146) considers the visarga along with letters ङ ṅa and ञ ña for the "largely predictable" velar and palatal nasals to be examples of "phonetic overkill in the system".
- Another diacritic is the candrabindu/anunāsika ँ. Salomon (2003:76-77) describes it as a "more emphatic form" of the anusvāra, "sometimes [...] used to mark a true [vowel] nasalization". In a New Indo-Aryan language such as Hindi the distinction is formal: the candrabindu indicates vowel nasalization[8] while the anusvār indicates a homorganic nasal preceding another consonant:[9] e.g. हँसी [ɦə̃si] "laughter, गंगा [gəŋgɑ] "Ganges". When an akshara has a vowel diacritic above the top line, that leaves no room for the candra ("moon") stroke candrabindu, which is dispensed with in favour of the lone dot:[10] हूँ [ɦũ] "am", but हैं [ɦɛ̃] "are". Some writers and typesetters dispense with the "moon" stroke altogether, using only the dot in all situations.[11]
- The avagraha ऽ (usually transliterated with an apostrophe) is a Sanskrit punctuation mark for the elision of a vowel in sandhi: एकोऽयम् ekoyam (< ekas + ayam) "this one". An original long vowel lost to coalescence is sometimes marked with a double avagraha: सदाऽऽत्मा sadātmā (< sadā + ātmā) "always, the self".[12] In Hindi, Snell (2000:77) states that its "main function is to show that a vowel is sustained in a cry or a shout": आईऽऽऽ! āīīī!. In Magahi, which has "quite a number of verbal forms [that] end in that inherent vowel" Verma (2003:501), the avagraha is used to mark the non-elision of word-final inherent a, which otherwise is a modern orthographic convention: बइठऽ baiṭha "sit" versus *बइठ baiṭh
- The syllabic consonants ṝ, ḷ, and ḹ are specific to Sanskrit and not included in the varṇamālā of other languages. The sound represented by ṛ has been lost as well,[clarification needed] and its pronunciation now ranges from [ɾɪ] (Hindi) to [ɾu] (Marathi).
- ḹ is not an actual phoneme of Sanskrit, but rather a graphic convention included among the vowels in order to maintain the symmetry of short–long pairs of letters.[5]
- There are non-regular formations of रु ru and रू rū.
[edit] Consonants
The consonants and their arrangement are:[13]
| sparśa (Stop) |
anunāsika (Nasal) |
antastha (Approximant) |
ūṣma/saṃghashrī (Fricative) |
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Voicing → | aghoṣa | ghoṣa | aghoṣa | ghoṣa | ||||||||||||
| Aspiration → | alpaprāṇa | mahāprāṇa | alpaprāṇa | mahāprāṇa | alpaprāṇa | mahāprāṇa | ||||||||||
| kaṇṭhya (Guttural) |
क | ka /k/ |
ख | kha /kʰ/ |
ग | ga /g/ |
घ | gha /gʱ/ |
ङ | ṅa /ŋ/ |
ह | ha /h,ɦ/ |
||||
| tālavya (Palatal) |
च | ca /c,ʧ/ |
छ | cha /cʰ,ʧʰ/ |
ज | ja /ɟ,ʤ/ |
झ | jha /ɟʱ,ʤʱ/ |
ञ | ña /ɲ/ |
य | ya /j/ |
श | śa /ɕ,ʃ/ |
||
| mūrdhanya (Cerebral) |
ट | ṭa /ʈ/ |
ठ | ṭha /ʈʰ/ |
ड | ḍa /ɖ/ |
ढ | ḍha /ɖʱ/ |
ण | ṇa /ɳ/ |
र | ra /r/ |
ष | ṣa /ʂ/ |
||
| dantya (Dental) |
त | ta /t̪/ |
थ | tha /t̪ʰ/ |
द | da /d̪/ |
ध | dha /d̪ʱ/ |
न | na /n/ |
ल | la /l/ |
स | sa /s/ |
||
| oṣṭhya (Labial) |
प | pa /p/ |
फ | pha /pʰ/ |
ब | ba /b/ |
भ | bha /bʱ/ |
म | ma /m/ |
व | va /ʋ/ |
||||
- Rounding this out where applicable is ळ ḷa /ɺ̡/, which represented the intervocalic lateral flap allophone of the voiced retroflex stop in Vedic Sanskrit, and which is a phoneme in languages such as Marathi and Rajasthani.
- Beyond the Sanskritic set new shapes have rarely been formulated. Masica (1991:146) offers the following, "In any case, according to some, all possible sounds had already been described and provided for in this system, as Sanskrit was the original and perfect language. Hence it was difficult to provide for or even to conceive other sounds, unknown to the phoneticians of Sanskrit." Where foreign borrowings and internal developments did inevitably accrue and arise in New Indo-Aryan languages, they have been either ignored in writing, or dealt through means such as diacritics and ligatures (ignored in recitation).
- The most prolific diacritic has been the subscript nuqtā ़. Hindi uses it for the Persian sounds क़ qa /q/, ख़ xa /x/, ग़ ġa /ɣ/, ज़ za /z/, and फ़ fa /f/, and for the allophonic developments ड़ ṛa /ɽ/ and ढ़ ṛha /ɽʱ/. (Although ऴ ḷha /ɺ̡ʱ/ could also exist but there is no use of it in Hindi.)
- Sindhi's implosives are accommodated with underlining ॒ : ग॒ [ɠə], ज॒ [ʄə], ड॒ [ɗə], ब॒ [ɓə].
- Aspirated sonorants may be represented as conjuncts/ligatures with ह ha: म्ह mha, न्ह nha, ण्ह ṇha, व्ह vha, ल्ह lha, ळ्ह ḷha, र्ह rha.
- Masica (1991:147) notes Marwari as using a special symbol for ḍa [ɗə] (while ड = [ɽə]).
[edit] Conjuncts

- You will only be able to see the ligatures if your system has a Unicode font installed that includes the required ligature glyphs (e.g. one of the TDIL fonts, see "external links" below).
As mentioned, successive consonants lacking a vowel in between them may physically join together as a 'conjunct' or ligature. The government of these clusters ranges from widely to narrowly applicable rules, with special exceptions within. While standardized for the most part, there are certain variations in clustering, of which the Unicode used on this page is just one scheme. The following are a number of rules:
- 24 out of the 36 consonants contain a vertical right stroke (ख, घ, ण etc.). As first or middle fragments/members of a cluster, they lose that stroke. e.g. त + व = त्व, ण + ढ = ण्ढ, स + थ = स्थ. श ś(a) appears as a different, simple ribbon-shaped fragment preceding व va, न na, च ca, ल la, and र ra, squishing down these second members. Thus श्व śva, श्न śna, श्च śca श्ल śla, and श्र śra.
- र r(a) as a first member takes the form of a curved upward dash above the final character or its ā-diacritic. e.g. र्व rva, र्वा rvā, र्स्प rspa, र्स्पा rspā. As a final member with ट ठ ड ढ ङ छ it is two lines below the character, pointed downwards and apart. Thus ट्र ठ्र ड्र ढ्र ङ्र छ्र. Elsewhere as a final member it is a diagonal stroke jutting leftwards and down. e.g. क्र ग्र भ्र. त ta is shifted up to make त्र tra.
- As first members, remaining vertical stroke-less characters such as द d(a) and ह h(a) may have their second member, shrunken and minus its horizontal stroke, placed underneath. क k(a), छ ch(a), and फ ph(a) shorten their right hooks and join them directly to the following member.
- The conjuncts for kṣ and jñ are not clearly derived from the letters making up their components. The conjunct for kṣ is क्ष (क् + ष)and for jñ it is ज्ञ (ज् + ञ).
The table below shows all the 1296 viable symbols for the biconsonantal clusters formed by collating the 36 fundamental symbols of Sanskrit as listed in Masica (1991:161-162). Scroll your cursor over the conjuncts to reveal their romanizations (in IAST-International Alphabet of Sanskrit Transliteration) and IPA pronunciations.
[edit] Biconsonantal conjuncts
| क | ख | ग | घ | ङ | च | छ | ज | झ | ञ | ट | ठ | ड | ढ | ण | त | थ | द | ध | न | प | फ | ब | भ | म | य | र | ल | व | श | ष | स | ह | ळ | क्ष | ज्ञ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| क | क्क | क्ख | क्ग | क्घ | क्ङ | क्च | क्छ | क्ज | क्झ | क्ञ | क्ट | क्ठ | क्ड | क्ढ | क्ण | क्त | क्थ | क्द | क्ध | क्न | क्प | क्फ | क्ब | क्भ | क्म | क्य | क्र | क्ल | क्व | क्श | क्ष | क्स | क्ह | क्ळ | क्क्ष | क्ज्ञ |
| ख | ख्क | ख्ख | ख्ग | ख्घ | ख्ङ | ख्च | ख्छ | ख्ज | ख्झ | ख्ञ | ख्ट | ख्ठ | ख्ड | ख्ढ | ख्ण | ख्त | ख्थ | ख्द | ख्ध | ख्न | ख्प | ख्फ | ख्ब | ख्भ | ख्म | ख्य | ख्र | ख्ल | ख्व | ख्श | ख्ष | ख्स | ख्ह | ख्ळ | ख्क्ष | ख्ज्ञ |
| ग | ग्क | ग्ख | ग्ग | ग्घ | ग्ङ | ग्च | ग्छ | ग्ज | ग्झ | ग्ञ | ग्ट | ग्ठ | ग्ड | ग्ढ | ग्ण | ग्त | ग्थ | ग्द | ग्ध | ग्न | ग्प | ग्फ | ग्ब | ग्भ | ग्म | ग्य | ग्र | ग्ल | ग्व | ग्श | ग्ष | ग्स | ग्ह | ग्ळ | ग्क्ष | ग्ज्ञ |
| घ | घ्क | घ्ख | घ्ग | घ्घ | घ्ङ | घ्च | घ्छ | घ्ज | घ्झ | घ्ञ | घ्ट | घ्ठ | घ्ड | घ्ढ | घ्ण | घ्त | घ्थ | घ्द | घ्ध | घ्न | घ्प | घ्फ | घ्ब | घ्भ | घ्म | घ्य | घ्र | घ्ल | घ्व | घ्श | घ्ष | घ्स | घ्ह | घ्ळ | घ्क्ष | घ्ज्ञ |
| ङ | ङ्क | ङ्ख | ङ्ग | ङ्घ | ङ्ङ | ङ्च | ङ्छ | ङ्ज | ङ्झ | ङ्ञ | ङ्ट | ङ्ठ | ङ्ड | ङ्ढ | ङ्ण | ङ्त | ङ्थ | ङ्द | ङ्ध | ङ्न | ङ्प | ङ्फ | ङ्ब | ङ्भ | ङ्म | ङ्य | ङ्र | ङ्ल | ङ्व | ङ्श | ङ्ष | ङ्स | ङ्ह | ङ्ळ | ङ्क्ष | ङ्ज्ञ |
| च | च्क | च्ख | च्ग | च्घ | च्ङ | च्च | च्छ | च्ज | च्झ | च्ञ | च्ट | च्ठ | च्ड | च्ढ | च्ण | च्त | च्थ | च्द | च्ध | च्न | च्प | च्फ | च्ब | च्भ | च्म | च्य | च्र | च्ल | च्व | च्श | च्ष | च्स | च्ह | च्ळ | च्क्ष | च्ज्ञ |
| छ | छ्क | छ्ख | छ्ग | छ्घ | छ्ङ | छ्च | छ्छ | छ्ज | छ्झ | छ्ञ | छ्ट | छ्ठ | छ्ड | छ्ढ | छ्ण | छ्त | छ्थ | छ्द | छ्ध | छ्न | छ्प | छ्फ | छ्ब | छ्भ | छ्म | छ्य | छ्र | छ्ल | छ्व | छ्श | छ्ष | छ्स | छ्ह | छ्ळ | छ्क्ष | छ्ज्ञ |
| ज | ज्क | ज्ख | ज्ग | ज्घ | ज्ङ | ज्च | ज्छ | ज्ज | ज्झ | ज्ञ | ज्ट | ज्ठ | ज्ड | ज्ढ | ज्ण | ज्त | ज्थ | ज्द | ज्ध | ज्न | ज्प | ज्फ | ज्ब | ज्भ | ज्म | ज्य | ज्र | ज्ल | ज्व | ज्श | ज्ष | ज्स | ज्ह | ज्ळ | ज्क्ष | ज्ज्ञ |
| झ | झ्क | झ्ख | झ्ग | झ्घ | झ्ङ | झ्च | झ्छ | झ्ज | झ्झ | झ्ञ | झ्ट | झ्ठ | झ्ड | झ्ढ | झ्ण | झ्त | झ्थ | झ्द | झ्ध | झ्न | झ्प | झ्फ | झ्ब | झ्भ | झ्म | झ्य | झ्र | झ्ल | झ्व | झ्श | झ्ष | झ्स | झ्ह | झ्ळ | झ्क्ष | झ्ज्ञ |
| ञ | ञ्क | ञ्ख | ञ्ग | ञ्घ | ञ्ङ | ञ्च | ञ्छ | ञ्ज | ञ्झ | ञ्ञ | ञ्ट | ञ्ठ | ञ्ड | ञ्ढ | ञ्ण | ञ्त | ञ्थ | ञ्द | ञ्ध | ञ्न | ञ्प | ञ्फ | ञ्ब | ञ्भ | ञ्म | ञ्य | ञ्र | ञ्ल | ञ्व | ञ्श | ञ्ष | ञ्स | ञ्ह | ञ्ळ | ञ्क्ष | ञ्ज्ञ |
| ट | ट्क | ट्ख | ट्ग | ट्घ | ट्ङ | ट्च | ट्छ | ट्ज | ट्झ | ट्ञ | ट्ट | ट्ठ | ट्ड | ट्ढ | ट्ण | ट्त | ट्थ | ट्द | ट्ध | ट्न | ट्प | ट्फ | ट्ब | ट्भ | ट्म | ट्य | ट्र | ट्ल | ट्व | ट्श | ट्ष | ट्स | ट्ह | ट्ळ | ट्क्ष | ट्ज्ञ |
| ठ | ठ्क | ठ्ख | ठ्ग | ठ्घ | ठ्ङ | ठ्च | ठ्छ | ठ्ज | ठ्झ | ठ्ञ | ठ्ट | ठ्ठ | ठ्ड | ठ्ढ | ठ्ण | ठ्त | ठ्थ | ठ्द | ठ्ध | ठ्न | ठ्प | ठ्फ | ठ्ब | ठ्भ | ठ्म | ठ्य | ठ्र | ठ्ल | ठ्व | ठ्श | ठ्ष | ठ्स | ठ्ह | ठ्ळ | ठ्क्ष | ठ्ज्ञ |
| ड | ड्क | ड्ख | ड्ग | ड्घ | ड्ङ | ड्च | ड्छ | ड्ज | ड्झ | ड्ञ | ड्ट | ड्ठ | ड्ड | ड्ढ | ड्ण | ड्त | ड्थ | ड्द | ड्ध | ड्न | ड्प | ड्फ | ड्ब | ड्भ | ड्म | ड्य | ड्र | ड्ल | ड्व | ड्श | ड्ष | ड्स | ड्ह | ड्ळ | ड्क्ष | ड्ज्ञ |
| ढ | ढ्क | ढ्ख | ढ्ग | ढ्घ | ढ्ङ | ढ्च | ढ्छ | ढ्ज | ढ्झ | ढ्ञ | ढ्ट | ढ्ठ | ढ्ड | ढ्ढ | ढ्ण | ढ्त | ढ्थ | ढ्द | ढ्ध | ढ्न | ढ्प | ढ्फ | ढ्ब | ढ्भ | ढ्म | ढ्य | ढ्र | ढ्ल | ढ्व | ढ्श | ढ्ष | ढ्स | ढ्ह | ढ्ळ | ढ्क्ष | ढ्ज्ञ |
| ण | ण्क | ण्ख | ण्ग | ण्घ | ण्ङ | ण्च | ण्छ | ण्ज | ण्झ | ण्ञ | ण्ट | ण्ठ | ण्ड | ण्ढ | ण्ण | ण्त | ण्थ | ण्द | ण्ध | ण्न | ण्प | ण्फ | ण्ब | ण्भ | ण्म | ण्य | ण्र | ण्ल | ण्व | ण्श | ण्ष | ण्स | ण्ह | ण्ळ | ण्क्ष | ण्ज्ञ |
| त | त्क | त्ख | त्ग | त्घ | त्ङ | त्च | त्छ | त्ज | त्झ | त्ञ | त्ट | त्ठ | त्ड | त्ढ | त्ण | त्त | त्थ | त्द | त्ध | त्न | त्प | त्फ | त्ब | त्भ | त्म | त्य | त्र | त्ल | त्व | त्श | त्ष | त्स | त्ह | त्ळ | त्क्ष | त्ज्ञ |
| थ | थ्क | थ्ख | थ्ग | थ्घ | थ्ङ | थ्च | थ्छ | थ्ज | थ्झ | थ्ञ | थ्ट | थ्ठ | थ्ड | थ्ढ | थ्ण | थ्त | थ्थ | थ्द | थ्ध | थ्न | थ्प | थ्फ | थ्ब | थ्भ | थ्म | थ्य | थ्र | थ्ल | थ्व | थ्श | थ्ष | थ्स | थ्ह | थ्ळ | थ्क्ष | थ्ज्ञ |
| द | द्क | द्ख | द्ग | द्घ | द्ङ | द्च | द्छ | द्ज | द्झ | द्ञ | द्ट | द्ठ | द्ड | द्ढ | द्ण | द्त | द्थ | द्द | द्ध | द्न | द्प | द्फ | द्ब | द्भ | द्म | द्य | द्र | द्ल | द्व | द्श | द्ष | द्स | द्ह | द्ळ | द्क्ष | द्ज्ञ |
| ध | ध्क | ध्ख | ध्ग | ध्घ | ध्ङ | ध्च | ध्छ | ध्ज | ध्झ | ध्ञ | ध्ट | ध्ठ | ध्ड | ध्ढ | ध्ण | ध्त | ध्थ | ध्द | ध्ध | ध्न | ध्प | ध्फ | ध्ब | ध्भ | ध्म | ध्य | ध्र | ध्ल | ध्व | ध्श | ध्ष | ध्स | ध्ह | ध्ळ | ध्क्ष | ध्ज्ञ |
| न | न्क | न्ख | न्ग | न्घ | न्ङ | न्च | न्छ | न्ज | न्झ | न्ञ | न्ट | न्ठ | न्ड | न्ढ | न्ण | न्त | न्थ | न्द | न्ध | न्न | न्प | न्फ | न्ब | न्भ | न्म | न्य | न्र | न्ल | न्व | न्श | न्ष | न्स | न्ह | न्ळ | न्क्ष | न्ज्ञ |
| प | प्क | प्ख | प्ग | प्घ | प्ङ | प्च | प्छ | प्ज | प्झ | प्ञ | प्ट | प्ठ | प्ड | प्ढ | प्ण | प्त | प्थ | प्द | प्ध | प्न | प्प | प्फ | प्ब | प्भ | प्म | प्य | प्र | प्ल | प्व | प्श | प्ष | प्स | प्ह | प्ळ | प्क्ष | प्ज्ञ |
| फ | फ्क | फ्ख | फ्ग | फ्घ | फ्ङ | फ्च | फ्छ | फ्ज | फ्झ | फ्ञ | फ्ट | फ्ठ | फ्ड | फ्ढ | फ्ण | फ्त | फ्थ | फ्द | फ्ध | फ्न | फ्प | फ्फ | फ्ब | फ्भ | फ्म | फ्य | फ्र | फ्ल | फ्व | फ्श | फ्ष | फ्स | फ्ह | फ्ळ | फ्क्ष | फ्ज्ञ |
| ब | ब्क | ब्ख | ब्ग | ब्घ | ब्ङ | ब्च | ब्छ | ब्ज | ब्झ | ब्ञ | ब्ट | ब्ठ | ब्ड | ब्ढ | ब्ण | ब्त | ब्थ | ब्द | ब्ध | ब्न | ब्प | ब्फ | ब्ब | ब्भ | ब्म | ब्य | ब्र | ब्ल | ब्व | ब्श | ब्ष | ब्स | ब्ह | ब्ळ | ब्क्ष | ब्ज्ञ |
| भ | भ्क | भ्ख | भ्ग | भ्घ | भ्ङ | भ्च | भ्छ | भ्ज | भ्झ | भ्ञ | भ्ट | भ्ठ | भ्ड | भ्ढ | भ्ण | भ्त | भ्थ | भ्द | भ्ध | भ्न | भ्प | भ्फ | भ्ब | भ्भ | भ्म | भ्य | भ्र | भ्ल | भ्व | भ्श | भ्ष | भ्स | भ्ह | भ्ळ | भ्क्ष | भ्ज्ञ |
| म | म्क | म्ख | म्ग | म्घ | म्ङ | म्च | म्छ | म्ज | म्झ | म्ञ | म्ट | म्ठ | म्ड | म्ढ | म्ण | म्त | म्थ | म्द | म्ध | म्न | म्प | म्फ | म्ब | म्भ | म्म | म्य | म्र | म्ल | म्व | म्श | म्ष | म्स | म्ह | म्ळ | म्क्ष | म्ज्ञ |
| य | य्क | य्ख | य्ग | य्घ | य्ङ | य्च | य्छ | य्ज | य्झ | य्ञ | य्ट | य्ठ | य्ड | य्ढ | य्ण | य्त | य्थ | य्द | य्ध | य्न | य्प | य्फ | य्ब | य्भ | य्म | य्य | य्र | य्ल | य्व | य्श | य्ष | य्स | य्ह | य्ळ | य्क्ष | य्ज्ञ |
| र | र्क | र्ख | र्ग | र्घ | र्ङ | र्च | र्छ | र्ज | र्झ | र्ञ | र्ट | र्ठ | र्ड | र्ढ | र्ण | र्त | र्थ | र्द | र्ध | र्न | र्प | र्फ | र्ब | र्भ | र्म | र्य | र्र | र्ल | र्व | र्श | र्ष | र्स | र्ह | र्ळ | र्क्ष | र्ज्ञ |
| ल | ल्क | ल्ख | ल्ग | ल्घ | ल्ङ | ल्च | ल्छ | ल्ज | ल्झ | ल्ञ | ल्ट | ल्ठ | ल्ड | ल्ढ | ल्ण | ल्त | ल्थ | ल्द | ल्ध | ल्न | ल्प | ल्फ | ल्ब | ल्भ | ल्म | ल्य | ल्र | ल्ल | ल्व | ल्श | ल्ष | ल्स | ल्ह | ल्ळ | ल्क्ष | ल्ज्ञ |
| व | व्क | व्ख | व्ग | व्घ | व्ङ | व्च | व्छ | व्ज | व्झ | व्ञ | व्ट | व्ठ | व्ड | व्ढ | व्ण | व्त | व्थ | व्द | व्ध | व्न | व्प | व्फ | व्ब | व्भ | व्म | व्य | व्र | व्ल | व्व | व्श | व्ष | व्स | व्ह | व्ळ | व्क्ष | व्ज्ञ |
| श | श्क | श्ख | श्ग | श्घ | श्ङ | श्च | श्छ | श्ज | श्झ | श्ञ | श्ट | श्ठ | श्ड | श्ढ | श्ण | श्त | श्थ | श्द | श्ध | श्न | श्प | श्फ | श्ब | श्भ | श्म | श्य | श्र | श्ल | श्व | श्श | श्ष | श्स | श्ह | श्ळ | श्क्ष | श्ज्ञ |
| ष | ष्क | ष्ख | ष्ग | ष्घ | ष्ङ | ष्च | ष्छ | ष्ज | ष्झ | ष्ञ | ष्ट | ष्ठ | ष्ड | ष्ढ | ष्ण | ष्त | ष्थ | ष्द | ष्ध | ष्न | ष्प | ष्फ | ष्ब | ष्भ | ष्म | ष्य | ष्र | ष्ल | ष्व | ष्श | ष्ष | ष्स | ष्ह | ष्ळ | ष्क्ष | ष्ज्ञ |
| स | स्क | स्ख | स्ग | स्घ | स्ङ | स्च | स्छ | स्ज | स्झ | स्ञ | स्ट | स्ठ | स्ड | स्ढ | स्ण | स्त | स्थ | स्द | स्ध | स्न | स्प | स्फ | स्ब | स्भ | स्म | स्य | स्र | स्ल | स्व | स्श | स्ष | स्स | स्ह | स्ळ | स्क्ष | स्ज्ञ |
| ह | ह्क | ह्ख | ह्ग | ह्घ | ह्ङ | ह्च | ह्छ | ह्ज | ह्झ | ह्ञ | ह्ट | ह्ठ | ह्ड | ह्ढ | ह्ण | ह्त | ह्थ | ह्द | ह्ध | ह्न | ह्प | ह्फ | ह्ब | ह्भ | ह्म | ह्य | ह्र | ह्ल | ह्व | ह्श | ह्ष | ह्स | ह्ह | ह्ळ | ह्क्ष | ह्ज्ञ |
| ळ | ळ्क | ळ्ख | ळ्ग | ळ्घ | ळ्ङ | ळ्च | ळ्छ | ळ्ज | ळ्झ | ळ्ञ | ळ्ट | ळ्ठ | ळ्ड | ळ्ढ | ळ्ण | ळ्त | ळ्थ | ळ्द | ळ्ध | ळ्न | ळ्प | ळ्फ | ळ्ब | ळ्भ | ळ्म | ळ्य | ळ्र | ळ्ल | ळ्व | ळ्श | ळ्ष | ळ्स | ळ्ह | ळ्ळ | ळ्क्ष | ळ्ज्ञ |
| क्ष | क्ष्क | क्ष्ख | क्ष्ग | क्ष्घ | क्ष्ङ | क्ष्च | क्ष्छ | क्ष्ज | क्ष्झ | क्ष्ञ | क्ष्ट | क्ष्ठ | क्ष्ड | क्ष्ढ | क्ष्ण | क्ष्त | क्ष्थ | क्ष्द | क्ष्ध | क्ष्न | क्ष्प | क्ष्फ | क्ष्ब | क्ष्भ | क्ष्म | क्ष्य | क्ष्र | क्ष्ल | क्ष्व | क्ष्श | क्ष्ष | क्ष्स | क्ष्ह | क्ष्ळ | क्ष्क्ष | क्ष्ज्ञ |
| ज्ञ | ज्ञ्क | ज्ञ्ख | ज्ञ्ग | ज्ञ्घ | ज्ञ्ङ | ज्ञ्च | ज्ञ्छ | ज्ञ्ज | ज्ञ्झ | ज्ञ्ञ | ज्ञ्ट | ज्ञ्ठ | ज्ञ्ड | ज्ञ्ढ | ज्ञ्ण | ज्ञ्त | ज्ञ्थ | ज्ञ्द | ज्ञ्ध | ज्ञ्न | ज्ञ्प | ज्ञ्फ | ज्ञ्ब | ज्ञ्भ | ज्ञ्म | ज्ञ्य | ज्ञ्र | ज्ञ्ल | ज्ञ्व | ज्ञ्श | ज्ञ्ष | ज्ञ्स | ज्ञ्ह | ज्ञ्ळ | ज्ञ्क्ष | ज्ञ्ज्ञ |
New Indo-Aryan languages may use the above forms for their Sanskrit loanwords (or otherwise).
[edit] Accent marks
The pitch accent of Vedic Sanskrit is written with various symbols depending on shakha. In the Rigveda, anudātta is written with a bar below the line (॒), svarita with a stroke above the line (॑) while udātta is unmarked.
[edit] Punctuation
| This section requires expansion. |
The end of a sentence or half-verse may be marked with a danda or vertical line: "I". The end of a full verse may be marked with a double danda or two vertical lines: "II".
[edit] Numerals
| ० | १ | २ | ३ | ४ | ५ | ६ | ७ | ८ | ९ |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
[edit] Transliteration
There are several methods of transliteration from Devanāgarī into Roman scripts. The most widely used transliteration method is IAST. However, there are other transliteration options.
The following are the major transliteration methods for Devanāgarī:
[edit] ISO 15919
A standard transliteration convention was codified in the ISO 15919 standard of 2001. It uses diacritics to map the much larger set of Brahmic graphemes to the Latin script. See also Transliteration of Indic scripts: how to use ISO 15919. The Devanāgarī-specific portion is nearly identical to the academic standard for Sanskrit, IAST.
[edit] IAST
The International Alphabet of Sanskrit Transliteration (IAST) is the academic standard for the romanization of Sanskrit. IAST is the de-facto standard used in printed publications, like books and magazines, and with the wider availability of Unicode fonts, it is also increasingly used for electronic texts. It is based on a standard established by the Congress of Orientalists at Athens in 1912.
The National Library at Kolkata romanization, intended for the romanization of all Indic scripts, is an extension of IAST.
[edit] Harvard-Kyoto
Compared to IAST, Harvard-Kyoto looks much simpler. It does not contain all the diacritic marks that IAST contains. This makes typing in Harvard-Kyoto much easier than IAST. Harvard-Kyoto uses capital letters that can be difficult to read in the middle of words.
[edit] ITRANS
ITRANS is a lossless transliteration scheme of Devanāgarī into ASCII that is widely used on Usenet. It is an extension of the Harvard-Kyoto scheme. In ITRANS, the word Devanāgarī is written as "Devanaagarii". ITRANS is associated with an application of the same name that enables typesetting in Indic scripts. The user inputs in Roman letters and the ITRANS pre-processor displays the Roman letters into Devanāgarī (or other Indic languages). The latest version of ITRANS is version 5.30 released in July, 2001.
[edit] ALA-LC Romanization
ALA-LC romanization is a transliteration scheme approved by the Library of Congress and the American Library Association, and widely used in North American libraries. Transliteration tables are based on languages, so there is a table for Hindi, one for Sanskrit and Prakrit, etc.
[edit] Encodings
[edit] ISCII
ISCII is a fixed-length 8-bit encoding. The lower 128 codepoints are plain ASCII, the upper 128 codepoints are ISCII-specific.
It has been designed for representing not only Devanāgarī, but also various other Indic scripts as well as a Latin-based script with diacritic marks used for transliteration of the Indic scripts.
ISCII has largely been superseded by Unicode, which has however attempted to preserve the ISCII layout for its Indic language blocks.
[edit] Devanāgarī in Unicode
The Unicode range for Devanāgarī is U+0900 .. U+097F. Grey areas indicate non-assigned code points.
| Devanagari Unicode.org chart (PDF) |
||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+090x | ँ | ं | ः | ऄ | अ | आ | इ | ई | उ | ऊ | ऋ | ऌ | ऍ | ऎ | ए | |
| U+091x | ऐ | ऑ | ऒ | ओ | औ | क | ख | ग | घ | ङ | च | छ | ज | झ | ञ | ट |
| U+092x | ठ | ड | ढ | ण | त | थ | द | ध | न | ऩ | प | फ | ब | भ | म | य |
| U+093x | र | ऱ | ल | ळ | ऴ | व | श | ष | स | ह | ़ | ऽ | ा | ि | ||
| U+094x | ी | ु | ू | ृ | ॄ | ॅ | ॆ | े | ै | ॉ | ॊ | ो | ौ | ् | ||
| U+095x | ॐ | ॑ | ॒ | ॓ | ॔ | क़ | ख़ | ग़ | ज़ | ड़ | ढ़ | फ़ | य़ | |||
| U+096x | ॠ | ॡ | ॢ | ॣ | । | ॥ | ० | १ | २ | ३ | ४ | ५ | ६ | ७ | ८ | ९ |
| U+097x | ॰ | ॱ | ॲ | ॻ | ॼ | ॽ | ॾ | ॿ | ||||||||
[edit] Devanāgarī Keyboard Layouts
The Mac OS X operating system supports convenient editing for the Devanāgarī script by insertion of appropriate Unicode characters with two different keyboard layouts available for use. To input Devanāgarī text, one goes to System Preferences → International → Input Menu and enables the keyboard layout that is to be used. The layout is the same as for INSCRIPT/KDE Linux:
[edit] INSCRIPT / KDE Linux

This is the India keyboard layout for Linux (variant 'Deva')
[edit] Typewriter

Computer keyboard with the Hindi typewriter layout is available from Intex Technologies (called Swadeshi). It is a bilingual keyboard with English alphabets markings. See Intex Technologies Swadeshi bilingual keyboard.
[edit] Phonetic
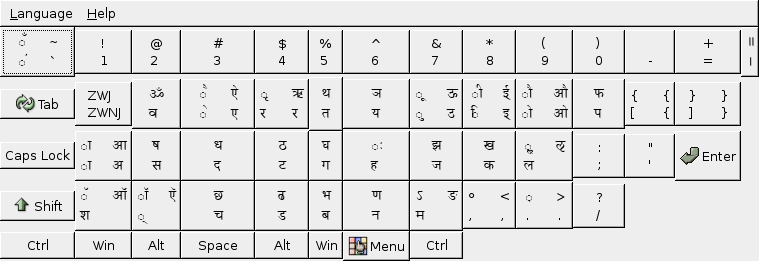
[edit] See also
[edit] Software
- Apple Type Services for Unicode Imaging - Macintosh
- HindiWriter - The Phonetic Hindi Writer with AutoWord lookup and Spellcheck for MS Word and OpenOffice.org for Windows.
- Pango - open source (GNOME)
- Uniscribe - Windows
- WorldScript - Macintosh, replaced by the Apple Type Services for Unicode Imaging, mentioned above
- Baraha - Devanāgarī Input using English Keyboard
- Lipikaar - The indic script typing tool with support for Devanāgarī through a Windows desktop executable or Firefox Extension.
[edit] References
- ^ OED
- ^ Salomon (2003:70)
- ^ http://archives.conlang.info/sae/shaunvhon/fialphonfhoen.html
- ^ Salomon (2003:71)
- ^ a b Salomon (2003:75)
- ^ Wikner (1996:13, 14)
- ^ Wikner (1996:6)
- ^ Snell (2000:44-45)
- ^ Snell (2000:64)
- ^ Snell (2000:45)
- ^ Snell (2000:46)
- ^ Salomon (2003:77)
- ^ Wikner (1996:73)
[edit] Bibliography
- Masica, Colin (1991), written at Cambridge, The Indo-Aryan Languages, Cambridge University Press, ISBN 9780521299442, <http://books.google.com/books?id=J3RSHWePhXwC&printsec=frontcover&dq=indo-aryan+languages>.
- Snell, Rupert (2000), Teach Yourself Beginner's Hindi Script, Hodder & Stoughton, ISBN 9780071419840.
- Salomon, Richard (2003), "Writing Systems of the Indo-Aryan Languages", in Cardona, George & Dhanesh Jain, The Indo-Aryan Languages, Routledge, 67-103, ISBN 9780415772945.
- Verma, Sheela (2003), "Magahi", in Cardona, George & Dhanesh Jain, The Indo-Aryan Languages, Routledge, 498-514, ISBN 9780415772945.
- Wikner, Charles (1996), A Practical Sanskrit Introductory, <http://sanskritdocuments.org/learning_tutorial_wikner/index.html>.
[edit] External links
| Wikibooks has a book on the topic of |
- Hindi Computing Wiki - Sarvagya (सर्वज्ञ)
- Omniglot.com - Devanāgarī Alphabets including classical/northern variant forms of अ (a) and related letters, झ (jh), ण (ṇ)
- Devanagari/Sanskrit alphabet with Unicode values and an extensive list of conjuncts
- AncientScripts.com - Devanāgarī Intro
- IS13194:1991 [1]
- Nepali Traditional keyboard Layout
- Nepali Romanized keyboard Layout
[edit] Electronic typesetting
[edit] Fonts
- Unicode Compliant Open Type Fonts including ligature glyphs (TDIL Data Centre)
- Unicode Devanagari font gallery
- Chandas, Unicode font with all attested ligatures, Vedic signs, and northern/southern variants, with links to other fonts
- Mangal font (article in Sandbox)
[edit] Documentation
- The official Devanāgarī Document (pdf) from Govt. Of India.
- Unicode Chart for Devanāgarī
- Resources for typing in the Nepali language in Devanāgarī
- Resources for viewing and editing Devanāgarī
- Unicode support for Web browsers
- Creating and Viewing Documents in Devanāgarī
- Hindi/Devanāgarī Script Tutor
- A compilation of Tools and Techniques for Hindi Computing
[edit] Tools and applications
- Intex Technologies Swadeshi bilingual keyboard
- List of Hindi Typing Tools
- IndiX, Indian language support for Linux, a site by the Indian National Centre for Software Technology
- Devanāgarī Tools: Wiki Sandbox, Devanāgarī Mail, Yahoo/Google Search & Devanāgarī Transliteration
- EnTrans - Entrans is an online, collaborative translation tool
- Online Latin to Devanāgarī transliteration tool
|
||||||||||||||||||||
|
|||||
|
|||||||||||


{kind=link}
{kind=link}