Gradient
From Wikipedia, the free encyclopedia
| Look up gradient in Wiktionary, the free dictionary. |


In vector calculus, the gradient of a scalar field is a vector field which points in the direction of the greatest rate of increase of the scalar field, and whose magnitude is the greatest rate of change.
A generalization of the gradient for functions on a Euclidean space which have values in another Euclidean space is the Jacobian. A further generalization for a function from one Banach space to another is the Fréchet derivative.
Contents |
[edit] Interpretations of the gradient
For instance, consider a room in which the temperature is given by a scalar field T, so at each point (x,y,z) the temperature is T(x,y,z) (we will assume that the temperature does not change in time). Then, at each point in the room, the gradient of T at that point will show the direction in which the temperature rises most quickly. The magnitude of the gradient will determine how fast the temperature rises in that direction.
Consider a hill whose height above sea level at a point (x,y) is H(x,y). The gradient of H at a point is a vector pointing in the direction of the steepest slope or grade at that point. The steepness of the slope at that point is given by the magnitude of the gradient vector.
The gradient can also be used to measure how a scalar field changes in other directions, rather than just the direction of greatest change, by taking a dot product. Consider again the example with the hill and suppose that the steepest slope on the hill is 40%. If a road goes directly up the hill, then the steepest slope on the road will also be 40%. If, instead, the road goes around the hill at an angle (the gradient vector), then it will have a shallower slope. For example, if the angle between the road and the uphill direction, projected onto the horizontal plane, is 60°, then the steepest slope along the road will be 20%, which is 40% times the cosine of 60°.
This observation can be mathematically stated as follows. If the hill height function H is differentiable, then the gradient of H dotted with a unit vector gives the slope of the hill in the direction of the vector. More precisely, when H is differentiable, the dot product of the gradient of H with a given unit vector is equal to the directional derivative of H in the direction of that unit vector.
[edit] Definition
The gradient (or gradient vector field) of a scalar function f(x) with respect to a vector variable  is denoted by
is denoted by  or
or  where
where  (the nabla symbol) denotes the vector differential operator, del. The notation
(the nabla symbol) denotes the vector differential operator, del. The notation  is also used for the gradient. The gradient of f is defined to be the vector field whose components are the partial derivatives of f. That is:
is also used for the gradient. The gradient of f is defined to be the vector field whose components are the partial derivatives of f. That is:
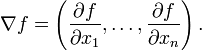
Here the gradient is written as a row vector, but it is often taken to be a column vector. When a function also depends on a parameter such as time, the gradient often refers simply to the vector of its spatial derivatives only.
[edit] Expressions for the gradient in 3 dimensions
The form of the gradient depends on the coordinate system used.
In Cartesian coordinates, the above expression expands to

which is often written using the standard versors i, j, k:

In cylindrical coordinates, the gradient is given by (Schey 1992, pp. 139-142):

where θ is the azimuthal angle, z is the axial coordinate, and eρ, eθ and ez are unit vectors pointing along the coordinate directions.
In spherical coordinates (Schey 1992, pp. 139-142):

where φ is the azimuth angle and θ is the zenith angle.
[edit] Example
For example, the gradient of the function in Cartesian coordinates
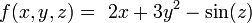
is:

[edit] The gradient and the derivative or differential
[edit] Linear approximation to a function
The gradient of a function f from the Euclidean space 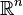 to
to 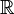 at any particular point x0 in characterizes the best linear approximation to f at x0. The approximation is as follows:
at any particular point x0 in characterizes the best linear approximation to f at x0. The approximation is as follows: 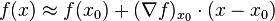 for x close to x0, where
for x close to x0, where 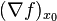 is the gradient of f computed at x0, and the dot denotes the dot product on . This equation is equivalent to the first two terms in the multi-variable Taylor Series expansion of f at x0.
is the gradient of f computed at x0, and the dot denotes the dot product on . This equation is equivalent to the first two terms in the multi-variable Taylor Series expansion of f at x0.
[edit] The differential or (exterior) derivative
The best linear approximation to a function  at a point x in is a linear map from to which is often denoted by dfx or Df(x) and called the differential or (total) derivative of f at x. The gradient is therefore related to the differential by the formula
at a point x in is a linear map from to which is often denoted by dfx or Df(x) and called the differential or (total) derivative of f at x. The gradient is therefore related to the differential by the formula 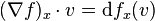 for any
for any  . The function df, which maps x to dfx, is called the differential or exterior derivative of f and is an example of a differential 1-form.
. The function df, which maps x to dfx, is called the differential or exterior derivative of f and is an example of a differential 1-form.
If is viewed as the space of (length n) column vectors (of real numbers), then one can regard df as the row vector

so that dfx(v) is given by matrix multiplication. The gradient is then the corresponding column vector, i.e.,  .
.
[edit] Gradient as a derivative
Let U be an open set in Rn. If the function f:U → R is differentiable, then the differential of f is the (Fréchet) derivative of f. Thus is a function from U to the space R such that  where • is the dot product.
where • is the dot product.
As a consequence, the usual properties of the derivative hold for the gradient:
- Linearity
The gradient is linear in the sense that if f and g are two real-valued functions differentiable at the point a∈Rn, and α and β are two constants, then αf+βg is differentiable at a, and moreover

- Product rule
If f and g are real-valued functions differentiable at a point a∈Rn, then the product rule asserts that the product (fg)(x) = f(x)g(x) of the functions f and g is differentiable at a, and

- Chain rule
Suppose that f:A→R is a real-valued function defined on a subset A of Rn, and that f is differentiable at a point a. There are two forms of the chain rule applying to the gradient. First, suppose that the function g is a parametric curve; that is, a function g : I → Rn maps a subset I ⊂ R into Rn. If g is differentiable at a point c ∈ I such that g(c) = a, then

More generally, if instead I⊂Rk, then the following holds:
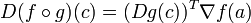
where (Dg)T denotes the transpose Jacobian matrix.
For the second form of the chain rule, suppose that h : I → R is a real valued function on a subset I of R, and that h is differentiable at the point c = f(a) ∈ I. Then
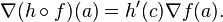
[edit] Transformation properties
Although the gradient is defined in term of coordinates, it is contravariant under the application of an orthogonal matrix to the coordinates. This is true in the sense that if A is an orthogonal matrix, then
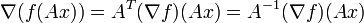
which follows by the chain rule above. A vector transforming in this way is known as a contravariant vector, and so the gradient is a special type of tensor.
The differential is more natural than the gradient because it is invariant under all coordinate transformations (or diffeomorphisms), whereas the gradient is only invariant under orthogonal transformations (because of the implicit use of the dot product in its definition). Because of this, it is common to blur the distinction between the two concepts using the notion of covariant and contravariant vectors. From this point of view, the components of the gradient transform covariantly under changes of coordinates, so it is called a covariant vector field, whereas the components of a vector field in the usual sense transform contravariantly. In this language the gradient is the differential, as a covariant vector field is the same thing as a differential 1-form.[1]
- ^ Unfortunately this confusing language is confused further by differing conventions. Although the components of a differential 1-form transform covariantly under coordinate transformations, differential 1-forms themselves transform contravariantly (by pullback) under diffeomorphism. For this reason differential 1-forms are sometimes said to be contravariant rather than covariant, in which case vector fields are covariant rather than contravariant.
[edit] Further properties and applications
[edit] Level sets
If the partial derivatives of f are continuous, then the dot product  of the gradient at a point x with a vector v gives the directional derivative of f at x in the direction v. It follows that in this case the gradient of f is orthogonal to the level sets of f.
of the gradient at a point x with a vector v gives the directional derivative of f at x in the direction v. It follows that in this case the gradient of f is orthogonal to the level sets of f.
Because the gradient is orthogonal to level sets, it can be used to construct a vector normal to a surface. Consider any manifold that is one dimension less than the space it is in (e.g., a surface in 3D, a curve in 2D, etc.). Let this manifold be defined by an equation e.g. F(x, y, z) = 0 (i.e., move everything to one side of the equation). We have now turned the manifold into a level set. To find a normal vector, we simply need to find the gradient of the function F at the desired point.
[edit] Conservative vector fields
The gradient of a function is called a gradient field. A gradient field is always a conservative vector field: line integrals through a gradient field are path-independent and can be evaluated with the gradient theorem (the fundamental theorem of calculus for line integrals). Conversely, a conservative vector field in a simply connected region is always the gradient of a function.
[edit] The gradient on Riemannian manifolds
For any smooth function f on a Riemannian manifold (M,g), the gradient of f is the vector field such that for any vector field X,

where  denotes the inner product of tangent vectors at x defined by the metric g and
denotes the inner product of tangent vectors at x defined by the metric g and  (sometimes denoted X(f)) is the function that takes any point x∈M to the directional derivative of f in the direction X, evaluated at x. In other words, in a coordinate chart
(sometimes denoted X(f)) is the function that takes any point x∈M to the directional derivative of f in the direction X, evaluated at x. In other words, in a coordinate chart 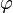 from an open subset of M to an open subset of Rn,
from an open subset of M to an open subset of Rn,  is given by:
is given by:

where Xj denotes the jth component of X in this coordinate chart.
So, the local form of the gradient takes the form:

Generalizing the case M=Rn, the gradient of a function is related to its exterior derivative, since  . More precisely, the gradient is the vector field associated to the differential 1-form df using the musical isomorphism
. More precisely, the gradient is the vector field associated to the differential 1-form df using the musical isomorphism  (called "sharp") defined by the metric g. The relation between the exterior derivative and the gradient of a function on Rn is a special case of this in which the metric is the flat metric given by the dot product.
(called "sharp") defined by the metric g. The relation between the exterior derivative and the gradient of a function on Rn is a special case of this in which the metric is the flat metric given by the dot product.
[edit] See also
[edit] References
- Korn, Theresa M.; Korn, Granino Arthur (2000), Mathematical Handbook for Scientists and Engineers: Definitions, Theorems, and Formulas for Reference and Review, New York: Dover Publications, pp. 157-160, ISBN 0-486-41147-8, OCLC 43864234.
- Schey, H.M. (1992), Div, Grad, Curl, and All That (2nd ed.), W.W. Norton, ISBN 0-393-96251-2, OCLC 25048561.
[edit] External links
- Gradients at Wolfram MathWorld
- Berkeley Mathematics lecture on gradient vectors

