Z-test
From Wikipedia, the free encyclopedia
The Z-test is a statistical test used in inference which determines if the difference between a sample mean and the population mean is large enough to be statistically significant, that is, if it is unlikely to have occurred by chance.
The Z-test is used primarily with standardized testing to determine if the test scores of a particular sample of test takers are within or outside of the standard performance of test takers.
Contents |
[edit] Notation and mathematics
In order for the Z-test to be reliable, certain conditions must be met. The most important is that since the Z-test uses the population standard deviation, it must be known. The sample must be a simple random sample of the population. If the sample came from a different sampling method, a different formula must be used. It must also be known that the population varies normally (i.e., the sampling distribution of the probabilities of possible values fits a standard normal curve). If it is not known that the population varies normally, it suffices to have a sufficiently large sample, generally agreed to be more than 30 or 40.
In actuality, knowing the true σ of a population is unrealistic except for cases such as standardized testing in which the entire population is known. In cases where it is impossible to measure every member of a population it is more realistic to use a t-test, which uses the standard error obtained from the sample along with the t-distribution.
The test requires the following to be known:
- σ (the standard deviation of the population)
First calculate the standard error (SE) of the mean:
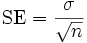
The formula for calculating the z score for the Z-test is as follows:


where:
- x is a mean score to be standardized
- μ is the mean of the population
Finally, the z score is compared to a Z table, a table which contains the percent of area under the normal curve between the mean and the z score. Using this table will indicate whether the calculated z score is within the realm of chance or if the z score is so different from the mean that the sample mean is unlikely to have happened by chance.
[edit] Example
Let's take a look at using the Z-test with standardized testing.
In a U.S. school district, a standardized reading test is used to test the performance of fifth grade students in an elementary school against the national norm for fifth grade students. The number of fifth grade students in this elementary school taking the test is 55 students.
The national norm test score, the population mean, for this particular standardized test is 100 points. The population standard deviation for the year under study is 12.
The scores of the fifth grade students of the elementary school in this school district are a sample of the total population of fifth grade students in the U.S. which have also taken the test.
The school district is told that the mean for their particular school is 96, which is lower than the national mean. Parents of the students become upset when they learn their school is below the national norm for the reading test. The school district administration points out that the test scores are actually pretty close to the population mean though they are lower.
The real question is this, is the school's mean test score sufficiently lower than the national norm as to indicate a problem or is the school's mean test score within acceptable parameters. We will use the Z-test to see.
First of all calculate the standard error of the mean:

Next calculate the z score:

Remember that a z score is the distance from the population mean in units of the population standard deviation. This means that in our example, a mean score of 96 is −2.47 standard deviation units from the population mean. The negative means that the sample mean is less than the population mean. Since the normal curve is symmetric the Z table is always expressed in positive z scores so if the calculated z score is negative, look it up in the table as if it were non-negative.
Next we look the z score up in a Z table and we find that a z score of −2.47 is 49.32%. This means that the area under the normal curve between the population mean and our sample mean is 49.32%.
What this tells us is that 49.32% plus 50% or 99.32% of the time, a randomly selected group of 55 students have a higher average score than these 55 students had. This is because our z score is negative so we are below the population mean. So not only do we include the distance between our sample mean and the population mean, we also include the area under the normal curve which is greater than the population mean.
If our sample mean had been 104 rather than 96, then our z score would have been 2.47 which would have indicated that our sample mean was above the population mean. That would have indicated that the fifth grade students in our sample were in the top 0.7% of the nation.
But let's get back to our original question. Is there a problem with the reading program at our elementary school? Our question can be reformulated to say, is the mean from our elementary school, a sample from the general population of fifth grade students, far enough outside of the norm that we need to take a corrective action to improve the reading program?
Let's put this in the form of a hypothesis which we are going to test with our statistical analysis. Our alternative hypothesis is that our sample mean is significantly different from the population mean and that corrective action is necessary. Our null hypothesis is that the difference is purely attributable to chance and no action is necessary.
To answer this question, we need to determine what is the level of confidence (confidence level) we want to use. Typically a 0.05 confidence level is used meaning that if the null hypothesis is true we stand only a 5% chance of rejecting it anyway.
In the case of our sample mean, the z score of −2.47 which provides us a value of 49.32% means that 49.32% plus 50% or 99.32% of the time, a randomly selected group of 55 students have a higher average score than the 55 students in our sample had.[citation needed] To test our null hypothesis, we have to conduct a two-sided test. Since our sample is outside of this area by 1.82%, we have to reject the null hypothesis because the value of 1.82% is less than 5%, our confidence level.[citation needed]
Therefore we can conclude with a 95% confidence level that the test performance of the students in our sample were not within the normal variation.
[edit] References
- Sprinthall, Richard C. Basic Statistical Analysis: Seventh Edition, copyright 2003, Pearson Education Group
[edit] External links
- Code/pseudo-code for Z-test at Google Groups
- http://espse.ed.psu.edu/statistics/Chapters/Chapter6/Chap6.html
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||

