Human genome
From Wikipedia, the free encyclopedia
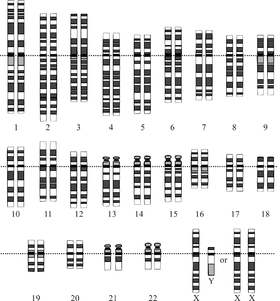
The human genome is the genome of Homo sapiens, which is stored on 23 chromosome pairs. Twenty-two of these are autosomal chromosome pairs, while the remaining pair is sex-determining. The haploid human genome occupies a total of just over 3 billion DNA base pairs. The Human Genome Project produced a reference sequence of the euchromatic human genome, which is used worldwide in biomedical sciences.
The haploid human genome contains an estimated 20,000–25,000 protein-coding genes, far fewer than had been expected before its sequencing.[1] In fact, only about 1.5% of the genome codes for proteins, while the rest consists of RNA genes, regulatory sequences, introns and (controversially) "junk" DNA.[2]
Contents |
[edit] Features
[edit] Genes
There are estimated 20,000–25,000 human protein-coding genes.[1]. The estimate of the number of human genes has been repeatedly revised down from initial predictions of 100,000 or more as genome sequence quality and gene finding methods have improved, and could continue to drop further.[3]
Surprisingly, the number of human genes seems to be less than a factor of two greater than that of many much simpler organisms, such as the roundworm and the fruit fly. However, human cells make extensive use of alternative splicing to produce several different proteins from a single gene, and the human proteome is thought to be much larger than those of the aforementioned organisms. Besides, most human genes have multiple exons, and human introns are frequently much longer than the flanking exons.
Human genes are distributed unevenly across the chromosomes. Each chromosome contains various gene-rich and gene-poor regions, which seem to be correlated with chromosome bands and GC-content. The significance of these nonrandom patterns of gene density is not well understood. In addition to protein coding genes, the human genome contains thousands of RNA genes, including tRNA, ribosomal RNA, microRNA, and other non-coding RNA genes.
[edit] Regulatory sequences
The human genome has many different regulatory sequences which are crucial to controlling gene expression. These are typically short sequences that appear near or within genes. A systematic understanding of these regulatory sequences and how they together act as a gene regulatory network is only beginning to emerge from computational, high-throughput expression and comparative genomics studies.
| This section may require cleanup to meet Wikipedia's quality standards. |
Identification of regulatory sequences relies in part on evolutionary conservation. The evolutionary branch between the human and mouse, for example, occurred 70–90 million years ago.[4] So computer comparisons of gene sequences that identify conserved non-coding sequences will be an indication of their importance in duties such as gene regulation.[5]
Another comparative genomic approach to locating regulatory sequences in humans is the gene sequencing of the puffer fish. These vertebrates have essentially the same genes and regulatory gene sequences as humans, but with only one-eighth the "junk" DNA. The compact DNA sequence of the puffer fish makes it much easier to locate the regulatory genes.[6]
[edit] Other DNA
Protein-coding sequences (specifically, coding exons) comprise less than 1.5% of the human genome.[2] Aside from genes and known regulatory sequences, the human genome contains vast regions of DNA the function of which, if any, remains unknown. These regions in fact comprise the vast majority, by some estimates 97%, of the human genome size. Much of this is composed of:
[edit] Repeat elements
[edit] Transposons
[edit] Pseudogenes
However, there is also a large amount of sequence that does not fall under any known classification.
Much of this sequence may be an evolutionary artifact that serves no present-day purpose, and these regions are sometimes collectively referred to as "junk" DNA. There are, however, a variety of emerging indications that many sequences within are likely to function in ways that are not fully understood. Recent experiments using microarrays have revealed that a substantial fraction of non-genic DNA is in fact transcribed into RNA,[7] which leads to the possibility that the resulting transcripts may have some unknown function. Also, the evolutionary conservation across the mammalian genomes of much more sequence than can be explained by protein-coding regions indicates that many, and perhaps most, functional elements in the genome remain unknown.[8] The investigation of the vast quantity of sequence information in the human genome whose function remains unknown is currently a major avenue of scientific inquiry.[9]
[edit] Sequencing
DNA sequencing determines the order of the nucleotide bases in a genome.
[edit] Composite
The Human Genome Project and a parallel project by Celera Genomics each produced and published a haploid human genome sequence, both of which were a composite of the DNA sequence of several individuals.[10]
[edit] Personal
A personal genome sequence is a complete sequencing of the chemical base pairs that make up the DNA of a single person. Because medical treatments have different effects on different people because of genetic variations such as single-nucleotide polymorphisms (SNPs), the analysis of personal genomes may lead to personalized medical treatment based on individual genotypes.[citation needed]
The completion of the fifth such map was announced in December 2008. The genome mapped was that of a Korean researcher Seong-Jin Kim. Genome maps had previously been completed for Craig Venter of the U.S. in 2007, James Watson of the U.S. in April 2008, and Yang Huanming of China in November 2008 and Dan Stoicescu.[11][12][13]
Personal genomes had not been sequenced in the Human Genome Project (HGP) to protect the identity of volunteers who provided DNA samples. That sequence was derived from the DNA of several volunteers from a diverse population.[14] Another distinction is that the HGP sequence is haploid, however, the sequence maps for Venter and Watson for example are diploid, representing both sets of chromosomes.
Kim’s genome had 1.58 million SNPs that had never been reported before and indicates that six out of 10,000 DNA bases are unique to Koreans. Kim's sequence map can be used to assist in building a standard Korean genome, which can then be used to compare the genomes of other Korean individuals for personalized medical treatments.
[edit] Mapping
Whereas a genome sequence lists the order of every DNA base in a genome, a genome map identifies the landmarks. A genome map is less detailed than a genome sequence and aids in navigating around the genome.[15][16]
[edit] Variation
An example of a variation map is the HapMap being developed by the International HapMap Project. The HapMap is a haplotype map of the human genome, "which will describe the common patterns of human DNA sequence variation."[17] It catalogs the patterns of small-scale variations in the genome that involve single DNA letters, or bases.
Researchers published the first sequence-based map of large-scale structural variation across the human genome in the journal Nature in May 2008.[18][19] Large-scale structural variations are differences in the genome among people that range from a few thousand to a few million DNA bases; some are gains or losses of stretches of genome sequence and others appear as re-arrangements of stretches of sequence. These variations include differences in the number of copies individuals have of a particular gene.
[edit] Variation
Most studies of human genetic variation have focused on single nucleotide polymorphisms (SNPs), which are substitutions in individual bases along a chromosome. Most analyses estimate that SNPs occur on average somewhere between every 1 in 100 and 1 in 1,000 base pairs in the euchromatic human genome, although they do not occur at a uniform density. Thus follows the popular statement that "we are all, regardless of race, genetically 99.9% the same",[20] although this would be somewhat qualified by most geneticists. For example, a much larger fraction of the genome is now thought to be involved in copy number variation.[21] A large-scale collaborative effort to catalog SNP variations in the human genome is being undertaken by the International HapMap Project.
The genomic loci and length of certain types of small repetitive sequences are highly variable from person to person, which is the basis of DNA fingerprinting and DNA paternity testing technologies. The heterochromatic portions of the human genome, which total several hundred million base pairs, are also thought to be quite variable within the human population (they are so repetitive and so long that they cannot be accurately sequenced with current technology). These regions contain few genes, and it is unclear whether any significant phenotypic effect results from typical variation in repeats or heterochromatin.
Most gross genomic mutations in Gamete germ cells probably result in inviable embryos; however, a number of human diseases are related to large-scale genomic abnormalities. Down syndrome, Turner Syndrome, and a number of other diseases result from nondisjunction of entire chromosomes. Cancer cells frequently have aneuploidy of chromosomes and chromosome arms, although a cause and effect relationship between aneuploidy and cancer has not been established.
[edit] Genetic disorders
|
|
This article is in need of attention from an expert on the subject. WikiProject Medicine or the Medicine Portal may be able to help recruit one. (April 2008) |
Most aspects of human biology involve both genetic (inherited) and non-genetic (environmental) factors. Some inherited variation influences aspects of our biology that are not medical in nature (height, eye color, ability to taste or smell certain compounds, etc). Moreover, some genetic disorders only cause disease in combination with the appropriate environmental factors (such as diet). With these caveats, genetic disorders may be described as clinically defined diseases caused by genomic DNA sequence variation. In the most straightforward cases, the disorder can be associated with variation in a single gene. For example, cystic fibrosis is caused by mutations in the CFTR gene, and is the most common recessive disorder in caucasian populations with over 1300 different mutations known. Disease-causing mutations in specific genes are usually severe in terms of gene function, and are fortunately rare, thus genetic disorders are similarly individually rare. However, since there are many genes that can vary to cause genetic disorders, in aggregate they comprise a significant component of known medical conditions, especially in pediatric medicine. Molecularly characterized genetic disorders are those for which the underlying causal gene has been identified, currently there are approximately 2200 such disorders annotated in the OMIM database,.[22]
Studies of genetic disorders are often performed by means of family-based studies. In some instances population based approaches are employed, particularly in the case of so-called founder populations such as those in Finland, French-Canada, Utah, Sardinia, etc. Diagnosis and treatment of genetic disorders are usually performed by a geneticist-physician trained in clinical/medical genetics. The results of the Human Genome Project are likely to provide increased availability of genetic testing for gene-related disorders, and eventually improved treatment. Parents can be screened for hereditary conditions and counselled on the consequences, the probability it will be inherited, and how to avoid or ameliorate it in their offspring.
As noted above, there are many different kinds of DNA sequence variation, ranging from complete extra or missing chromosomes down to single nucleotide changes. It is generally presumed that much naturally occurring genetic variation in human populations is phenotypically neutral, i.e. has little or no detectable effect on the physiology of the individual (although there may be fractional differences in fitness defined over evolutionary time frames). Genetic disorders can be caused by any or all known types of sequence variation. To molecularly characterize a new genetic disorder, it is necessary to establish a causal link between a particular genomic sequence variant and the clinical disease under investigation. Such studies constitute the realm of human molecular genetics.
With the advent of the Human Genome and International HapMap Project, it has become feasible to explore subtle genetic influences on many common disease conditions such as diabetes, asthma, migraine, schizophrenia, etc. Although some causal links have been made between genomic sequence variants in particular genes and some of these diseases, often with much publicity in the general media, these are usually not considered to be genetic disorders per se as their causes are complex, involving many different genetic and environmental factors. Thus there may be disagreement in particular cases whether a specific medical condition should be termed a genetic disorder.
[edit] Evolution
Comparative genomics studies of mammalian genomes suggest that approximately 5% of the human genome has been conserved by evolution since the divergence of those species approximately 200 million years ago, containing the vast majority of genes.[8][9] Intriguingly, since genes and known regulatory sequences probably comprise less than 2% of the genome, this suggests that there may be more unknown functional sequence than known functional sequence. A smaller, yet large, fraction of human genes seem to be shared among most known vertebrates. The chimpanzee genome is 95% identical to the human genome. On average, a typical human protein-coding gene differs from its chimpanzee ortholog by only two amino acid substitutions; nearly one third of human genes have exactly the same protein translation as their chimpanzee orthologs. A major difference between the two genomes is human chromosome 2, which is equivalent to a fusion product of chimpanzee chromosomes 12 and 13.[23]
Humans have undergone an extraordinary loss of olfactory receptor genes during our recent evolution, which explains our relatively crude sense of smell compared to most other mammals. Evolutionary evidence suggests that the emergence of color vision in humans and several other primate species has diminished the need for the sense of smell.[24]
[edit] Mitochondrial genome
The human mitochondrial genome, while usually not included when referring to the "human genome", is of tremendous interest to geneticists, since it undoubtedly plays a role in mitochondrial disease. It also sheds light on human evolution; for example, analysis of variation in the human mitochondrial genome has led to the postulation of a recent common ancestor for all humans on the maternal line of descent. (see Mitochondrial Eve)
Due to the lack of a system for checking for copying errors, Mitochondrial DNA (mtDNA) has a more rapid rate of variation than nuclear DNA. This 20-fold increase in the mutation rate allows mtDNA to be used for more accurate tracing of maternal ancestry. Studies of mtDNA in populations have allowed ancient migration paths to be traced, such as the migration of Native Americans from Siberia or Polynesians from southeastern Asia. It has also been used to show that there is no trace of Neanderthal DNA in the European gene mixture inherited through purely maternal lineage.[25]
[edit] Epigenome
| This section requires expansion. |
A variety of features of the human genome that transcend its primary DNA sequence, such as chromatin packaging, histone modifications and DNA methylation, are important in regulating gene expression, genome replication and other cellular processes.[26][27] These "epigenetic" features are thought to be involved in cancer and other abnormalities, and some may be heritable across generations.
[edit] See also
[edit] References
- ^ a b International Human Genome Sequencing Consortium (2004). "Finishing the euchromatic sequence of the human genome.". Nature 431 (7011): 931–45. doi:. PMID 15496913. [1]
- ^ a b International Human Genome Sequencing Consortium (2001). "Initial sequencing and analysis of the human genome.". Nature 409 (6822): 860–921. doi:. PMID 11237011. [2]
- ^ Science 316 p 1113 25-May-2007, probably in the range 20,488-20,588. (note, this is a news article in Science magazine reporting on a conference presentation. It is not a peer-reviewed publication, and therefore its figures should not be considered "authoritative")
- ^ Nei M, Xu P, Glazko G (2001). "Estimation of divergence times from multiprotein sequences for a few mammalian species and several distantly related organisms.". Proc Natl Acad Sci U S A 98 (5): 2497–502. doi:. PMID 11226267. http://www.pnas.org/cgi/content/full/051611498.
- ^ Loots G, Locksley R, Blankespoor C, Wang Z, Miller W, Rubin E, Frazer K (2000). "Identification of a coordinate regulator of interleukins 4, 13, and 5 by cross-species sequence comparisons.". Science 288 (5463): 136–40. doi:. PMID 10753117. Summary
- ^ Meunier, Monique. "Genoscope and Whitehead announce a high sequence coverage of the Tetraodon nigroviridis genome". Genoscope. http://www.cns.fr/externe/English/Actualites/Presse/261001_1.html. Retrieved on 2006-09-12.
- ^ "...a tiling array with 5-nucleotide resolution that mapped transcription activity along 10 human chromosomes revealed that an average of 10% of the genome (compared to the 1 to 2% represented by bona fide exons) corresponds to polyadenylated transcripts, of which more than half do not overlap with known gene locations.Claverie J (2005). "Fewer genes, more noncoding RNA.". Science 309 (5740): 1529–30. doi:. PMID 16141064.
- ^ a b "...the proportion of small (50-100 bp) segments in the mammalian genome that is under (purifying) selection can be estimated to be about 5%. This proportion is much higher than can be explained by protein-coding sequences alone, implying that the genome contains many additional features (such as untranslated regions, regulatory elements, non-protein-coding genes, and chromosomal structural elements) under selection for biological function." Mouse Genome Sequencing Consortium (2002). "Initial sequencing and comparative analysis of the mouse genome.". Nature 420 (6915): 520–62. doi:. PMID 12466850.
- ^ a b The ENCODE Project Consortium (2007). ""Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project"". Nature 447: 799–816. doi:.
- ^ http://biology.plosjournals.org/perlserv/?request=get-document&doi=10.1371/journal.pbio.0050266&ct=1
- ^ http://english.chosun.com/w21data/html/news/200812/200812050003.html
- ^ http://rki.kbs.co.kr/english/news/news_science_detail.htm?no=3623
- ^ http://www.nytimes.com/2008/03/04/health/research/04geno.html
- ^ http://www.genome.gov/11006943
- ^ http://www.genomenewsnetwork.org/resources/whats_a_genome/Chp3_1.shtml
- ^ http://www.ncbi.nlm.nih.gov/About/primer/mapping.html
- ^ http://www.hapmap.org/abouthapmap.html
- ^ http://www.genome.gov/27026113
- ^ http://www.nature.com/nature/journal/v453/n7191/abs/nature06862.html
- ^ from Bill Clinton's 2000 State of the Union address [3]
- ^ Global variation in copy number in the human genome : Article : Nature
- ^ Online Mendelian Inheritance in Man (OMIM)[4]
- ^ "Human chromosome 2 resulted from a fusion of two ancestral chromosomes that remained separate in the chimpanzee lineage" The Chimpanzee Sequencing and Analysis Consortium (2005). "Initial sequence of the chimpanzee genome and comparison with the human genome.". Nature 437 (7055): 69–87. doi:. PMID 16136131.
"Large-scale sequencing of the chimpanzee genome is now imminent."Olson M, Varki A (2003). "Sequencing the chimpanzee genome: insights into human evolution and disease.". Nat Rev Genet 4 (1): 20–8. doi:. PMID 12509750. - ^ "Our findings suggest that the deterioration of the olfactory repertoire occurred concomitant with the acquisition of full trichromatic color vision in primates." Gilad Y, Wiebe V, Przeworski M, Lancet D, Pääbo S (2004). "Loss of olfactory receptor genes coincides with the acquisition of full trichromatic vision in primates.". PLoS Biol 2 (1): E5. doi:. PMID 14737185.
- ^ Sykes, Bryan (2003-10-09). "Mitochondrial DNA and human history". The Human Genome. http://genome.wellcome.ac.uk/doc_WTD020876.html. Retrieved on 2006-09-19.
- ^ Cell - Misteli
- ^ Cell - Bernstein et al
- Lindblad-Toh K, et al. (2005). "Genome sequence, comparative analysis and haplotype structure of the domestic dog.". Nature 438 (7069): 803–19. doi:. PMID 16341006.[5]
[edit] External links
- The National Human Genome Research Institute
- Ensembl The Ensembl Genome Browser Project
- National Library of Medicine human genome viewer
- UCSC Genome Browser.
- Human Genome Project.
- Sabancı University School of Languages Podcasts What makes us different from chimpanzees? by Andrew Berry (MP3 file)
- The National Office of Public Health Genomics
- New findings: established views about human genome challenged [6] [7] [8]
|
||||||||
|
|||||

