Interpolation
From Wikipedia, the free encyclopedia
In the mathematical subfield of numerical analysis, interpolation is a method of constructing new data points within the range of a discrete set of known data points.
In engineering and science one often has a number of data points, as obtained by sampling or experimentation, and tries to construct a function which closely fits those data points. This is called curve fitting or regression analysis. Interpolation is a specific case of curve fitting, in which the function must go exactly through the data points.
A different problem which is closely related to interpolation is the approximation of a complicated function by a simple function. Suppose we know the function but it is too complex to evaluate efficiently. Then we could pick a few known data points from the complicated function, creating a lookup table, and try to interpolate those data points to construct a simpler function. Of course, when using the simple function to calculate new data points we usually do not receive the same result as when using the original function, but depending on the problem domain and the interpolation method used the gain in simplicity might offset the error.
It should be mentioned that there is another very different kind of interpolation in mathematics, namely the "interpolation of operators". The classical results about interpolation of operators are the Riesz-Thorin theorem and the Marcinkiewicz theorem. There also are many other subsequent results.

Contents |
[edit] Definition
From inter meaning between and pole, the points or nodes. Any means of calculating a new point between two or more existing data points is interpolation.
There are many methods for doing this, many of which involve fitting some sort of function to the data and evaluating that function at the desired point. This does not exclude other means such as statistical methods of calculating interpolated data.
One of the simplest forms of interpolation is to take the arithmetic mean of the value of two adjacent points to find the mid point. This will give the same result as a linear function evaluated at the midpoint.
Given a sequence of n distinct numbers xk called nodes and for each xk a second number yk, we are looking for a function f so that

A pair xk,yk is called a data point and f is called an interpolant for the data points.
When the numbers yk are given by a known function f, we sometimes write fk.
[edit] Example
For example, suppose we have a table like this, which gives some values of an unknown function f.
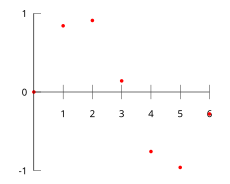
| x | f(x) | ||||
|---|---|---|---|---|---|
| 0 | 0 | ||||
| 1 | 0 | . | 8415 | ||
| 2 | 0 | . | 9093 | ||
| 3 | 0 | . | 1411 | ||
| 4 | −0 | . | 7568 | ||
| 5 | −0 | . | 9589 | ||
| 6 | −0 | . | 2794 | ||
Interpolation provides a means of estimating the function at intermediate points, such as x = 2.5.
There are many different interpolation methods, some of which are described below. Some of the concerns to take into account when choosing an appropriate algorithm are: How accurate is the method? How expensive is it? How smooth is the interpolant? How many data points are needed?
[edit] Piecewise constant interpolation

The simplest interpolation method is to locate the nearest data value, and assign the same value. In one dimension, there are seldom good reasons to choose this one over linear interpolation, which is almost as cheap, but in higher dimensions, in multivariate interpolation, this can be a favourable choice for its speed and simplicity.
[edit] Linear interpolation

One of the simplest methods is linear interpolation (sometimes known as lerp). Consider the above example of determining f(2.5). Since 2.5 is midway between 2 and 3, it is reasonable to take f(2.5) midway between f(2) = 0.9093 and f(3) = 0.1411, which yields 0.5252.
Generally, linear interpolation takes two data points, say (xa,ya) and (xb,yb), and the interpolant is given by:
 at the point (x,y).
at the point (x,y).
Linear interpolation is quick and easy, but it is not very precise. Another disadvantage is that the interpolant is not differentiable at the point xk.
The following error estimate shows that linear interpolation is not very precise. Denote the function which we want to interpolate by g, and suppose that x lies between xa and xb and that g is twice continuously differentiable. Then the linear interpolation error is
![|f(x)-g(x)| \le C(x_b-x_a)^2 \quad\mbox{where}\quad C = \frac18 \max_{y\in[x_a,x_b]} |g''(y)|.](http://upload.wikimedia.org/math/7/c/7/7c7065bca74d828c7161ad651e6bdf5c.png)
In words, the error is proportional to the square of the distance between the data points. The error of some other methods, including polynomial interpolation and spline interpolation (described below), is proportional to higher powers of the distance between the data points. These methods also produce smoother interpolants.
[edit] Polynomial interpolation

Polynomial interpolation is a generalization of linear interpolation. Note that the linear interpolant is a linear function. We now replace this interpolant by a polynomial of higher degree.
Consider again the problem given above. The following sixth degree polynomial goes through all the seven points:
- f(x) = − 0.0001521x6 − 0.003130x5 + 0.07321x4 − 0.3577x3 + 0.2255x2 + 0.9038x.
Substituting x = 2.5, we find that f(2.5) = 0.5965.
Generally, if we have n data points, there is exactly one polynomial of degree at most n−1 going through all the data points. The interpolation error is proportional to the distance between the data points to the power n. Furthermore, the interpolant is a polynomial and thus infinitely differentiable. So, we see that polynomial interpolation solves all the problems of linear interpolation.
However, polynomial interpolation also has some disadvantages. Calculating the interpolating polynomial is computationaly expensive (see computational complexity) compared to linear interpolation. Furthermore, polynomial interpolation may not be so exact after all, especially at the end points (see Runge's phenomenon). These disadvantages can be avoided by using spline interpolation.
[edit] Spline interpolation

Remember that linear interpolation uses a linear function for each of intervals [xk,xk+1]. Spline interpolation uses low-degree polynomials in each of the intervals, and chooses the polynomial pieces such that they fit smoothly together. The resulting function is called a spline.
For instance, the natural cubic spline is piecewise cubic and twice continuously differentiable. Furthermore, its second derivative is zero at the end points. The natural cubic spline interpolating the points in the table above is given by
![f(x) = \left\{ \begin{matrix}
-0.1522 x^3 + 0.9937 x, & \mbox{if } x \in [0,1], \\
-0.01258 x^3 - 0.4189 x^2 + 1.4126 x - 0.1396, & \mbox{if } x \in [1,2], \\
0.1403 x^3 - 1.3359 x^2 + 3.2467 x - 1.3623, & \mbox{if } x \in [2,3], \\
0.1579 x^3 - 1.4945 x^2 + 3.7225 x - 1.8381, & \mbox{if } x \in [3,4], \\
0.05375 x^3 -0.2450 x^2 - 1.2756 x + 4.8259, & \mbox{if } x \in [4,5], \\
-0.1871 x^3 + 3.3673 x^2 - 19.3370 x + 34.9282, & \mbox{if } x \in [5,6]. \\
\end{matrix} \right.](http://upload.wikimedia.org/math/7/4/3/74335a4af989811a2a9d052d4366c080.png)
In this case we get f(2.5)=0.5972.
Like polynomial interpolation, spline interpolation incurs a smaller error than linear interpolation and the interpolant is smoother. However, the interpolant is easier to evaluate than the high-degree polynomials used in polynomial interpolation. It also does not suffer from Runge's phenomenon.
[edit] Interpolation via Gaussian processes
Gaussian process is a powerful non-linear interpolation tool. Many popular interpolation tools are actually equivalent to particular Gaussian processes. Gaussian processes can be used not only for fitting an interpolant that passes exactly through the given data points but also for regression, i.e. for fitting a curve through noisy data. In the geostatistics community Gaussian process regression is also known as Kriging.
[edit] Other forms of interpolation
Other forms of interpolation can be constructed by picking a different class of interpolants. For instance, rational interpolation is interpolation by rational functions, and trigonometric interpolation is interpolation by trigonometric polynomials. The discrete Fourier transform is a special case of trigonometric interpolation. Another possibility is to use wavelets.
The Whittaker–Shannon interpolation formula can be used if the number of data points is infinite.
Multivariate interpolation is the interpolation of functions of more than one variable. Methods include bilinear interpolation and bicubic interpolation in two dimensions, and trilinear interpolation in three dimensions.
Sometimes, we know not only the value of the function that we want to interpolate, at some points, but also its derivative. This leads to Hermite interpolation problems.
[edit] Related concepts
The term extrapolation is used if we want to find data points outside the range of known data points.
In curve fitting problems, the constraint that the interpolant has to go exactly through the data points is relaxed. It is only required to approach the data points as closely as possible. This requires parameterizing the potential interpolants and having some way of measuring the error. In the simplest case this leads to least squares approximation.
Approximation theory studies how to find the best approximation to a given function by another function from some predetermined class, and how good this approximation is. This clearly yields a bound on how well the interpolant can approximate the unknown function.
[edit] References
- David Kidner, Mark Dorey and Derek Smith (1999). What's the point? Interpolation and extrapolation with a regular grid DEM. IV International Conference on GeoComputation, Fredericksburg, VA, USA.
- Kincaid, David; Ward Cheney (2002). Numerical Analysis (3rd edition). Brooks/Cole. ISBN 0-534-38905-8. Chapter 6.
- Schatzman, Michelle (2002). Numerical Analysis: A Mathematical Introduction. Clarendon Press, Oxford. ISBN 0-19-850279-6. Chapters 4 and 6.
[edit] External links
| Wikimedia Commons has media related to: Interpolation |
- GaussianProcesses.com: Theory and applications of Gaussian Processes
- DotPlacer applet : Applet showing various interpolation methods, with movable points

