Radix sort
From Wikipedia, the free encyclopedia
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | O(kN) |
| Worst case space complexity | O(kN) |
| Optimal | exactly correct |
In computer science, radix sort is a sorting algorithm that sorts integers by processing individual digits. Because integers can represent strings of characters (e.g., names or dates) and specially formatted floating point numbers, radix sort is not limited to integers. Radix sort dates back as far as 1887 to the work of Herman Hollerith on tabulating machines.[1]
Most digital computers internally represent all of their data as electronic representations of binary numbers, so processing the digits of integer representations by groups of binary digit representations is most convenient. Two classifications of radix sorts are least significant digit (LSD) radix sorts and most significant digit (MSD) radix sorts. LSD radix sorts process the integer representations starting from the least significant digit and move towards the most significant digit. MSD radix sorts work the other way around.
The integer representations that are processed by sorting algorithms are often called "keys," which can exist all by themselves or be associated with other data. LSD radix sorts typically use the following sorting order: short keys come before longer keys, and keys of the same length are sorted lexicographically. This coincides with the normal order of integer representations, such as the sequence 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. MSD radix sorts use lexicographic order, which is suitable for sorting strings, such as words, or fixed-length integer representations. A sequence such as "b, c, d, e, f, g, h, i, j, ba" would be lexicographically sorted as "b, ba, c, d, e, f, g, h, i, j". If lexicographic ordering is used to sort variable-length integer representations, then the representations of the numbers from 1 to 10 would be output as 1, 10, 2, 3, 4, 5, 6, 7, 8, 9, as if the shorter keys were left-justified and padded on the right with blank characters to make the shorter keys as long as the longest key for the purpose of determining sorted order.
Contents |
[edit] Unstable implementations of in-place sorting
Radix Sort is adapted to fixed-length keys, which means that much practical data would need to be adjusted. A crude implementation would "temp = key, index(key) = key, and then key = temp, then repeat for number of keys". A bug in that implementation is that it only works on data where no key is already in place. It's written here only to illustrate that implementations benefit from using long fields, sixteen bits (64k) being a good compromise between the size and the number of programs that typically run at one time on a computer. That method will also fail if it transposes values. floating point numbers would be sorted first by their mantissa, coalesced, and then sorted by their exponent. Variable length keys are padded with terminal zero digits to make all of the keys a fixed length, which requires processing time proportional to the number of keys.
[edit] Least significant digit radix sorts
A least significant digit (LSD) radix sort is a fast stable sorting algorithm which can be used to sort keys in lexicographic order. Keys may be a string of characters, or numerical digits in a given 'radix'. The processing of the keys begins at the least significant digit (i.e., the rightmost digit), and proceeds to the most significant digit (i.e., the leftmost digit). The sequence in which digits are processed by a least significant digit (LSD) radix sort is the opposite of the sequence in which digits are processed by a most significant digit (MSD) radix sort.
A least significant digit (LSD) radix sort operates in O(nk) time, where n is the number of keys, and k is the average key length. You can get this performance for variable-length keys by grouping all of the keys that have the same length together and separately performing an LSD radix sort on each group of keys for each length, from shortest to longest, in order to avoid processing the whole list of keys on every sorting pass.
A radix sorting algorithm was originally used to sort punched cards in several passes. A computer algorithm was invented for radix sort in 1954 at MIT by Harold H. Seward. In many large applications needing speed, the computer radix sort is an improvement on (slower) comparison sorts.
LSD radix sorts have resurfaced as an alternative to other high performance comparison-based sorting algorithms (like heapsort and mergesort) that require Ω(n · log n) comparisons, where n is the number of items to be sorted. Comparison sorts can do no better than Ω(n · log n) execution time but offer the flexibility of being able to sort with respect to more complicated orderings than a lexicographic one; however, this ability is of little importance in many practical applications.
Each key is first figuratively dropped into one level of buckets corresponding to the value of the rightmost digit. Each bucket preserves the original order of the keys as the keys are dropped into. There is a one-to-one correspondence between the number of buckets and the number of values that can be represented by a digit. Then, the process repeats with the next neighbouring digit until there are no more digits to process. In other words:
- Take the least significant digit (or group of bits, both being examples of radices) of each key.
- Group the keys based on that digit, but otherwise keep the original order of keys. (This is what makes the LSD radix sort a stable sort).
- Repeat the grouping process with each more significant digit.
The sort in step 2 is usually done using bucket sort or counting sort, which are efficient in this case since there are usually only a small number of digits.
[edit] An example
- Original, unsorted list:
170, 45, 75, 90, 2, 24, 802, 66
- Sorting by least significant digit (1s place) gives:
170, 90, 2, 802, 24, 45, 75, 66
Notice that we keep 2 before 802, because 2 occurred before 802 in the original list, and similarly for pairs 170 & 90 and 45 & 75.
- Sorting by next digit (10s place) gives:
2, 802, 24, 45, 66, 170, 75, 90
- Sorting by most significant digit (100s place) gives:
2, 24, 45, 66, 75, 90, 170, 802
It is important to realize that each of the above steps requires just a single pass over the data, since each item can be placed in its correct bucket without having to be compared with other items.
Some LSD radix sort implementations allocate space for buckets by first counting the number of keys that belong in each bucket before moving keys into those buckets. The number of times that each digit occurs is stored in an array. Consider the previous list of keys viewed in a different way:
- 170, 045, 075, 090, 002, 024, 802, 066
The first counting pass starts on the least significant digit of each key, producing an array of bucket sizes:
- 2 (bucket size for digits of 0: 170, 090)
- 2 (bucket size for digits of 2: 002, 802)
- 1 (bucket size for digits of 4: 024)
- 2 (bucket size for digits of 5: 045, 075)
- 1 (bucket size for digits of 6: 066)
A second counting pass on the next more significant digit of each key will produce an array of bucket sizes:
- 2 (bucket size for digits of 0: 002, 802)
- 1 (bucket size for digits of 2: 024)
- 1 (bucket size for digits of 4: 045)
- 1 (bucket size for digits of 6: 066)
- 2 (bucket size for digits of 7: 170, 075)
- 1 (bucket size for digits of 9: 090)
A third and final counting pass on the most significant digit of each key will produce an array of bucket sizes:
- 6 (bucket size for digits of 0: 002, 024, 045, 066, 075, 090)
- 1 (bucket size for digits of 1: 170)
- 1 (bucket size for digits of 8: 802)
At least one LSD radix sort implementation now counts the number of times that each digit occurs in each column for all columns in a single counting pass. (See the external links section.) Other LSD radix sort implementations allocate space for buckets dynamically as the space is needed.
[edit] Iterative version using queues
A simple version of an LSD radix sort can be achieved using queues as buckets. The following process is repeated for a number of times equal to the length of the longest key:
- The integers are enqueued into an array of ten separate queues based on their digits from right to left. Computers often represent integers internally as fixed-length binary digits. Here, we will do something analogous with fixed-length decimal digits. So, using the numbers from the previous example, the queues for the 1st pass would be:
- 0: 170, 090
- 1: none
- 2: 002, 802
- 3: none
- 4: 024
- 5: 045, 075
- 6: 066
- 7 - 9: none
- The queues are dequeued back into an array of integers, in increasing order. Using the same numbers, the array will look like this after the 1st pass:
- 170, 090, 002, 802, 024, 045, 075, 066
- For the second pass:
- Queues:
- 0: 002, 802
- 1: none
- 2: 024
- 3: none
- 4: 045
- 5: none
- 6: 066
- 7: 170, 075
- 8: none
- 9: 090
- Array:
- 002, 802, 024, 045, 066, 170, 075, 090
(note that at this point only 802 and 170 are out of order)
- 002, 802, 024, 045, 066, 170, 075, 090
- Queues:
- For the third pass:
- Queues:
- 0: 002, 024, 045, 066, 075, 090
- 1: 170
- 2 - 7: none
- 8: 802
- 9: none
- Array:
- 002, 024, 045, 066, 075, 090, 170, 802 (sorted)
- Queues:
While this may not be the most efficient radix sort algorithm, it is relatively simple, and still quite efficient.
[edit] Most significant digit radix sorts
A most significant digit (MSD) radix sort can be used to sort keys in lexicographic order. Unlike a least significant digit (LSD) radix sort, a most significant digit radix sort does not necessarily preserve the original order of duplicate keys. A MSD radix sort starts processing the keys from the most significant digit, leftmost digit, to the least significant digit, rightmost digit. This sequence is opposite that of least significant digit (LSD) radix sorts. An MSD radix sort stops rearranging the position of a key when the processing reaches a unique prefix of the key. Some MSD radix sorts use one level of buckets in which to group the keys. See the counting sort and pigeonhole sort articles. Other MSD radix sorts use multiple levels of buckets, which form a trie or a path in a trie. A postman's sort / postal sort is a kind of MSD radix sort.
[edit] Recursion
A recursively subdividing MSD radix sort algorithm works as follows:
- Take the most significant digit of each key.
- Sort the list of elements based on that digit, grouping elements with the same digit into one bucket.
- Recursively sort each bucket, starting with the next digit to the right.
- Concatenate the buckets together in order.
Implementation
A two pass method can be used to first find out how big each bucket needs to be and then place each key (or pointer to the key) into the appropriate bucket. A single pass system can also be used, where each bucket is dynamically allocated and resized as needed, but this runs the risk of serious memory fragmentation, discontiguous allocations of memory, which may degrade performance. This memory fragmentation could be avoided if a fixed allocation of buckets is used for all possible values of a digit, but, for an 8 bit digit, this would require 256 (28) buckets, even if not all of the buckets were used. So, this approach might use up all available memory quickly and go into paging space, where data is stored and accessed on a hard drive or some other secondary memory device instead of main memory, which would radically degrade performance. A fixed allocation approach would only make sense if each digit was very small, such as a single bit.
Application to parallel computing
Note that this recursive sorting algorithm has particular application to parallel computing, as each of the subdivisions can be sorted independently of the rest. In this case, each recursion is passed to the next available processor. A single processor would be used at the start (the most significant digit). Then, by the second or third digit, all available processors would likely be engaged. Ideally, as each subdivision is fully sorted, fewer and fewer processors would be utilized. In the worst case, all of the keys will be identical or nearly identical to each other, with the result that there will be little to no advantage to using parallel computing to sort the keys.
[edit] A recursive forward radix sort example
Sort the list:
170, 045, 075, 090, 002, 024, 802, 066
- Sorting by most significant digit (100s place) gives:
Zero hundreds bucket: 045, 075, 090, 002, 024, 066
One hundreds bucket: 170
Eight hundreds bucket: 802 - Sorting by next digit (10s place) is only needed for those numbers in the zero hundreds bucket (no other buckets contain more than one item):
Zero tens bucket: 002
Twenties bucket: 024
Forties bucket: 045
Sixties bucket: 066
Seventies bucket: 075
Nineties bucket: 090 - Sorting by least significant digit (1s place) is not needed, as there is no tens bucket with more than one number. Therefore, the now sorted zero hundreds bucket is concatenated, joined in sequence, with the one hundreds bucket and eight hundreds bucket to give:
002, 024, 045, 066, 075, 090, 170, 802
This example used base ten digits for the sake of readability, but of course binary digits or perhaps bytes might make more sense for a binary computer to process.
[edit] Efficiency
Radix sort is optimal. Assume that every sort must look at all keys in order to sort them. Therefore, optimal in this context means that time needed to sort keys (integers) grows in proportion to the number of keys. Further, assume that storage needed to sort keys must grow at a minimum of a constant times the number of keys to sort. Radix sort does both. It has a linear growth function in relation to both storage required and amount of time needed to sort keys. Detecting that data is already sorted requires nothing but sixty-four bits of date information concerning last sort. Linear growth cannot be beaten in sorting methods.[2]
[edit] Incremental trie-based radix sort
Another way to proceed with an MSD radix sort is to use more memory to create a trie to represent the keys and then traverse the trie to visit each key in order. A depth-first traversal of a trie starting from the root node will visit each key in order. A depth-first traversal of a trie, or any other kind of acyclic tree structure, is equivalent to traversing a maze via the right-hand rule.
A trie essentially represents a set of strings or numbers, and a radix sort which uses a trie structure is not necessarily stable, which means that the original order of duplicate keys is not necessarily preserved, because a set does not contain duplicate elements. Additional information will have to be associated with each key to indicate the population count or original order of any duplicate keys in a trie-based radix sort if keeping track of that information is important for a particular application. It may even be desirable to discard any duplicate strings as the trie creation proceeds if the goal is to find only unique strings in sorted order. Some people sort a list of strings first and then make a separate pass through the sorted list to discard duplicate strings, which can be slower than using a trie to simultaneously sort and discard duplicate strings in one pass.
One of the advantages of maintaining the trie structure is that the trie makes it possible to determine quickly if a particular key is a member of the set of keys in a time that is proportional to the length of the key, k, in O(k) time, that is independent of the total number of keys. Determining set membership in a plain list, as opposed to determining set membership in a trie, requires binary search, O(k*log(n)) time; linear search, O(kn) time; or some other method whose execution time is in some way dependent on the total number, n, of all of the keys in the worst case. It is sometimes possible to determine set membership in a plain list in O(k) time, in a time that is independent of the total number of keys, such as when the list is known to be in an arithmetic sequence or some other computable sequence.
Maintaining the trie structure also makes it possible to insert new keys into the set incrementally or delete keys from the set incrementally while maintaining sorted order in O(k) time, in a time that is independent of the total number of keys. In contrast, other radix sorting algorithms must, in the worst case, re-sort the entire list of keys each time that a new key is added or deleted from an existing list, requiring O(kn) time.
[edit] Snow White analogy
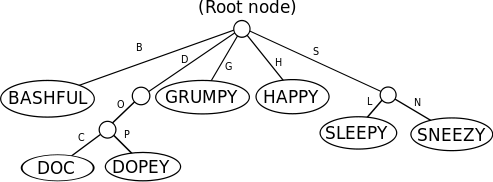
If the nodes were rooms connected by hallways, then here is how Snow White might proceed to visit all of the dwarfs if the place were dark, keeping her right hand on a wall at all times:
- She travels down hall B to find Bashful.
- She continues moving forward with her right hand on the wall, which takes her around the room and back up hall B.
- She moves down halls D, O, and C to find Doc.
- Continuing to follow the wall with her right hand, she goes back up hall C, then down hall P, where she finds Dopey.
- She continues back up halls P, O, D, and then goes down hall G to find Grumpy.
- She goes back up hall G, with her right hand still on the wall, and goes down hall H to the room where Happy is.
- She travels back up hall H and turns right down halls S and L, where she finds Sleepy.
- She goes back up hall L, down hall N, where she finally finds Sneezy.
- She travels back up halls N and S to her starting point and knows that she is done.
These series of steps serve to illustrate the path taken in the trie by Snow White via a depth-first traversal to visit the dwarfs by the ascending order of their names, Bashful, Doc, Dopey, Grumpy, Happy, Sleepy, and Sneezy. The algorithm for performing some operation on the data associated with each node of a tree first, such as printing the data, and then moving deeper into the tree is called a pre-order traversal, which is a kind of depth-first traversal. A pre-order traversal is used to process the contents of a trie in ascending order. If Snow White wanted to visit the dwarfs by the descending order of their names, then she could walk backwards while following the wall with her right hand, or, alternatively, walk forward while following the wall with her left hand. The algorithm for moving deeper into a tree first until no further descent to unvisited nodes is possible and then performing some operation on the data associated with each node is called post-order traversal, which is another kind of depth-first traversal. A post-order traversal is used to process the contents of a trie in descending order.
The root node of the trie in the diagram essentially represents a null string, an empty string, which can be useful for keeping track of the number of blank lines in a list of words. The null string can be associated with a circularly linked list with the null string initially as its only member, with the forward and backward pointers both initially pointing to the null string. The circularly linked list can then be expanded as each new key is inserted into the trie. The circularly linked list is represented in the following diagram as thick, grey, horizontally linked lines:
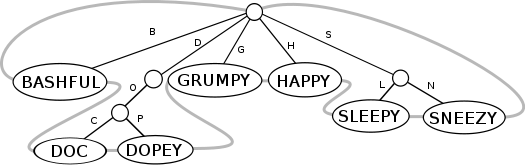
If a new key, other than the null string, is inserted into a leaf node of the trie, then the computer can go to the last preceding node where there was a key or a bifurcation to perform a depth-first search to find the lexicographic successor or predecessor of the inserted key for the purpose of splicing the new key into the circularly linked list. The last preceding node where there was a key or a bifurcation, a fork in the path, is a parent node in the type of trie shown here, where only unique string prefixes are represented as paths in the trie. If there is already a key associated with the parent node that would have been visited during a movement away from the root during a right-hand, forward-moving, depth first traversal, then that immediately ends the depth-first search, as that key is the predecessor of the inserted key. For example, if Bashful is inserted into the trie, then the predecessor is the null string in the parent node, which is the root node in this case. In other words, if the key that is being inserted is on the leftmost branch of the parent node, then any string contained in the parent node is the lexicographic predecessor of the key that is being inserted, else the lexicographic predecessor of the key that is being inserted exists down the parent node's branch that is immediately to the left of the branch where the new key is being inserted. For example, if Grumpy were the last key inserted into the trie, then the computer would have a choice of trying to find either the predecessor, Dopey, or the successor, Happy, with a depth-first search starting from the parent node of Grumpy. With no additional information to indicate which path is longer, the computer might traverse the longer path, D, O, P. If Dopey were the last key inserted into the trie, then the depth-first search starting from the parent node of Dopey would soon find the predecessor, Doc, because that would be the only choice.
If a new key is inserted into an internal node, then a depth-first search can be started from the internal node to find the lexicographic successor. For example, if the literal string, "DO", were inserted in the node at the end of the path D, O, then a depth-first search could be started from that internal node to find the successor, "DOC", for the purpose of splicing the new string into the circularly linked list.
Forming the circularly linked list requires more memory but allows the keys to be visited more directly in either ascending or descending order via a linear traversal of the linked list rather than a depth-first traversal of the entire trie. This concept of a circularly linked trie structure is similar to the concept of a threaded binary tree. Let's call this structure a circularly threaded trie.

When a trie is used to sort numbers, the number representations must all be the same length unless you are willing to perform a breadth-first traversal. When the number representations will be visited via depth-first traversal, as in the above diagram, the number representations will always be on the leaf nodes of the trie. Note how similar in concept this particular example of a trie is to the recursive forward radix sort example which involves the use of buckets instead of a trie. Performing a radix sort with the buckets is like creating a trie and then discarding the non-leaf nodes.
[edit] See also
[edit] External links
| The Wikibook Algorithm implementation has a page on the topic of |
- Demonstration and comparison of Radix sort with Bubble sort, Merge sort and Quicksort implemented in JavaScript
- Article about Radix sorting IEEE floating-point numbers with implementation.
- Faster Floating Point Sorting and Multiple Histogramming with implementation in C++
- Pointers to radix sort visualizations
[edit] References
- ^ US patent 395781 and UK patent 327
- ^ Sara Baase (1988-07-01). Computer Algorithms, Introduction to Design and Analysis, Second Edition. Addison-Wesley. pp. 85–89. ISBN 0-201-06035-3. "It is startling that if the keys are distributed into buckets first according to their least significant digits (or bits, letters, or fields), then the buckets can be coalesced in order before distributing on the next digit."
- Donald Knuth. The Art of Computer Programming, Volume 3: Sorting and Searching, Third Edition. Addison-Wesley, 1997. ISBN 0-201-89685-0. Section 5.2.5: Sorting by Distribution, pp.168–179.
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Section 8.3: Radix sort, pp.170–173.
- BRADSORT v1.50 source code
- Efficient Trie-Based Sorting of Large Sets of Strings, by Ranjan Sinha and Justin Zobel. This paper describes a method of creating tries of buckets which figuratively burst into sub-tries when the buckets hold more than a predetermined capacity of strings, hence the name, "Burstsort."
|
||||||||||||||||||||||||||||