Naive set theory
From Wikipedia, the free encyclopedia
Naive set theory is one of several theories of sets used in the discussion of the foundations of mathematics.[1] The informal content of this naive set theory supports both the aspects of mathematical sets familiar in discrete mathematics (for example Venn diagrams and symbolic reasoning about their Boolean algebra), and the everyday usage of set theory concepts in most contemporary mathematics.
Sets are of great importance in mathematics; in fact, in modern formal treatments, most mathematical objects (numbers, relations, functions, etc.) are defined in terms of sets. Naive set theory can be seen as a stepping-stone to more formal treatments, and suffices for many purposes.
Contents |
[edit] Requirements
A naive theory is a non-formalized theory, that is to say a theory that uses a natural language to describe sets. The words and, or, if ... then, not, for some, for every are not subject to rigorous definition. It is useful to study sets naively at an early stage of mathematics in order to develop facility for working with them. Furthermore, a firm grasp of set theoretical concepts from a naive standpoint is important as a first stage in understanding the motivation for the formal axioms of set theory.
This article develops a naive theory. Sets are defined informally and a few of their properties are investigated. Links in this article to specific axioms of set theory describe some of the relationships between the informal discussion here and the formal axiomatization of set theory, but no attempt is made to justify every statement on such a basis. The first development of set theory was a naive set theory. It was created at the end of the 19th century by Georg Cantor in order to allow mathematicians to work with infinite sets consistently.
As it turned out, assuming that one could perform any operations on sets without restriction led to paradoxes such as Russell's paradox or Berry's paradox. In response, axiomatic set theory was developed to determine precisely what operations were allowed and when. Today, when mathematicians talk about "set theory" as a field, they usually mean axiomatic set theory. Informal applications of set theory in other fields are sometimes referred to as applications of "naive set theory", but usually are understood to be justifiable in terms of an axiomatic system (normally the Zermelo–Fraenkel set theory). Some believe that Georg Cantor's set theory was not actually implicated in the paradoxes (this is a matter which continues to be discussed).[citation needed] He was aware of some of them and did not appear to believe that they discredited his theory. It is hard to be sure of this because he did not give an axiomatization. Frege did explicitly axiomatize a theory, in which the formalized version of naive set theory can be interpreted, and it is this formal theory which Bertrand Russell actually addressed when he presented his paradox.
These early attempts therefore led to inconsistency. A naive set theory is not necessarily inconsistent, if it correctly specifies the sets allowed to be considered. This can be done by the means of definitions, which are implicit axioms. It can be done by systematically making explicit all the axioms, as in the case of the well-known book Naive Set Theory by Paul Halmos, which is actually a somewhat (not all that) informal presentation of the usual axiomatic Zermelo–Fraenkel set theory. It is 'naive' in that the language and notations are those of ordinary informal mathematics, and in that it doesn't deal with consistency or completeness of the axiom system.
[edit] Sets, membership and equality
In naive set theory, a set is described as a well-defined collection of objects. These objects are called the elements or members of the set. Objects can be anything: numbers, people, other sets, etc. For instance, 4 is a member of the set of all even integers. Clearly, the set of even numbers is infinitely large; there is no requirement that a set be finite.
If x is a member of A, then it is also said that x belongs to A, or that x is in A. In this case, we write x ∈ A. (The symbol ∈ is a derivation from the Greek letter epsilon, "ε", introduced by Peano in 1888.) The symbol ∉ is sometimes used to write x ∉ A, meaning "x is not in A".
Two sets A and B are defined to be equal when they have precisely the same elements, that is, if every element of A is an element of B and every element of B is an element of A. (See axiom of extensionality.) Thus a set is completely determined by its elements; the description is immaterial. For example, the set with elements 2, 3, and 5 is equal to the set of all prime numbers less than 6. If the sets A and B are equal, this is denoted symbolically as A = B (as usual).
We also allow for an empty set, often denoted Ø and sometimes {}: a set without any members at all. Since a set is determined completely by its elements, there can only be one empty set. (See axiom of empty set.) Note that  .
.
[edit] Specifying sets
The simplest way to describe a set is to list its elements between curly braces (known as defining a set extensionally). Thus {1,2} denotes the set whose only elements are 1 and 2. (See axiom of pairing.) Note the following points:
- Order of elements is immaterial; for example, {1,2} = {2,1}.
- Repetition (multiplicity) of elements is irrelevant; for example, {1,2,2} = {1,1,1,2} = {1,2}.
(These are consequences of the definition of equality in the previous section.)
This notation can be informally abused by saying something like {dogs} to indicate the set of all dogs, but this example would usually be read by mathematicians as "the set containing the single element dogs".
An extreme (but correct) example of this notation is {}, which denotes the empty set.
We can also use the notation {x : P(x)}, or sometimes {x | P(x)}, to denote the set containing all objects for which the condition P holds (known as defining a set intensionally). For example, {x : x is a real number} denotes the set of real numbers, {x : x has blonde hair} denotes the set of everything with blonde hair, and {x : x is a dog} denotes the set of all dogs.
This notation is called set-builder notation (or "set comprehension", particularly in the context of Functional programming). Some variants of set builder notation are:
- {x ∈ A : P(x)} denotes the set of all x that are already members of A such that the condition P holds for x. For example, if Z is the set of integers, then {x ∈ Z : x is even} is the set of all even integers. (See axiom of specification.)
- {F(x) : x ∈ A} denotes the set of all objects obtained by putting members of the set A into the formula F. For example, {2x : x ∈ Z} is again the set of all even integers. (See axiom of replacement.)
- {F(x) : P(x)} is the most general form of set builder notation. For example, {x's owner : x is a dog} is the set of all dog owners.
[edit] Subsets
Given two sets A and B we say that A is a subset of B if every element of A is also an element of B. Notice that in particular, B is a subset of itself; a subset of B that isn't equal to B is called a proper subset.
If A is a subset of B, then one can also say that B is a superset of A, that A is contained in B, or that B contains A. In symbols, A ⊆ B means that A is a subset of B, and B ⊇ A means that B is a superset of A. Some authors use the symbols "⊂" and "⊃" for subsets, and others use these symbols only for proper subsets. For clarity, one can explicitly use the symbols "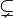 " and "
" and " " to indicate non-equality.
" to indicate non-equality.
As an illustration, let R be the set of real numbers, let Z be the set of integers, let O be the set of odd integers, and let P be the set of current or former U.S. Presidents. Then O is a subset of Z, Z is a subset of R, and (hence) O is a subset of R, where in all cases subset may even be read as proper subset. Note that not all sets are comparable in this way. For example, it is not the case either that R is a subset of P nor that P is a subset of R.
It follows immediately from the definition of equality of sets above that, given two sets A and B, A = B if and only if A ⊆ B and B ⊆ A. In fact this is often given as the definition of equality. Usually when trying to prove that two sets are equal, one aims to show these two inclusions. Note that the empty set is a subset of every set (the statement that all elements of the empty set are also members of any set A is vacuously true).
The set of all subsets of a given set A is called the power set of A and is denoted by 2A or P(A); the "P" is sometimes in a fancy font. If the set A has n elements, then P(A) will have 2n elements.
[edit] Universal sets and absolute complements
In certain contexts we may consider all sets under consideration as being subsets of some given universal set. For instance, if we are investigating properties of the real numbers R (and subsets of R), then we may take R as our universal set. A universal set is only temporarily defined by the context; there is no such thing as a "universal" universal set, "the set of everything" (see Paradoxes below).
Given a universal set U and a subset A of U, we may define the complement of A (in U) as
- AC := {x ∈ U : x ∉ A}.
In other words, AC ("A-complement"; sometimes simply A', "A-prime" ) is the set of all members of U which are not members of A. Thus with R, Z and O defined as in the section on subsets, if Z is the universal set, then OC is the set of even integers, while if R is the universal set, then OC is the set of all real numbers that are either even integers or not integers at all.
[edit] Unions, intersections, and relative complements
Given two sets A and B, we may construct their union. This is the set consisting of all objects which are elements of A or of B or of both (see axiom of union). It is denoted by A ∪ B.
The intersection of A and B is the set of all objects which are both in A and in B. It is denoted by A ∩ B.
Finally, the relative complement of B relative to A, also known as the set theoretic difference of A and B, is the set of all objects that belong to A but not to B. It is written as A \ B or A − B. Symbolically, these are respectively
- A ∪ B := {x : (x ∈ A) or (x ∈ B)};
- A ∩ B := {x : (x ∈ A) and (x ∈ B)} = {x ∈ A : x ∈ B} = {x ∈ B : x ∈ A};
- A \ B := {x : (x ∈ A) and not (x ∈ B) } = {x ∈ A : not (x ∈ B)}.
Notice that A doesn't have to be a subset of B for B \ A to make sense; this is the difference between the relative complement and the absolute complement from the previous section.
To illustrate these ideas, let A be the set of left-handed people, and let B be the set of people with blond hair. Then A ∩ B is the set of all left-handed blond-haired people, while A ∪ B is the set of all people who are left-handed or blond-haired or both. A \ B, on the other hand, is the set of all people that are left-handed but not blond-haired, while B \ A is the set of all people who have blond hair but aren't left-handed.
Now let E be the set of all human beings, and let F be the set of all living things over 1000 years old. What is E ∩ F in this case? No human being is over 1000 years old, so E ∩ F must be the empty set {}.
For any set A, the power set P(A) is a Boolean algebra under the operations of union and intersection.
[edit] Ordered pairs and Cartesian products
Intuitively, an ordered pair is simply a collection of two objects such that one can be distinguished as the first element and the other as the second element, and having the fundamental property that, two ordered pairs are equal if and only if their first elements are equal and their second elements are equal.
Formally, an ordered pair with first coordinate a, and second coordinate b, usually denoted by (a, b), is defined as the set {{a}, {a, b}}.
It follows that, two ordered pairs (a,b) and (c,d) are equal if and only if a = c and b = d.
Alternatively, an ordered pair can be formally thought of as a set {a,b} with a total order.
(The notation (a, b) is also used to denote an open interval on the real number line, but the context should make it clear which meaning is intended. Otherwise, the notation ]a, b[ may be used to denote the open interval whereas (a, b) is used for the ordered pair).
If A and B are sets, then the Cartesian product (or simply product) is defined to be:
- A × B = {(a,b) : a is in A and b is in B}.
That is, A × B is the set of all ordered pairs whose first coordinate is an element of A and whose second coordinate is an element of B.
We can extend this definition to a set A × B × C of ordered triples, and more generally to sets of ordered n-tuples for any positive integer n. It is even possible to define infinite Cartesian products, but to do this we need a more recondite definition of the product.
Cartesian products were first developed by René Descartes in the context of analytic geometry. If R denotes the set of all real numbers, then R2 := R × R represents the Euclidean plane and R3 := R × R × R represents three-dimensional Euclidean space.
[edit] Some important sets
Note: In this section, a, b, and c are natural numbers, and r and s are real numbers.
- Natural numbers are used for counting. A blackboard bold capital N (
 ) often represents this set.
) often represents this set. - Integers appear as solutions for x in equations like x + a = b. A blackboard bold capital Z (
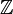 ) often represents this set (from the German Zahlen, meaning numbers).
) often represents this set (from the German Zahlen, meaning numbers). - Rational numbers appear as solutions to equations like a + bx = c. A blackboard bold capital Q (
 ) often represents this set (for quotient, because R is used for the set of real numbers).
) often represents this set (for quotient, because R is used for the set of real numbers). - Algebraic numbers appear as solutions to polynomial equations (with integer coefficients) and may involve radicals and certain other irrational numbers. A blackboard bold capital A (
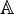 ) or a Q with an overline (
) or a Q with an overline ( ) often represents this set. The overline denotes the operation of algebraic closure.
) often represents this set. The overline denotes the operation of algebraic closure. - Real numbers represent the "real line" and include all numbers that can be approximated by rationals. These numbers may be rational or algebraic but may also be transcendental numbers, which cannot appear as solutions to polynomial equations with rational coefficients. A blackboard bold capital R (
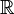 ) often represents this set.
) often represents this set. - Complex numbers are sums of a real and an imaginary number: r + si. Here both r and s can equal zero; thus, the set of real numbers and the set of imaginary numbers are subsets of the set of complex numbers, which form an algebraic closure for the set of real numbers, meaning that every polynomial with coefficients in has at least one root in this set. A blackboard bold capital C (
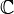 ) often represents this set. Note that since a number r + si can be identified with a point (r, s) in the plane, C is basically "the same" as the Cartesian product R×R ("the same" meaning that any point in one determines a unique point in the other and for the result of calculations it doesn't matter which one is used for the calculation).
) often represents this set. Note that since a number r + si can be identified with a point (r, s) in the plane, C is basically "the same" as the Cartesian product R×R ("the same" meaning that any point in one determines a unique point in the other and for the result of calculations it doesn't matter which one is used for the calculation).
[edit] Paradoxes
We referred earlier to the need for a formal, axiomatic approach. What problems arise in the treatment we have given? The problems relate to the formation of sets. One's first intuition might be that we can form any sets we want, but this view leads to inconsistencies. For any set x we can ask whether x is a member of itself. Define
- Z = {x : x is not a member of x}.
Now for the problem: is Z a member of Z? If yes, then by the defining quality of Z, Z is not a member of itself, i.e., Z is not a member of Z. This forces us to declare that Z is not a member of Z. Then Z is not a member of itself and so, again by definition of Z, Z is a member of Z. Thus both options lead us to a contradiction and we have an inconsistent theory. More succinctly, one says that Z is a member of Z if and only if Z is not a member of Z. Axiomatic developments place restrictions on the sort of sets we are allowed to form and thus prevent problems like our set Z from arising. This particular paradox is Russell's paradox.
The penalty is that one must take more care with one's development, as one must in any rigorous mathematical argument. In particular, it is problematic to speak of a set of everything, or to be (possibly) a bit less ambitious, even a set of all sets. In fact, in the standard axiomatisation of set theory, there is no set of all sets. In areas of mathematics that seem to require a set of all sets (such as category theory), one can sometimes make do with a universal set so large that all of ordinary mathematics can be done within it (see universe). Alternatively, one can make use of proper classes. Or, one can use a different axiomatisation of set theory, such as W. V. Quine's New Foundations, which allows for a set of all sets and avoids Russell's paradox in another way.
[edit] See also
- Algebra of sets
- Axiomatic set theory
- Internal set theory
- Set theory
- Set (mathematics)
- Partially ordered set
- Category:Paradoxes of naive set theory
[edit] References
- Halmos, P.R., Naive Set Theory, D. Van Nostrand Company, Princeton, NJ, 1960. Reprinted, Springer-Verlag, New York, NY, 1974, ISBN 0-387-90092-6.
- Bourbaki, N., Elements of the History of Mathematics, John Meldrum (trans.), Springer-Velag, Berlin, Germany, 1994.
- Devlin, K.J., The Joy of Sets: Fundamentals of Contemporary Set Theory, 2nd edition, Springer-Verlag, New York, NY, 1993.
- van Heijenoort, J., From Frege to Gödel, A Source Book in Mathematical Logic, 1879-1931, Harvard University Press, Cambridge, MA, 1967. Reprinted with corrections, 1977.
- Kelley, J.L., General Topology, Van Nostrand Reinhold, New York, NY, 1955.
[edit] External links
- Beginnings of set theory page at St. Andrews
- Earliest Known Uses of Some of the Words of Mathematics (S)
- Uniqueness of the empty set Is there only one empty set rather than an infinity of empty subsets?
[edit] Note
- ^ Concerning the origin of the term naive set theory, Jeff Miller has this to say: “Naïve set theory (contrasting with axiomatic set theory) was used occasionally in the 1940s and became an established term in the 1950s. It appears in Hermann Weyl's review of P. A. Schilpp (ed) The Philosophy of Bertrand Russell in the American Mathematical Monthly, 53., No. 4. (1946), p. 210 and Laszlo Kalmar's review of The Paradox of Kleene and Rosser in Journal of Symbolic Logic, 11, No. 4. (1946), p. 136. (JSTOR).” [1] The term was later popularized by Paul Halmos' book, Naive Set Theory (1960).

