Object recognition
From Wikipedia, the free encyclopedia
|
|
This article only describes one highly specialized aspect of its associated subject. Please help improve this article by adding more general information. |
|
|
Some parts of this article may be misleading. Please help clarify this article. Suggestions may be on the talk page. |
| Feature detection | |
 Output of a typical corner detection algorithm |
|
| Edge detection | |
|---|---|
| Canny | |
| Canny-Deriche | |
| Differential | |
| Sobel | |
| Interest point detection | |
| Corner detection | |
| Harris operator | |
| Shi and Tomasi | |
| Level curve curvature | |
| SUSAN | |
| FAST | |
| Blob detection | |
| Laplacian of Gaussian (LoG) | |
| Difference of Gaussians (DoG) | |
| Determinant of Hessian (DoH) | |
| Maximally stable extremal regions | |
| Ridge detection | |
| Affine invariant feature detection | |
| Affine shape adaptation | |
| Harris affine | |
| Hessian affine | |
| Feature description | |
| SIFT | |
| SURF | |
| GLOH | |
| LESH | |
| Scale-space | |
| Scale-space axioms | |
| Implementation details | |
| Pyramids | |
Object recognition in computer vision is the task of finding a given object in an image or video sequence. Humans recognize a multitude of objects in images with little effort, despite the fact that the image of the objects may vary somewhat in different view points, in many different sizes / scale or even when they are translated or rotated. Objects can even be recognized when they are partially obstructed from view. This task is still a challenge for computer vision systems in general. David Lowe pioneered the computer vision approach to extracting and using scale-invariant SIFT features from images to perform reliable object recognition.
For any object in an image, there are many 'features' which are interesting points on the object, that can be extracted to provide a "feature" description of the object. This description extracted from a training image can then be used to identify the object when attempting to locate the object in a test image containing many other objects. It is important that the set of features extracted from the training image is robust to changes in image scale, noise, illumination and local geometric distortion, for performing reliable recognition. Lowe's patented method [1]can robustly identify objects even among clutter and under partial occlusion because his SIFT feature descriptor is invariant to scale, orientation, affine distortion and partially invariant to illumination changes[2]. This article presents Lowe's object recognition method in a nutshell and mentions a few competing techniques available for object recognition under clutter and partial occlusion.
Contents |
[edit] David Lowe's method
SIFT keypoints of objects are first extracted from a set of reference images[2] and stored in a database. An object is recognised in a new image by individually comparing each feature from the new image to this database and finding candidate matching features based on Euclidean distance of their feature vectors. From the full set of matches, subsets of keypoints that agree on the object and its location, scale, and orientation in the new image are identified to filter out good matches. The determination of consistent clusters is performed rapidly by using an efficient hash table implementation of the generalized Hough transform. Each cluster of 3 or more features that agree on an object and its pose is then subject to further detailed model verification and subsequently outliers are discarded. Finally the probability that a particular set of features indicates the presence of an object is computed, given the accuracy of fit and number of probable false matches. Object matches that pass all these tests can be identified as correct with high confidence[3].
| Problem | Technique | Advantage |
|---|---|---|
| key localization / scale / rotation | DoG / scale - space pyramid / orientation assignment | accuracy, stability, scale & rotational invariance |
| geometric distortion | blurring / resampling of local image orientation planes | affine invariance |
| indexing and matching | nearest neighbor / Best Bin First search | Efficiency / speed |
| Cluster identification | Hough Transform voting | reliable pose models |
| Model verification / outlier detection | Linear least squares | better error tolerance with fewer matches |
| Hypothesis acceptance | Bayesian Probability analysis | reliability |
[edit] Key stages
[edit] Scale-invariant feature detection
Lowe's method for image feature generation called the Scale Invariant Feature Transform (SIFT) transforms an image into a large collection of feature vectors, each of which is invariant to image translation, scaling, and rotation, partially invariant to illumination changes and robust to local geometric distortion. These features share similar properties with neurons in inferior temporal cortex that are used for object recognition in primate vision[4]. Key locations are defined as maxima and minima of the result of difference of Gaussians function applied in scale-space to a series of smoothed and resampled images. Low contrast candidate points and edge response points along an edge are discarded. Dominant orientations are assigned to localized keypoints. These steps ensure that the keypoints are more stable for matching and recognition. SIFT descriptors robust to local affine distortion are then obtained by considering pixels around a radius of the key location, blurring and resampling of local image orientation planes.
[edit] Feature matching and indexing
Indexing is the problem of storing SIFT keys and identifying matching keys from the new image. Lowe used a modification of the k-d tree algorithm called the Best-bin-first search method [5]that can identify the nearest neighbors with high probability using only a limited amount of computation. The BBF algorithm uses a modified search ordering for the k-d tree algorithm so that bins in feature space are searched in the order of their closest distance from the query location. This search order requires the use of a heap (data structure) based priority queue for efficient determination of the search order. The best candidate match for each keypoint is found by identifying its nearest neighbor in the database of keypoints from training images. The nearest neighbors are defined as the keypoints with minimum Euclidean distance from the given descriptor vector. The probability that a match is correct can be determined by taking the ratio of distance from the closest neighbor to the distance of the second closest.
Lowe[3] rejected all matches in which the distance ratio is greater than 0.8, which eliminates 90% of the false matches while discarding less than 5% of the correct matches. To further improve the efficiency of the best-bin-first algorithm search was cut off after checking the first 200 nearest neighbor candidates. For a database of 100,000 keypoints, this provides a speedup over exact nearest neighbor search by about 2 orders of magnitude yet results in less than a 5% loss in the number of correct matches.
[edit] Cluster identification by Hough transform voting
Hough Transform is used to cluster reliable model hypotheses to search for keys that agree upon a particular model pose. Hough transform identifies clusters of features with a consistent interpretation by using each feature to vote for all object poses that are consistent with the feature. When clusters of features are found to vote for the same pose of an object, the probability of the interpretation being correct is much higher than for any single feature. An entry in a hash table is created predicting the model location, orientation, and scale from the match hypothesis.The hash table is searched to identify all clusters of at least 3 entries in a bin, and the bins are sorted into decreasing order of size.
Each of the SIFT keypoints specifies 2D location, scale, and orientation, and each matched keypoint in the database has a record of the keypoint’s parameters relative to the training image in which it was found. The similarity transform implied by these 4 parameters is only an approximation to the full 6 degree-of-freedom pose space for a 3D object and also does not account for any non-rigid deformations. Therefore, Lowe[3] used broad bin sizes of 30 degrees for orientation, a factor of 2 for scale, and 0.25 times the maximum projected training image dimension (using the predicted scale) for location. The SIFT key samples generated at the larger scale are given twice the weight of those at the smaller scale. This means that the larger scale is in effect able to filter the most likely neighbours for checking at the smaller scale. This also improves recognition performance by giving more weight to the least-noisy scale. To avoid the problem of boundary effects in bin assignment, each keypoint match votes for the 2 closest bins in each dimension, giving a total of 16 entries for each hypothesis and further broadening the pose range.
[edit] Model verification by linear least squares
Each identified cluster is then subject to a verification procedure in which a linear least squares solution is performed for the parameters of the affine transformation relating the model to the image. The affine transformation of a model point [x y]T to an image point [u v]T can be written as below

where the model translation is [tx ty]T and the affine rotation, scale, and stretch are represented by the parameters m1, m2, m3 and m4. To solve for the transformation parameters the equation above can be rewritten to gather the unknowns into a column vector.
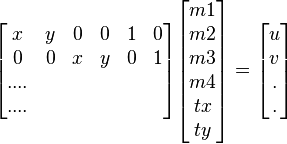
This equation shows a single match, but any number of further matches can be added, with each match contributing two more rows to the first and last matrix. At least 3 matches are needed to provide a solution. We can write this linear system as

where A is a known m-by-n matrix (usually with m > n), x is an unknown n-dimensional parameter vector, and b is a known m-dimensional measurement vector.
Therefore the minimizing vector  is a solution of the normal equation
is a solution of the normal equation

The solution of the system of linear equations is given in terms of the matrix (ATA) − 1AT , called the pseudoinverse of A, by

which minimizes the sum of the squares of the distances from the projected model locations to the corresponding image locations.
[edit] Outlier detection
Outliers can now be removed by checking for agreement between each image feature and the model, given the parameter solution. Given the linear least squares solution, each match is required to agree within half the error range that was used for the parameters in the Hough transform bins. As outliers are discarded, the linear least squares solution is re-solved with the remaining points, and the process iterated. If fewer than 3 points remain after discarding outliers, then the match is rejected. In addition, a top-down matching phase is used to add any further matches that agree with the projected model position, which may have been missed from the Hough transform bin due to the similarity transform approximation or other errors.
The final decision to accept or reject a model hypothesis is based on a detailed probabilistic model[6]. This method first computes the expected number of false matches to the model pose, given the projected size of the model, the number of features within the region, and the accuracy of the fit. A Bayesian probability analysis then gives the probability that the object is present based on the actual number of matching features found. A model is accepted if the final probability for a correct interpretation is greater than 0.98. Lowe's SIFT based object recognition gives excellent results except under wide illumination variations and under non-rigid transformations.
[edit] Competing methods for scale invariant object recognition under clutter / partial occlusion
RIFT [7] is a rotation-invariant generalization of SIFT. The RIFT descriptor is constructed using circular normalized patches divided into concentric rings of equal width and within each ring a gradient orientation histogram is computed. To maintain rotation invariance, the orientation is measured at each point relative to the direction pointing outward from the center.
G-RIF[8] : Generalized Robust Invariant Feature is a general context descriptor which encodes edge orientation, edge density and hue information in a unified form combining perceptual information with spatial encoding. The object recognition scheme uses neighbouring context based voting to estimate object models.
"SURF[9] : Speeded Up Robust Features" is a high-performance scale and rotation-invariant interest point detector / descriptor claimed to approximate or even outperform previously proposed schemes with respect to repeatability, distinctiveness, and robustness. SURF relies on integral images for image convolutions to reduce computation time, builds on the strengths of the leading existing detectors and descriptors (using a fast Hessian matrix-based measure for the detector and a distribution-based descriptor). It describes a distribution of Haar wavelet responses within the interest point neighbourhood. Integral images are used for speed and only 64 dimensions are used reducing the time for feature computation and matching. The indexing step is based on the sign of the Laplacian,which increases the matching speed and the robustness of the descriptor.
PCA-SIFT [10]and GLOH [11] are variants of SIFT. PCA-SIFT descriptor is a vector of image gradients in x and y direction computed within the support region. The gradient region is sampled at 39x39 locations, therefore the vector is of dimension 3042. The dimension is reduced to 36 with PCA. Gradient location-orientation histogram (GLOH) is an extension of the SIFT descriptor designed to increase its robustness and distinctiveness. The SIFT descriptor is computed for a log-polar location grid with three bins in radial direction (the radius set to 6, 11, and 15) and 8 in angular direction, which results in 17 location bins. The central bin is not divided in angular directions. The gradient orientations are quantized in 16 bins resulting in 272 bin histogram. The size of this descriptor is reduced with PCA. The covariance matrix for PCA is estimated on image patches collected from various images. The 128 largest eigenvectors are used for description.
[edit] Applications
Object recognition methods has the following applications:
[edit] References
- ^ U.S. patent 6,711,293
 , "Method and apparatus for identifying scale invariant features in an image and use of same for locating an object in an image", David Lowe's patent for the SIFT algorithm
, "Method and apparatus for identifying scale invariant features in an image and use of same for locating an object in an image", David Lowe's patent for the SIFT algorithm - ^ a b Lowe, D. G., “Object recognition from local scale-invariant features”, International Conference on Computer Vision, Corfu, Greece, September 1999.
- ^ a b c Lowe, D. G., “Distinctive Image Features from Scale-Invariant Keypoints”, International Journal of Computer Vision, 60, 2, pp. 91-110, 2004.
- ^ Serre, T., Kouh, M., Cadieu, C., Knoblich, U., Kreiman, G., Poggio, T., “A Theory of Object Recognition: Computations and Circuits in the Feedforward Path of the Ventral Stream in Primate Visual Cortex”, Computer Science and Artificial Intelligence Laboratory Technical Report, December 19, 2005 MIT-CSAIL-TR-2005-082.
- ^ Beis, J., and Lowe, D.G “Shape indexing using approximate nearest-neighbour search in high-dimensional spaces”, Conference on Computer Vision and Pattern Recognition,Puerto Rico, 1997, pp. 1000–1006.
- ^ Lowe, D.G., Local feature view clustering for 3D object recognition. IEEE Conference on Computer Vision and Pattern Recognition,Kauai, Hawaii, 2001, pp. 682-688.
- ^ Lazebnik, S., Schmid, C., and Ponce, J., Semi-Local Affine Parts for Object Recognition, BMVC, 2004.
- ^ Sungho Kim, Kuk-Jin Yoon, In So Kweon, "Object Recognition Using a Generalized Robust Invariant Feature and Gestalt’s Law of Proximity and Similarity," Conference on Computer Vision and Pattern Recognition Workshop (CVPRW'06), 2006
- ^ Bay, H., Tuytelaars, T., Gool, L.V., "SURF: Speeded Up Robust Features", Proceedings of the ninth European Conference on Computer Vision, May 2006.
- ^ Ke, Y., and Sukthankar, R., PCA-SIFT: A More Distinctive Representation for Local Image DescriptorsComputer Vision and Pattern Recognition, 2004.
- ^ Mikolajczyk, K., and Schmid, C., "A performance evaluation of local descriptors", IEEE Transactions on Pattern Analysis and Machine Intelligence, 10, 27, pp 1615--1630, 2005.
- ^ Brown, M., and Lowe, D.G., "Recognising Panoramas," ICCV, p. 1218, Ninth IEEE International Conference on Computer Vision (ICCV'03) - Volume 2, Nice,France, 2003
- ^ Li, L., Guo, B., and Shao, K., " Geometrically robust image watermarking using scale-invariant feature transform and Zernike moments," Chinese Optics Letters, Volume 5, Issue 6, pp. 332-335, 2007.
- ^ Se,S., Lowe, D.G., and Little, J.J.,"Vision-based global localization and mapping for mobile robots", IEEE Transactions on Robotics, 21, 3 (2005), pp. 364-375.
[edit] External links
- Lowe, D. G., “Distinctive Image Features from Scale-Invariant Keypoints”, International Journal of Computer Vision, 60, 2, pp. 91-110, 2004.
- David Lowe's Publications
- David Lowe's Demo Software : SIFT keypoint detector
- SURF: Speeded up robust features
- Mikolajczyk, K., and Schmid, C., "A performance evaluation of local descriptors", IEEE Transactions on Pattern Analysis and Machine Intelligence, 10, 27, pp 1615--1630, 2005.
- PCA-SIFT: A More Distinctive Representation for Local Image Descriptors
- Lazebnik, S., Schmid, C., and Ponce, J., Semi-Local Affine Parts for Object Recognition, BMVC, 2004.
- libsift: Scale Invariant Feature Transform implementation

