Item response theory
From Wikipedia, the free encyclopedia
In psychometrics, item response theory (IRT: also known as latent trait theory, strong true score theory, or modern mental test theory) is a body of theory describing the application of mathematical models to data from questionnaires and tests as a basis for measuring abilities, attitudes, or other variables. It is used for statistical analysis and development of assessments, often for high stakes tests such as the Graduate Record Examination. At its most basic level, it is based on the idea that the probability of getting an item correct is a function of a latent trait or ability. For example, a person with higher intelligence would be more likely to correctly respond to a given item on an intelligence test.
Formally, IRT models apply mathematical functions that specify the probability of a discrete outcome, such as a correct response to an item, in terms of person and item parameters. Person parameters may, for example, represent the ability of a student or the strength of a person's attitude. Item parameters include difficulty (location), discrimination (slope or correlation), and pseudoguessing (lower asymptote). Items may be questions that have incorrect and correct responses, statements on questionnaires that allow respondents to indicate level of agreement, or patient symptoms scored present/absent.
Among other things, the purpose of IRT is to provide a framework for evaluating how well assessments work, and how well individual questions on assessments work. In education, psychometricians apply IRT in order to achieve tasks such as developing and refining exams, maintaining banks of items for exams, and equating for the difficulties of successive versions of exams (for example, to allow comparisons between results over time).[1]
While the concept of the item response function has been around since before 1950, the pioneering work of IRT as a theory occurred during the 1950s and 1960s. Three of the pioneers were the Educational Testing Service psychometrician Frederic M. Lord[2], the Danish mathematician Georg Rasch, and Austrian sociologist Paul Lazarsfeld, who pursued parallel research independently. However, while the mathematical groundwork was laid earlier, IRT did not become widely used until the late 1970s and 1980s when the advent of the personal computer provided the computer power necessary to a greater number of researchers.
Contents |
[edit] Overview
IRT models are used as a basis for statistical estimation of parameters that represent the 'locations' of persons and items on a latent continuum or, more correctly, the magnitude of the latent trait attributable to the persons and items. For example, in attainment testing, estimates may be of the magnitude of a person's ability within a specific domain, such as reading comprehension. Once estimates of relevant parameters have been obtained, statistical tests are usually conducted to gauge the extent to which the parameters predict item responses given the model used. Stated somewhat differently, such tests are used to ascertain the degree to which the model and parameter estimates can account for the structure of and statistical patterns within the response data, either as a whole, or by considering specific subsets of the data such as response vectors pertaining to individual items or persons. This approach permits the central hypothesis represented by a particular model to be subjected to empirical testing, as well as providing information about the psychometric properties of a given assessment, and therefore also the quality of estimates.
From the perspective of more traditional approaches, such as classical test theory, an advantage of IRT is that it potentially provides information that enables a researcher to improve the reliability of an assessment. This is achieved through the extraction of more sophisticated information regarding psychometric properties of individual assessment items. IRT is sometimes referred to using the word strong as in strong true score theory or modern as in modern mental test theory because IRT is a more recent body of theory and makes more explicit the hypotheses that are implicit within Classical test theory.
IRT models are often referred to as latent trait models. The term latent is used to emphasise that discrete item responses are taken to be observable manifestations of hypothesized trait, construct, or attribute, not directly observed, but which must be inferred from the manifest responses. Latent trait models were developed in the field of sociology, but are virtually identitical to IRT models.
The other major body of psychometric theory of relevance to IRT is classical test theory. For tasks that can be accomplished using classical test theory, IRT generally brings greater flexibility and provides more sophisticated information. Some applications, such as computerized adaptive testing are enabled by IRT and cannot reasonably be performed using only classical test theory.
[edit] The Item Characteristic Curve
The performance of an item in a test is described by the item characteristic curve (ICC). The curve gives the probability that a person with a given ability level will answer the item correctly.Persons with lower ability (<0.0) have less of a chance, while persons with high ability are very likely to answer correctly.

Much of the literature on IRT centers on item response models for the ICC. A given model describes the probability of a correct response to the item as a function of a person or ability parameter (or, in the case of multidimensional item response theory, a vector of person parameters). This probability depends on one or more item parameters for the item response function (IRF). For example, in the three parameter logistic (3PL) model, the probability of a correct response to an item i is:

where θ is the person (ability) parameter and ai, bi, and ci are the item parameters.
The item parameters simply determine the shape of the IRF and in some cases have a direct interpretation. The figure to the right depicts an example of the 3PL model of the ICC with an overlaid conceptual explanation of the parameters. The parameter bi represents the item location which, in the case of attainment testing, is referred to as the item difficulty. It is point on θ where the IRF has its maximum slope. The example item is of medium difficulty, since bi=0.0, which is near the center of the distribution. Note that this model scales the item's difficulty and the person's trait onto the same continuum. Thus, it is valid to talk about an item being about as hard as Person A's trait level or of a person's trait level being about the same as Item Y's difficulty, in the sense that successful performance of the task involved with an item reflects a specific level of ability.
The item parameter ai represents the discrimination of the item: that is, the degree to which the item discriminates between persons in different regions on the latent continuum. This parameter characterizes the slope of the IRF where the slope is at its maximum. The example item has ai=1.0, which discriminates fairly well; persons with low ability do indeed have a much smaller chance of correctly responding than persons of higher ability.
For items such as multiple choice items, the parameter ci is used in attempt to account for the effects of guessing on the probability of a correct response. It indicates the probability that very low ability individuals will get this item correct by chance, mathematically represented as a lower asymptote. A four-option multiple choice item might have an IRF like the example item; there is a 1/4 chance of an extremely low ability candidate guessing the correct answer, so the ci would be approximately 0.25. This approach assumes that all options are equally plausible, because if one option made no sense, even the lowest ability person would be able to discard it, so IRT parameter estimation methods take this into account and estimate a ci based on the observed data.[3]
The person parameter θ represents the magnitude of latent trait of the individual. The estimate of the person parameter is derived from the individual's total score on the assessment, which is a weighted score when the model contains item discrimination parameters. The latent trait is the human capacity or attribute measured by the test.[4] It might be a cognitive ability, physical ability, skill, knowledge, attitude, personality characteristic, etc.
[edit] IRT Models
Broadly speaking, IRT models can be divided into two families: unidimensional and multidimensional. Unidimensional models require a single trait (ability) dimension θ. Multidimensional IRT models model response data hypothesized to arise from multiple traits. However, because of the greatly increased complexity, the majority of IRT research and applications utilize a unidimensional model.
IRT models can also be categorized based on the number of scored responses. The typical multiple choice item is dichotomous; even though there may be four or five options, it is still scored only as correct/incorrect (right/wrong). Another class of models apply to polytomous outcomes, where each response has a different score value. For example, the polytomous Rasch model is a generalisation of the Rasch model that applies to data in two or more ordered categories. A common example of this Likert-type items, e.g., "Rate on a scale of 1 to 5."
[edit] Number of IRF parameters
Dichotomous IRT models are described by the number of parameters they make use of.[5] The 3PL is named so because it employs three item parameters. The two-parameter model (2PL) assumes that the data has minimal guessing, but that items can vary in terms of location (bi) and discrimination (ai). The one-parameter model (1PL) assumes that there is minimal guessing and that items have equivalent discriminations, so that items are only described by a single parameter (bi). Additionally, there is theoretically a four-parameter model, with an upper asymptote. However, this is rarely used. This naming is somewhat confusing; note that it does not follow alphabetical order. The 1PL uses only bi, the 2PL uses bi and ai, and the 3PL adds ci.
The 2PL is equivalent to the 3PL model with ci = 0, and is appropriate for testing items where guessing the correct answer is highly unlikely, such as attitude items. For example, guessing is not relevant for the item "I like Broadway musicals," with responses of agree/disagree.
The 1PL assumes not only that guessing is irrelevant, but that all items are equivalent in terms of discrimination. Here, the trait is analogous to a single factor in factor analysis. In fact, one can estimate a normal-ogive latent trait model by factor-analyzing a matrix of tetrachoric correlations between items.[6] This means it is technically possible to estimate a simple IRT model using general-purpose statistical software. Individual items or individuals might have secondary factors but these are assumed to be mutually independent and collectively orthogonal.
[edit] Logistic and Normal IRT Models
An alternative formulation constructs IRFs based on the cumulative normal probability distribution function, or normal cdf; these are sometimes called normal ogive models. For example, the formula for a two-parameter normal-ogive IRF is:

The normal-ogive model derives from the assumption of normally distributed measurement error and is theoretically appealing on that basis. Here bi is, again, the difficulty parameter. The discrimination parameter is σi, the standard deviation of the measurement error for item i, and comparable to 1/ai.
With rescaling of the ability parameter, it is possible to make the 2PL logistic model closely approximate the cumulative normal ogive. Typically, the 2PL logistic and normal-ogive IRFs differ in probability by no more than 0.01 across the range of the function. The difference is greatest in the distribution tails, however, which tend to have more influence on results.
The latent trait/IRT model was originally developed using normal ogives, but, at the time this was considered too computationally demanding for the computers at the time (1960s). The logistic model was proposed as a simpler alternative, and has enjoyed wide use since. More recently, however, it was demonstrated that, using standard polynomial approximations to the normal cdf,[7] the normal-ogive model is no more computationally demanding than logistic models.[8]
[edit] Perspectives on Rasch models: the data-model relationship
The Rasch model for dichotomous data is often regarded as a special case of the two parameter logistic (2PL) model, and therefore the 3PL model. Andrich[9] referred to two prevailing views on the relationship between Lord's 3PL and Rasch's model. In one, the 3PL is a generalisation of the Rasch model because if the relevant parameters are specified as 0 and 1, the 3PL reduces to the Rasch model. In the other view, the 3PL is not a generalisation of the Rasch model because the 3PL cannot follow mathematically from Rasch's[10] specifications for the invariance of comparisons, which follows from the separability of the parameters.
Before identifying the widely known Rasch model for dichotomous data, Rasch employed the Poisson distribution as model for measurement. This model shares with the dichotomous model the property of separability of person and item parameters. If Rasch models are defined in terms of this distinguishing property, then the 2PL and 3PL are not generalisations of the Rasch model because they fail to preserve this property. Consistent with this, the 2PL and 3PL have no well-defined connection to Rasch's multiplicative Poisson model. Thus, whether the Rasch model is seen as a specifical case of IRT models is a matter of both the definition of what is a Rasch model, and the perceived purpose of using an item response model.
IRT models are generally used with the intention of describing a set of data as well as possible. Parameters are modified and accepted or rejected based on how well they fit the data. In contrast, when the Rasch model is employed, the objective is to obtain data which conform with the model in order to meet requirements of measurement.[11] Rasch[12] showed the congruence of the separability of parameters with measurement in the physical sciences. Accordingly, proponents of Rasch measurement models assert that only data which conform with Rasch models satisfy the requirements of fundamental measurement.[13] This entails the researcher deleting any data that they feel does not conform to the model they wish to use.[14] Estimation of parameters is more straight forward in Rasch models due to the presence of sufficient statistics.[15]
From the perspective of modeling data, however, the Rasch model is a special case of the 2PL and hence it is often referred to as the one parameter model. The reason for the name two parameter logistic model is that the discrimination parameter is conceived as a second item parameter. This label implies that discrimination parameters are conceived as pertaining only to items, whereas Rasch[16] emphasized the importance of the frame of reference for measurement as a whole. In the Rasch framework, therefore, discrimination cannot be regarded as something pertaining only to items. This is an additional distinction between the perspectives inherent in the use of the different models and the terminology employed by different authors.
[edit] Information
One of the major contributions of item response theory is the extension of the concept of reliability. Traditionally, reliability refers to the precision of measurement (i.e., the degree to which measurement is free of error). And traditionally, it is measured using a single index defined in various ways, such as the ratio of true and observed score variance. This index is helpful in characterizing a test's average reliability, for example in order to compare two tests. But IRT makes it clear that precision is not uniform across the entire range of test scores. Scores at the edges of the test's range, for example, generally have more error associated with them than scores closer to the middle of the range.
Item response theory advances the concept of item and test information to replace reliability. Information is also a function of the model parameters. For example, according to Fisher information theory, the item information supplied in the case of the Rasch model for dichotomous response data is simply the probability of a correct response multiplied by the probability of an incorrect response, or,
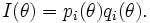
The standard error of estimation (SE) is the reciprocal of the test information of at a given trait level, is the

Thus more information implies less error of measurement.
For other models, such as the two and three parameters models, the discrimination parameter plays an important role in the function. The item information function for the two parameter model is

In general, item information functions tend to look bell-shaped. Highly discriminating items have tall, narrow information functions; they contribute greatly but over a narrow range. Less discriminating items provide less information but over a wider range.
Plots of item information can be used to see how much information an item contributes and to what portion of the scale score range. Because of local independence, item information functions are additive. Thus, the test information function is simply the sum of the information functions of the items on the exam. Using this property with a large item bank, test information functions can be shaped to control measurement error very precisely.
Characterizing the accuracy of test scores is perhaps the central issue in psychometric theory and is a chief difference between IRT and CTT. IRT findings reveal that the CTT concept of reliability is a simplification. In the place of reliability, IRT offers the test information function which shows the degree of precision at different values of theta.
These results allow psychometricians to (potentially) carefully shape the level of reliability for different ranges of ability by including carefully chosen items. For example, in a certification situation in which a test can only be passed or failed, where there is only a single "cutscore," and where the actually passing score is unimportant, a very efficient test can be developed by selecting only items that have high information near the cutscore. These items generally correspond to items whose difficulty is about the same as that of the cutscore.
[edit] Scoring
After the model is fit to data, each person can be scored with IRT, which provides a θ estimate. This "IRT score" is computed and interpreted in a very different manner as compared to traditional scores like number or percent correct. However, for most tests, the (linear) correlation between the theta estimate and a traditional score is very high; often it is .95 or more. A graph of IRT scores against traditional scores shows an ogive shape implying that the IRT estimates separate individuals at the borders of the range more than in the middle.
An important difference between CTT and IRT is the treatment of measurement error. All tests, questionnaires, and inventories are imprecise tools; we can never know a person's true score, but rather only have an estimate, the observed score. There is some amount of random error which may push the observed score higher or lower than the true score. CTT assumes that the amount of error is the same for each examinee, but IRT allows it to vary.
Also, nothing about IRT refutes human development or improvement or assumes that a trait level is fixed. A person may learn skills, knowledge or even so called "test-taking skills" which may translate to a higher true-score. In fact, a portion of IRT research focuses on the measurement of change in trait level.[17]
[edit] A comparison of classical and Item Response theory
Classical test theory (CTT) and IRT are largely concerned with the same problems but are different bodies of theory and therefore entail different methods. Although the two paradigms are generally consistent and complementary, there are a number of points of difference:
- IRT makes stronger assumptions than CTT and in many cases provides correspondingly stronger findings; primarily, characterizations of error. Of course, these results only hold when the assumptions of the IRT models are actually met.
- Although CTT results have allowed important practical results, the model-based nature of IRT affords many advantages over analogous CTT findings.
- CTT test scoring procedures have the advantage of being simple to compute (and to explain) whereas IRT scoring generally requires relatively complex estimation procedures (note that in the Rasch model the total score for a person is the sufficient statistic of the person parameter).
- IRT provides several improvements in scaling items and people. The specifics depend upon the IRT model, but most models scale the difficulty of items and the ability of people on the same metric. Thus the difficulty of an item and the ability of a person can be meaningfully compared.
- Another improvement provided by IRT is that the parameters of IRT models are generally not sample- or test-dependent whereas true-score is defined in CTT in the context of a specific test. Thus IRT provides significantly greater flexibility in situations where different samples or test forms are used. These IRT findings are foundational for computerized adaptive testing.
It is worth also mentioning some specific similarities between CTT and IRT which help to understand the correspondence between concepts. First, Lord[18] showed that under the assumption that θ is normally distributed, discrimination in the 2PL model is approximately a monotonic function of the point-biserial correlation. In particular:

where ρit is the point biserial correlation of item i. Thus, if the assumption holds, where there is a higher discrimination there will generally be a higher point-biserial correlation.
Another similarity is that while IRT provides for a standard error of each estimate and an information function, it is also possible to obtain an index for a test as a whole which is directly analogous to Cronbach's alpha, called the separation index. To do so, it is necessary to begin with a decomposition of an IRT estimate into a true location and error, analogous to decomposition of an observed score into a true score and error in CTT. Let
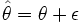
where θ is the true location, and ε is the error association with an estimate. Then SE(θ) is an estimate of the standard deviation of ε for person with a given weighted score and the separation index is obtained as follows
![R_\theta=\frac{\mbox{var}[\theta]}{\mbox{var}[\hat{\theta}]}=\frac{\mbox{var}[\hat{\theta}]-\mbox{var}[\epsilon]}{\mbox{var}[\hat{\theta}]}](http://upload.wikimedia.org/math/a/a/9/aa909529ffadf75f3de0b3ec65de037a.png)
where the mean squared standard error of person estimate gives an estimate of the variance of the errors, εn, across persons. The standard errors are normally produced as a by-product of the estimation process (see, for example, Rasch model estimation). The separation index is typically very close in value to Cronbach's alpha.[19]
[edit] See also
- Psychometrics
- Differential item functioning
- Person-fit analysis
- Standardized test
- Classical test theory
- Rasch model
- Scale (social sciences)
[edit] References
- ^ Hambleton, R. K., Swaminathan, H., & Rogers, H. J. (1991). Fundamentals of Item Response Theory. Newbury Park, CA: Sage Press.
- ^ ETS Research Overview[1]
- ^ Bock R.D., Aitkin M. (1981). Marginal maximum likelihood estimation of item parameters: application of an EM algorithm. Psychometrika, 46, 443-459.
- ^ Lazarsfeld P.F, & Henry N.W. (1968). Latent Structure Analysis. Boston: Houghton Mifflin.
- ^ Thissen, D. & Orlando, M. (2001). Item response theory for items scored in two categories. In D. Thissen & Wainer, H. (Eds.), Test Scoring (pp. 73-140). Mahwah, NJ: Lawrence Erlbaum Associates, Inc.
- ^ Joreskog K.G., Sorbom, D. (1988). PRELIS 1 user's manual, version 1. Chicago: Scientific Software, Inc.
- ^ Abramowitz M., Stegun I.A. (1972). Handbook of Mathematical Functions. Washington DC: U. S. Government Printing Office.
- ^ Uebersax, J.S. (1999). Probit latent class analysis with dichotomous or ordered category measures: conditional independence/dependence models. Applied Psychological Measurement, 23, 4, 283-297.
- ^ Andrich, D (1989), Distinctions between assumptions and requirements in measurement in the Social sciences", in Keats, J.A, Taft, R., Heath, R.A, Lovibond, S (Eds), Mathematical and Theoretical Systems, Elsevier Science Publishers, North Holland, Amsterdam, pp.7-16.
- ^ Rasch, G. (1960/1980). Probabilistic models for some intelligence and attainment tests. (Copenhagen, Danish Institute for Educational Research), expanded edition (1980) with foreword and afterword by B.D. Wright. Chicago: The University of Chicago Press.
- ^ Andrich, D. (2004). Controversy and the Rasch model: a characteristic of incompatible paradigms? Medical Care, 42, 1-16.
- ^ Rasch, G. (1960/1980). Probabilistic models for some intelligence and attainment tests. (Copenhagen, Danish Institute for Educational Research), expanded edition (1980) with foreword and afterword by B.D. Wright. Chicago: The University of Chicago Press.
- ^ Wright, B.D. (1992). IRT in the 1990s: Which Models Work Best? Rasch measurement transactions, 6:1, 196-200.
- ^ Smith, R.M. (1990). Theory and practice of fit. Rasch Measurement Transactions, 3(4), p.78. http://rasch.org/rmt/rmt34b.htm
- ^ Fischer, G.H. & Molenaar, I.W. (1995). Rasch Models: Foundations, Recent Developments, and Applications. New York: Springer.
- ^ Rasch, G. (1977). On Specific Objectivity: An attempt at formalizing the request for generality and validity of scientific statements. The Danish Yearbook of Philosophy, 14, 58-93.
- ^ Hall, L.A., & McDonald, J.L. (2000). Measuring Change in Teachers' Perceptions of the Impact that Staff Development Has on Teaching. Paper presented at the Annual Meeting of the American Educational Research Association (New Orleans, LA, April 24-28, 2000).[2]
- ^ Lord, F.M. (1980). Applications of item response theory to practical testing problems. Mahwah, NJ: Lawrence Erlbaum Associates, Inc.
- ^ Andrich, D. (1982). An index of person separation in latent trait theory, the traditional KR.20 index, and the Guttman scale response pattern. Education Research and Perspectives, 9, 95-104.
[edit] Additional reading
Many books have been written that address item response theory or contain IRT or IRT-like models. This is a partial list, focusing on texts that provide more depth.
- Lord, F.M. (1980). Applications of item response theory to practical testing problems. Mahwah, NJ: Erlbaum.
This book summaries much of Lord's IRT work, including chapters on the relationship between IRT and classical methods, fundamentals of IRT, estimation, and several advanced topics. Its estimation chapter is now dated in that it primarily discusses joint maximum likelihood method rather than the marginal maximum likelihood method implemented by Darrell Bock and his colleagues.
- Embretson, S. and Reise, S. (2000). Item response theory for psychologists. Mahwah, NJ: Erlbaum.
This book is an accessible introduction to IRT, aimed, as the title says, at psychologists.
- Baker, Frank (2001). The Basics of Item Response Theory. ERIC Clearinghouse on Assessment and Evaluation, University of Maryland, College Park, MD.
This introductory book is by one of the pioneers in the field, and is available online at [3]
- Van der Linden, W.J. & Hambleton, R.K. (Eds.) (1997). Handbook of modern item response theory. New York: Springer.
This book provides a comprehensive overview regarding various popular IRT models. It is well suited for persons who already have gained basic understanding of IRT.
- De Boeck, P., & Wilson, M. (Eds.) (2004). Explanatory Item Response Models. A Generalized Linear and Nonlinear Approach. New York: Springer.
This volume shows an integrated introduction to item response models, mainly aimed at practitioners, researchers and graduate students.
[edit] External links
- Psychometric Software Downloads
- IRT Tutorial
- An introduction to IRT
- The Standards for Educational and Psychological Testing
- IRT Command Language (ICL) computer program
- IRT Programs from SSI, Inc.
- IRT Programs from Assessment Systems Corporation
- IRT Programs from Winsteps
- Latent Trait Analysis and IRT Models
- Rasch analysis
- Free IRT software

