Linear classifier
From Wikipedia, the free encyclopedia
In the field of machine learning, the goal of classification is to group items that have similar feature values, into groups. A linear classifier achieves this by making a classification decision based on the value of the linear combination of the features.
Contents |
[edit] Definition
If the input feature vector to the classifier is a real vector 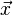 , then the output score is
, then the output score is

where  is a real vector of weights and f is a function that converts the dot product of the two vectors into the desired output. The weight vector is learned from a set of labeled training samples. Often f is a simple function that maps all values above a certain threshold to the first class and all other values to the second class. A more complex f might give the probability that an item belongs to a certain class.
is a real vector of weights and f is a function that converts the dot product of the two vectors into the desired output. The weight vector is learned from a set of labeled training samples. Often f is a simple function that maps all values above a certain threshold to the first class and all other values to the second class. A more complex f might give the probability that an item belongs to a certain class.
For a two-class classification problem, one can visualize the operation of a linear classifier as splitting a high-dimensional input space with a hyperplane: all points on one side of the hyperplane are classified as "yes", while the others are classified as "no".
A linear classifier is often used in situations where the speed of classification is an issue, since it is often the fastest classifier, especially when is sparse. However, decision trees can be faster. Also, linear classifiers often work very well when the number of dimensions in is large, as in document classification, where each element in is typically the number of counts of a word in a document (see document-term matrix). In such cases, the classifier should be well-regularized.
[edit] Generative models vs. discriminative models
There are two broad classes of methods for determining the parameters of a linear classifier [1][2]. The first is by modeling conditional density functions  . Examples of such algorithms include:
. Examples of such algorithms include:
- Linear Discriminant Analysis (or Fisher's linear discriminant) (LDA) --- assumes Gaussian conditional density models
- Naive Bayes classifier --- assumes independent binomial conditional density models.
The second set approaches are called discriminative models, which attempt to maximize the quality of the output on a training set. Additional terms in the training cost function can easily perform regularization of the final model. Examples of discriminative training of linear classifiers include
- Logistic regression --- maximum likelihood estimation of assuming that the observed training set was generated by a binomial model that depends on the output of the classifier.
- Perceptron --- an algorithm that attempts to fix all errors encountered in the training set
- Support vector machine --- an algorithm that maximizes the margin between the decision hyperplane and the examples in the training set.
Note: In contrast to its name, LDA does not belong to the class of discriminative models in this taxonomy. However, its name makes sense when we compare LDA to the other main linear dimensionality reduction algorithm: Principal Components Analysis (PCA). LDA is a supervised learning algorithm that utilizes the labels of the data, while PCA is an unsupervised learning algorithm that ignores the labels. To summarize, the name is a historical artifact (see [3], p.117).
Discriminative training often yields higher accuracy than modeling the conditional density functions. However, handling missing data is often easier with conditional density models.
All of the linear classifier algorithms listed above can be converted into non-linear algorithms operating on a different input space  , using the kernel trick.
, using the kernel trick.
[edit] See also
[edit] Notes
- ^ T. Mitchell, Generative and Discriminative Classifiers: Naive Bayes and Logistic Regression. Draft Version, 2005 download
- ^ A. Y. Ng and M. I. Jordan. On Discriminative vs. Generative Classifiers: A comparison of logistic regression and Naive Bayes. in NIPS 14, 2002. download
- ^ R.O. Duda, P.E. Hart, D.G. Stork, "Pattern Classification", Wiley, (2001). ISBN 0-471-05669-3
See also:
- Y. Yang, X. Liu, "A re-examination of text categorization", Proc. ACM SIGIR Conference, pp. 42-49, (1999). paper @ citeseer
- R. Herbrich, "Learning Kernel Classifiers: Theory and Algorithms," MIT Press, (2001). ISBN 0-262-08306-X

