Log-normal distribution
From Wikipedia, the free encyclopedia
Probability density function μ=0 |
|
Cumulative distribution function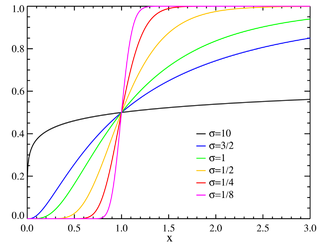 μ=0 |
|
| Parameters | σ > 0 |
|---|---|
| Support |  |
| Probability density function (pdf) | ![\frac{1}{x\sigma\sqrt{2\pi}}\exp\left[-\frac{\left(\ln(x)-\mu\right)^2}{2\sigma^2}\right]](http://upload.wikimedia.org/math/b/3/f/b3f2a95779f28c24a5a265ba6498ceec.png) |
| Cumulative distribution function (cdf) | ![\frac{1}{2}+\frac{1}{2} \mathrm{erf}\left[\frac{\ln(x)-\mu}{\sigma\sqrt{2}}\right]](http://upload.wikimedia.org/math/2/5/3/253b03515b12e5affd383a2c2f022145.png) |
| Mean |  |
| Median |  |
| Mode |  |
| Variance |  |
| Skewness |  |
| Excess kurtosis |  |
| Entropy |  |
| Moment-generating function (mgf) | (see text for raw moments) |
| Characteristic function | needs your contribution |
In probability and statistics, the log-normal distribution is the single-tailed probability distribution of any random variable whose logarithm is normally distributed. If X is a random variable with a normal distribution, then Y = exp(X) has a log-normal distribution; likewise, if Y is log-normally distributed, then log(Y) is normally distributed. (The base of the logarithmic function does not matter: if loga(Y) is normally distributed, then so is logb(Y), for any two positive numbers a, b ≠ 1.)
Log-normal is also written log normal or lognormal.
A variable might be modeled as log-normal if it can be thought of as the multiplicative product of many independent random variables each of which is positive. For example, in finance, a long-term discount factor can be derived from the product of short-term discount factors. In wireless communication, the attenuation caused by shadowing or slow fading from random objects is often assumed to be log-normally distributed. See log-distance path loss model.
Contents |
[edit] Characterization
[edit] Probability density function
The log-normal distribution has the probability density function

for x > 0, where μ and σ are the mean and standard deviation of the variable's natural logarithm (by definition, the variable's logarithm is normally distributed).
[edit] Cumulative distribution function
[edit] Properties
[edit] Mean and standard deviation
If X is a lognormally distributed variable, its expected value (mean) is

and its variance is

hence the standard deviation is

Equivalent relationships may be written to obtain  and
and 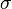 given the expected value and variance:
given the expected value and variance:


[edit] Mode and median
The mode is

The median is

[edit] Geometric mean and geometric standard deviation
The geometric mean of the log-normal distribution is  , and the geometric standard deviation is equal to
, and the geometric standard deviation is equal to  .
.
If a sample of data is determined to come from a log-normally distributed population, the geometric mean and the geometric standard deviation may be used to estimate confidence intervals akin to the way the arithmetic mean and standard deviation are used to estimate confidence intervals for a normally distributed sample of data.
| Confidence interval bounds | log space | geometric |
|---|---|---|
| 3σ lower bound |  |
 |
| 2σ lower bound |  |
 |
| 1σ lower bound |  |
 |
| 1σ upper bound |  |
 |
| 2σ upper bound |  |
 |
| 3σ upper bound |  |
 |
Where geometric mean  and geometric standard deviation
and geometric standard deviation 
[edit] Moments
For any real number s, the sth moment is given by

A log-normal distribution is not uniquely determined by its moments E(Xk) for k ≥ 1, that is, there exists some other distribution with the same moments for all k.
[edit] Moment generating function
The moment-generating function for the log-normal distribution does not exist on the domain R, but the moment generating function does exist on (−∞, 0]. The set {t : g(t) < ∞}, where g is the moment-generating function, contains (−∞, 0].
[edit] Partial expectation
The partial expectation of a random variable X with respect to a threshold k is defined as

where 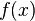 is the density. For a lognormal density it can be shown that
is the density. For a lognormal density it can be shown that

where  is the cumulative distribution function of the standard normal. The partial expectation of a lognormal has applications in insurance and in economics (for example it can be used to derive the Black–Scholes formula).
is the cumulative distribution function of the standard normal. The partial expectation of a lognormal has applications in insurance and in economics (for example it can be used to derive the Black–Scholes formula).
[edit] Maximum likelihood estimation of parameters
For determining the maximum likelihood estimators of the log-normal distribution parameters μ and σ, we can use the same procedure as for the normal distribution. To avoid repetition, we observe that

where by ƒL we denote the probability density function of the log-normal distribution and by ƒN that of the normal distribution. Therefore, using the same indices to denote distributions, we can write the log-likelihood function thus:

Since the first term is constant with regard to μ and σ, both logarithmic likelihood functions,  and
and  , reach their maximum with the same μ and σ. Hence, using the formulas for the normal distribution maximum likelihood parameter estimators and the equality above, we deduce that for the log-normal distribution it holds that
, reach their maximum with the same μ and σ. Hence, using the formulas for the normal distribution maximum likelihood parameter estimators and the equality above, we deduce that for the log-normal distribution it holds that

[edit] Generating Log-normally-distributed random variates
Given a random variate N drawn from the normal distribution with 0 mean and 1 standard deviation, then the variate

has a Log-normal distribution with parameters μ and σ.
[edit] Related distributions
- If
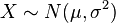 is a normal distribution then
is a normal distribution then  .
. - If
 is a log-normally distributed random variable then ln(Y)˜N(μ,σ2) is a normally distributed random variable.
is a log-normally distributed random variable then ln(Y)˜N(μ,σ2) is a normally distributed random variable. - If
 are independent log-normally distributed variables with the same μ parameter and possibly varying σ, and
are independent log-normally distributed variables with the same μ parameter and possibly varying σ, and  , then Y is a log-normally distributed variable as well:
, then Y is a log-normally distributed variable as well:

- Let
 be independent log-normally distributed variables with
be independent log-normally distributed variables with
possibly varying σ and μ parameters, and  . The distribution of Y has no closed-form expression, but can be reasonably approximated by another log-normal distribution Z at the right tail. Its probability density function at the neighborhood of 0 is characterized in (Gao et al., 2009) and it does not resemble any log-normal distribution. A commonly used approximation (due to Fenton and Wilkinson) is obtained by matching the mean and variance:
. The distribution of Y has no closed-form expression, but can be reasonably approximated by another log-normal distribution Z at the right tail. Its probability density function at the neighborhood of 0 is characterized in (Gao et al., 2009) and it does not resemble any log-normal distribution. A commonly used approximation (due to Fenton and Wilkinson) is obtained by matching the mean and variance:
![\sigma^2_Z = \log\left[ \frac{\sum e^{2\mu_m+\sigma_m^2}(e^{\sigma_m^2}-1)}{(\sum e^{\mu_m+\sigma_m^2/2})^2}+1\right]](http://upload.wikimedia.org/math/1/4/8/148689a120e1fcc7b1476ad6519d3a58.png)

In the case that all Xm have the same variance parameter σm = σ, these formulas simplify to
![\sigma^2_Z = \log\left[ (e^{\sigma^2}-1)\frac{\sum e^{2\mu_m}}{(\sum e^{\mu_m})^2}+1\right]](http://upload.wikimedia.org/math/0/b/0/0b0471c37ff2e0256f965846a64bfcc8.png)

- A substitute for the log-normal whose integral can be expressed in terms of more elementary functions (Swamee, 2002) can be obtained based on the logistic distribution to get the CDF
![F(x;\mu,\sigma) = \left[\left(\frac{e^\mu}{x}\right)^{\pi/(\sigma \sqrt{3})} +1\right]^{-1}.](http://upload.wikimedia.org/math/4/5/6/456274822de33ada09d28242305be392.png)
This is a log-logistic distribution.
- If
 then X + c is called shifted log-normal.
then X + c is called shifted log-normal.
[edit] Further reading
- Robert Brooks, Jon Corson, and J. Donal Wales. "The Pricing of Index Options When the Underlying Assets All Follow a Lognormal Diffusion", in Advances in Futures and Options Research, volume 7, 1994.
[edit] References
- The Lognormal Distribution, Aitchison, J. and Brown, J.A.C. (1957)
- Log-normal Distributions across the Sciences: Keys and Clues, E. Limpert, W. Stahel and M. Abbt,. BioScience, 51 (5), p. 341–352 (2001).
- Eric W. Weisstein et al. Log Normal Distribution at MathWorld. Electronic document, retrieved October 26, 2006.
- Swamee, P.K. (2002). Near Lognormal Distribution, Journal of Hydrologic Engineering. 7(6): 441-444
- Roy B. Leipnik (1991), On Lognormal Random Variables: I - The Characteristic Function, Journal of the Australian Mathematical Society Series B, vol. 32, pp 327–347.
- Gao et al. (2009) [1], Asymptotic Behaviors of Tail Density for Sum of Correlated Lognormal Variables". International Journal of Mathematics and Mathematical Sciences.
[edit] See also
- Normal distribution
- Geometric mean
- Geometric standard deviation
- Error function
- Log-distance path loss model
- Slow fading

