Apriori algorithm
From Wikipedia, the free encyclopedia
|
|
This article may be confusing or unclear to readers. Please help clarify the article; suggestions may be found on the talk page. (December 2006) |
In computer science and data mining, Apriori is a classic algorithm for learning association rules. Apriori is designed to operate on databases containing transactions (for example, collections of items bought by customers, or details of a website frequentation). Other algorithms are designed for finding association rules in data having no transactions (Winepi and Minepi), or having no timestamps (DNA sequencing).
As is common in association rule mining, given a set of itemsets (for instance, sets of retail transactions, each listing individual items purchased), the algorithm attempts to find subsets which are common to at least a minimum number C of the itemsets. Apriori uses a "bottom up" approach, where frequent subsets are extended one item at a time (a step known as candidate generation), and groups of candidates are tested against the data. The algorithm terminates when no further successful extensions are found.
Apriori uses breadth-first search and a tree structure to count candidate item sets efficiently. It generates candidate item sets of length k from item sets of length k − 1. Then it prunes the candidates which have an infrequent sub pattern. According to the downward closure lemma, the candidate set contains all frequent k-length item sets. After that, it scans the transaction database to determine frequent item sets among the candidates.
Apriori, while historically significant, suffers from a number of inefficiencies or trade-offs, which have spawned other algorithms. Candidate generation generates large numbers of subsets (the algorithm attempts to load up the candidate set with as many as possible before each scan). Bottom-up subset exploration (essentially a breadth-first traversal of the subset lattice) finds any maximal subset S only after all 2 | S | − 1 of its proper subsets.
Contents |
[edit] Example
A large supermarket tracks sales data by SKU (item), and thus is able to know what items are typically purchased together. Apriori is a moderately efficient way to build a list of frequent purchased item pairs from this data. Let the database of transactions consist of the sets {1,2,3,4}, {2,3,4}, {2,3}, {1,2,4}, {1,2,3,4}, and {2,4}. Each number corresponds to a product such as "butter" or "water". The first step of Apriori to count up the frequencies, called the supports, of each member item separately:
| Item | Support |
| 1 | 3 |
| 2 | 6 |
| 3 | 4 |
| 4 | 5 |
We can define a minimum support level to qualify as "frequent," which depends on the context. For this case, let min support = 3. Therefore, all are frequent. The next step is to generate a list of all 2-pairs of the frequent items. Had any of the above items not been frequent, they wouldn't have been included as a possible member of possible 2-item pairs. In this way, Apriori prunes the tree of all possible sets.
| Item | Support |
| {1,2} | 3 |
| {1,3} | 2 |
| {1,4} | 3 |
| {2,3} | 4 |
| {2,4} | 5 |
| {3,4} | 3 |
This is counting up the occurences of each of those pairs in the database. Since minsup=3, we don't need to generate 3-sets involving {1,3}. This is due to the fact that since they're not frequent, no supersets of them can possibly be frequent. Keep going:
| Item | Support |
| {1,2,4} | 3 |
| {2,3,4} | 3 |
Note that {1,2,3} and {1,3,4} were not generated or tested. At this point, since the only 4-set is {1,2,3,4} and its subset {1,3} has been ruled out as infrequent.
In much larger datasets, especially those with huge amounts of items present in low quantities and small amounts of items present in big quantities, the gains made by pruning the possible pairs tree like this can be very large.
[edit] Algorithm
Association rule mining is to find out association rules that satisfy the predefined minimum support and confidence from a given database. The problem is usually decomposed into two subproblems. One is to find those itemsets whose occurrences exceed a predefined threshold in the database; those itemsets are called frequent or large itemsets. The second problem is to generate association rules from those large itemsets with the constraints of minimal confidence. Suppose one of the large itemsets is Lk, Lk = {I1, I2, … , Ik}, association rules with this itemsets are generated in the following way: the first rule is {I1, I2, … , Ik-1}⇒ {Ik}, by checking the confidence this rule can be determined as interesting or not. Then other rule are generated by deleting the last items in the antecedent and inserting it to the consequent, further the confidences of the new rules are checked to determine the interestingness of them. Those processes iterated until the antecedent becomes empty. Since the second subproblem is quite straight forward, most of the researches focus on the first subproblem. The Apriori algorithm finds the frequent sets L In Database D.
- Find frequent set Lk − 1.
- Join Step.
- Ck is generated by joining Lk − 1with itself
- Prune Step.
- Any (k − 1) -itemset that is not frequent cannot be a subset of a frequent k -itemset, hence should be removed.
where
- (Ck: Candidate itemset of size k)
- (Lk: frequent itemset of size k)
[edit] Apriori Pseudocode
Apriori 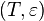
 large 1-itemsets that appear in more than
large 1-itemsets that appear in more than  transactions }
transactions }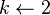
- while
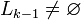
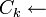 Generate(Lk − 1)
Generate(Lk − 1)- for transactions

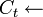 Subset(Ck,t)
Subset(Ck,t)- for candidates

![L_k \gets \{ c \in C_k | ~ \mathrm{count}[c] \geq \varepsilon \}](http://upload.wikimedia.org/math/e/2/5/e253ec74177267730cc9561eca5366ba.png)
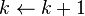
- while
- return

![\mathrm{count}[c] \gets \mathrm{count}[c]+1](http://upload.wikimedia.org/math/f/b/f/fbf3b2b3ed53598ed2bb75b9dc313839.png)
[edit] References
- Agrawal R, Imielinski T, Swami AN. "Mining Association Rules between Sets of Items in Large Databases." SIGMOD. June 1993, 22(2):207-16, pdf.
- Agrawal R, Srikant R. "Fast Algorithms for Mining Association Rules", VLDB. Sep 12-15 1994, Chile, 487-99, pdf/pdf, ISBN 1-55860-153-8.
- Mannila H, Toivonen H, Verkamo AI. "Efficient algorithms for discovering association rules." AAAI Workshop on Knowledge Discovery in Databases (SIGKDD). July 1994, Seattle, 181-92, ps.
- S. Kotsiantis, D. Kanellopoulos, Association Rules Mining: A Recent Overview, GESTS International Transactions on Computer Science and Engineering, Vol.32 (1), 2006, pp. 71-82 (http://www.math.upatras.gr/~esdlab/en/members/kotsiantis/association%20rules%20kotsiantis.pdf)

