Hamming distance
From Wikipedia, the free encyclopedia

|
|

|
|
|---|---|
|
|
In information theory, the Hamming distance between two strings of equal length is the number of positions for which the corresponding symbols are different. Put another way, it measures the minimum number of substitutions required to change one into the other, or the number of errors that transformed one string into the other.
Contents |
[edit] Examples
The Hamming distance between:
- 1011101 and 1001001 is 2.
- 2173896 and 2233796 is 3.
- "toned" and "roses" is 3.
[edit] Special properties
For a fixed length n, the Hamming distance is a metric on the vector space of the words of that length, as it obviously fulfills the conditions of non-negativity, identity of indiscernibles and symmetry, and it can be shown easily by complete induction that it satisfies the triangle inequality as well. The Hamming distance between two words a and b can also be seen as the Hamming weight of a−b for an appropriate choice of the − operator.
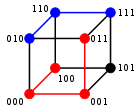
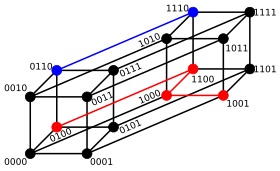
For binary strings a and b the Hamming distance is equal to the number of ones in a XOR b. The metric space of length-n binary strings, with the Hamming distance, is known as the Hamming cube; it is equivalent as a metric space to the set of distances between vertices in a hypercube graph. One can also view a binary string of length n as a vector in 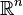 by treating each symbol in the string as a real coordinate; with this embedding, the strings form the vertices of an n-dimensional hypercube, and the Hamming distance of the strings is equivalent to the Manhattan distance between the vertices.
by treating each symbol in the string as a real coordinate; with this embedding, the strings form the vertices of an n-dimensional hypercube, and the Hamming distance of the strings is equivalent to the Manhattan distance between the vertices.
[edit] History and applications
The Hamming distance is named after Richard Hamming, who introduced it in his fundamental paper about error-detecting and error-correcting codes (1950) introducing Hamming codes. It is used in telecommunication to count the number of flipped bits in a fixed-length binary word as an estimate of error, and therefore is sometimes called the signal distance. Hamming weight analysis of bits is used in several disciplines including information theory, coding theory, and cryptography. However, for comparing strings of different lengths, or strings where not just substitutions but also insertions or deletions have to be expected, a more sophisticated metric like the Levenshtein distance is more appropriate. For q-ary strings over an alphabet of size q ≥ 2 the Hamming distance is applied in case of orthogonal modulation, while the Lee distance is used for phase modulation. If q = 2 or q = 3 both distances coincide.
The Hamming distance is also used in systematics as a measure of genetic distance.[1]
On a grid (such as a chessboard), the points at a Hamming distance of 1 constitute the von Neumann neighborhood of that point.
[edit] Algorithm example
The Python function hamdist() computes the Hamming distance between two strings (or other iterable objects) of equal length.
def hamdist(s1, s2): assert len(s1) == len(s2) return sum(ch1 != ch2 for ch1, ch2 in zip(s1, s2))
The following C function will compute the Hamming distance of two integers (considered as binary values, that is, as sequences of bits). The running time of this procedure is proportional to the Hamming distance rather than to the number of bits in the inputs. It works by XORing the two inputs, and then counting the number of bits set in the result.
unsigned hamdist(unsigned x, unsigned y) { unsigned dist = 0, val = x ^ y; // Count the number of set bits (Knuth's algorithm) while(val) { ++dist; val &= val - 1; } return dist; }
[edit] See also
- Jaccard index
- Levenshtein distance (aka “edit distance”), a generalization of the Hamming distance
- Similarity (mathematics)
- Similarity space on Numerical taxonomy
- Sørensen similarity index
[edit] Notes
- ^ Pilcher CD, Wong JK, Pillai SK (March 2008). "Inferring HIV transmission dynamics from phylogenetic sequence relationships". PLoS Med. 5 (3): e69. doi:. PMID 18351799.
[edit] References
- This article contains material from the Federal Standard 1037C, which, as a work of the United States Government, is in the public domain.
- Richard W. Hamming. Error Detecting and Error Correcting Codes, Bell System Technical Journal 26(2):147-160, 1950.
[edit] External links
- Example of Hamming distance
- Hamming Code Tool Tool to generate hamming code

