Centrality
From Wikipedia, the free encyclopedia
Within graph theory and network analysis, there are various measures of the centrality of a vertex within a graph that determine the relative importance of a vertex within the graph (for example, how important a person is within a social network, or, in the theory of space syntax, how important a room is within a building or how well-used a road is within an urban network).
There are four measures of centrality that are widely used in network analysis: degree centrality, betweenness, closeness, and eigenvector centrality.
Contents |
[edit] Degree centrality
The first, and simplest, is degree centrality. Degree centrality is defined as the number of links incident upon a node (i.e., the number of ties that a node has). Degree is often interpreted in terms of the immediate risk of node for catching whatever is flowing through the network (such as a virus, or some information). If the network is directed (meaning that ties have direction), then we usually define two separate measures of degree centrality, namely indegree and outdegree. Indegree is a count of the number of ties directed to the node, and outdegree is the number of ties that the node directs to others. For positive relations such as friendship or advice, we normally interpret indegree as a form of popularity, and outdegree as gregariousness.
For a graph G: = (V,E) with n vertices, the degree centrality CD(v) for vertex v is:

Calculating degree centrality for all nodes V in a graph takes Θ(V2) in a dense adjacency matrix representation of the graph, and for edges E in a graph takes Θ(E) in a sparse matrix representation.
The definition of centrality can be extended to graphs. Let v * be the node with highest degree centrality in G. Let G': = (V',E') be the n node connected graph that maximizes the following quantity:
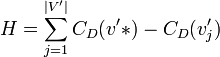
Then the degree centrality of the graph G is defined as follows:
![C_D(G)= \frac{\displaystyle{\sum^{|V|}_{i=1}{[C_D(v*)-C_D(v_i)]}}}{H}](http://upload.wikimedia.org/math/7/5/5/755c1a4f0f1f33c8fbb345d7c4187c7d.png)
H is maximized when the graph G' contains one node that is connected to all other nodes and all other nodes are connected only to this one central node (a star graph). In this case

so the degree centrality of G reduces to:
![C_D(G)= \frac{\displaystyle{\sum^{|V|}_{i=1}{[C_D(v*)-C_D(v_i)]}}}{n-2}](http://upload.wikimedia.org/math/6/2/6/626fe0293c646871eb39e7a637811ec0.png)
[edit] Betweenness centrality
Betweenness is a centrality measure of a vertex within a graph (there is also edge betweenness, which is not discussed here). Vertices that occur on many shortest paths between other vertices have higher betweenness than those that do not.
For a graph G: = (V,E) with n vertices, the betweenness CB(v) for vertex v is:

where σst is the number of shortest geodesic paths from s to t, and σst(v) is the number of shortest geodesic paths from s to t that pass through a vertex v. This may be normalised by dividing through the number of pairs of vertices not including v, which is (n − 1)(n − 2) / 2.
Calculating the betweenness and closeness centralities of all the vertices in a graph involves calculating the shortest paths between all pairs of vertices on a graph. This takes Θ(V3) time with the Floyd–Warshall algorithm, modified to not only find one but count all shortest paths between two nodes. On a sparse graph, Johnson's algorithm may be more efficient, taking O(V2logV + VE) time. On unweighted graphs, calculating betweenness centrality takes O(VE) time using Brandes' algorithm[1].
[edit] Closeness centrality
In topology and related areas in mathematics, closeness is one of the basic concepts in a topological space. Intuitively we say two sets are close if they are arbitrarily near to each other. The concept can be defined naturally in a metric space where a notion of distance between elements of the space is defined, but it can be generalized to topological spaces where we have no concrete way to measure distances.
In graph theory closeness is a centrality measure of a vertex within a graph. Vertices that are 'shallow' to other vertices (that is, those that tend to have short geodesic distances to other vertices with in the graph) have higher closeness. Closeness is preferred in network analysis to mean shortest-path length, as it gives higher values to more central vertices, and so is usually positively associated with other measures such as degree.
In the network theory, closeness is a sophisticated measure of centrality. It is defined as the mean geodesic distance (i.e the shortest path) between a vertex v and all other vertices reachable from it:

where  is the size of the network's 'connectivity component' V reachable from v. Closeness can be regarded as a measure of how long it will take information to spread from a given vertex to other reachable vertices in the network[2].
is the size of the network's 'connectivity component' V reachable from v. Closeness can be regarded as a measure of how long it will take information to spread from a given vertex to other reachable vertices in the network[2].
Some define closeness to be the reciprocal of this quantity, but either ways the information communicated is the same (this time estimating the speed instead of the timespan). The closeness CC(v) for a vertex v is the reciprocal of the sum of geodesic distances to all other vertices of V[3]:

Different methods and algorithms can be introduced to measure closeness, like the random-walk centrality introduced by Noh and Rieger (2003) that is a measure of the speed with which randomly walking messages reach a vertex from elsewhere in the network—a sort of random-walk version of closeness centrality[4].
The information centrality of Stephenson and Zelen (1989) is another closeness measure, which bears some similarity to that of Noh and Rieger. In essence it measures the harmonic mean length of paths ending at a vertex i, which is smaller if i has many short paths connecting it to other vertices[5].
Dangalchev (2006), in order to measure the network vulnerability, modifies the definition for closeness so it can be used for disconnected graphs and the total closeness is easier to calculate[6]:

[edit] Eigenvector centrality
Eigenvector centrality is a measure of the importance of a node in a network. It assigns relative scores to all nodes in the network based on the principle that connections to high-scoring nodes contribute more to the score of the node in question than equal connections to low-scoring nodes. Google's PageRank is a variant of the Eigenvector centrality measure.
[edit] Using the adjacency matrix to find eigenvector centrality
Let xi denote the score of the ith node. Let Ai,j be the adjacency matrix of the network. Hence Ai,j = 1 if the ith node is adjacent to the jth node, and Ai,j = 0 otherwise. More generally, the entries in A can be real numbers representing connection strengths, as in a stochastic matrix.
For the ith node, let the centrality score be proportional to the sum of the scores of all nodes which are connected to it. Hence

where M(i) is the set of nodes that are connected to the ith node, N is the total number of nodes and λ is a constant. In vector notation this can be rewritten as
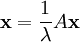 , or as the eigenvector equation
, or as the eigenvector equation 
In general, there will be many different eigenvalues λ for which an eigenvector solution exists. However, the additional requirement that all the entries in the eigenvector be positive implies (by the Perron–Frobenius theorem) that only the greatest eigenvalue results in the desired centrality measure.[7] The ith component of the related eigenvector then gives the centrality score of the ith node in the network. Power iteration is one of many eigenvalue algorithms that may be used to find this dominant eigenvector.
[edit] References
- ^ Ulrik Brandes (PDF). A faster algorithm for betweenness centrality. http://www.cs.ucc.ie/~rb4/resources/Brandes.pdf.
- ^ Newman, MEJ, 2003, Arxiv preprint cond-mat/0309045.
- ^ Sabidussi, G. (1966) The centrality index of a graph. Psychometrika 31, 581--603.
- ^ J. D. Noh and H. Rieger, Phys. Rev. Lett. 92, 118701 (2004).
- ^ Stephenson, K. A. and Zelen, M., 1989. Rethinking centrality: Methods and examples. Social Networks 11, 1–37.
- ^ Dangalchev Ch., Residual Closeness in Networks, Phisica A 365, 556 (2006).
- ^ M. E. J. Newman (PDF). The mathematics of networks. http://www-personal.umich.edu/~mejn/papers/palgrave.pdf. Retrieved on 2006-11-09.
[edit] Further reading
- Freeman, L. C. (1979). Centrality in social networks: Conceptual clarification. Social Networks, 1(3), 215-239.
- Sabidussi, G. (1966). The centrality index of a graph. Psychometrika, 31 (4), 581-603.
- Freeman, L. C. (1977) A set of measures of centrality based on betweenness. Sociometry 40, 35--41.
- Koschützki, D.; Lehmann, K. A.; Peeters, L.; Richter, S.; Tenfelde-Podehl, D. and Zlotowski, O. (2005) Centrality Indices. In Brandes, U. and Erlebach, T. (Eds.) Network Analysis: Methodological Foundations, pp. 16–61, LNCS 3418, Springer-Verlag.

