Bucket sort
From Wikipedia, the free encyclopedia
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | O(?) |
| Optimal | ? |
|
|
This article is in need of attention from an expert on the subject. WikiProject Computer science or the Computer science Portal may be able to help recruit one. (November 2008) |
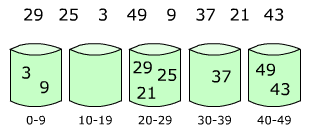

Bucket sort, or bin sort, is a sorting algorithm that works by partitioning an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm. It is a cousin of radix sort in the most to least significant digit flavour. Bucket sort is a generalization of pigeonhole sort. Since bucket sort is not a comparison sort, the Ω(n log n) lower bound is inapplicable. The computational complexity estimates involve the number of buckets.
Bucket sort works as follows:
- Set up an array of initially empty "buckets."
- Scatter: Go over the original array, putting each object in its bucket.
- Sort each non-empty bucket.
- Gather: Visit the buckets in order and put all elements back into the original array.
A common optimization is to put the elements back in the original array first, then run insertion sort over the complete array; because insertion sort's runtime is based on how far each element is from its final position, the number of comparisons remains relatively small, and the memory hierarchy is better exploited by storing the list contiguously in memory.[1]
The most common variant of bucket sort operates on a list of n numeric inputs between zero and some maximum value M and divides the value range into n buckets each of size M/n. If each bucket is sorted using insertion sort, the sort can be shown to run in expected linear time (where the average is taken over all possible inputs).[2] However, the performance of this sort degrades with clustering; if many values occur close together, they will all fall into a single bucket and be sorted slowly.
Another variant of bucket sort known as histogram sort adds an initial pass that counts the number of elements that will fall into each bucket using a count array. Using this information, the array values can be arranged into a sequence of buckets in-place by a sequence of exchanges, so that there is no space overhead for bucket storage.[3]
Contents |
[edit] Pseudocode
function bucket-sort(array, n) is
buckets ← new array of n empty lists
for i = 0 to (length(array)-1) do
insert array[i] into buckets[msbits(array[i], k)]
for i = 0 to n - 1 do
next-sort(buckets[i])
return the concatenation of buckets[0], ..., buckets[n-1]
Here array is the array to be sorted and n is the number of buckets to use. The function msbits(x,k) returns the k most significant bits of x (floor(x/2^(size(x)-k))); different functions can be used to translate the range of elements in array to n buckets, such as translating the letters A-Z to 0-25 or returning the first character (0-255) for sorting strings. The function next-sort is a sorting function; using bucket-sort itself as next-sort produces a relative of radix sort; in particular, the case n = 2 corresponds to quicksort (although potentially with poor pivot choices).
[edit] Postman's sort
The Postman's sort is a variant of bucket sort that takes advantage of a hierarchical structure of elements, typically described by a set of attributes. This is the algorithm used by letter-sorting machines in the post office: first states, then post offices, then routes, etc. Since keys are not compared against each other, sorting time is O(cn), where c depends on the size of the key and number of buckets. This is similar to a radix sort that works "top down," or "most significant digit first."[4]
[edit] Comparison with other sorting algorithms
Bucket sort can be seen as a generalization of counting sort; in fact, if each bucket has size 1 then bucket sort degenerates to counting sort. The variable bucket size of bucket sort allows it to use O(n) memory instead of O(M) memory, where M is the number of distinct values; in exchange, it gives up counting sort's O(n + M) worst-case behavior.
Bucket sort with two buckets is effectively a version of quicksort where the pivot value is always selected to be the middle value of the value range. While this choice is effective for uniformly distributed inputs, other means of choosing the pivot in quicksort such as randomly selected pivots make it more resistant to clustering in the input distribution.
The n-way mergesort algorithm also begins by distributing the list into n sublists and sorting each one; however, the sublists created by mergesort have overlapping value ranges and so cannot be recombined by simple concatenation as in bucket sort. Instead, they must be interleaved by a merge algorithm. However, this added expense is counterbalanced by the simpler scatter phase and the ability to ensure that each sublist is the same size, providing a good worst-case time bound.
Top-down radix sort can be seen as a special case of bucket sort where both the range of values and the number of buckets is constrained to be a power of two. Consequently, each bucket's size is also a power of two, and the procedure can be applied recursively. This approach can accelerate the scatter phase, since we only need to examine a prefix of the bit representation of each element to determine its bucket.
[edit] References
- ^ Corwin, E. and Logar, A. Sorting in linear time — variations on the bucket sort. Journal of Computing Sciences in Colleges, 20, 1, pp.197–202. October 2004.
- ^ Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Section 8.4: Bucket sort, pp.174–177.
- ^ NIST's Dictionary of Algorithms and Data Structures: histogram sort
- ^ http://www.rrsd.com/psort/cuj/cuj.htm
- Paul E. Black "Postman's Sort" from Dictionary of Algorithms and Data Structures at NIST.
- Robert Ramey The Postman's Sort C Users Journal Aug. 1992
- NIST's Dictionary of Algorithms and Data Structures: bucket sort
[edit] External links
|
||||||||||||||||||||||||||||