Matrix calculus
From Wikipedia, the free encyclopedia
In mathematics, matrix calculus is a specialized notation for doing multivariable calculus, especially over spaces of matrices, where it defines the matrix derivative. This notation is well-suited to describing systems of differential equations, and taking derivatives of matrix-valued functions with respect to matrix variables. This notation is commonly used in statistics and engineering, while the tensor index notation is preferred in physics.
Contents |
[edit] Notice
This article uses another definition for vector and matrix calculus than the form often encountered within the field of estimation theory and pattern recognition. The resulting equations will therefore appear to be transposed when compared to the equations used in textbooks within these fields.
[edit] Notation
Let M(n,m) denote the space of real n×m matrices with n rows and m columns, whose elements will be denoted F, X, Y, etc. An element of M(n,1), that is, a column vector, is denoted with a boldface lowercase letter x, while xT denotes its transpose row vector. An element of M(1,1) is a scalar, and denoted a, b, c, f, t etc. All functions are assumed to be of differentiability class C1 unless otherwise noted.
[edit] Vector calculus
Because the space M(n,1) is identified with the Euclidean space Rn and M(1,1) is identified with R, the notations developed here can accommodate the usual operations of vector calculus.
- The tangent vector to a curve x : R → Rn is
- The gradient of a scalar function f : Rn → R
- The pushforward or differential of a function f : Rm → Rn is described by the Jacobian matrix
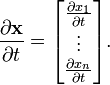

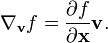
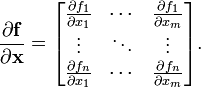
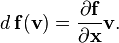
[edit] Matrix calculus
For the purposes of defining derivatives of simple functions, not much changes with matrix spaces; the space of n×m matrices is isomorphic to the vector space Rnm. The three derivatives familiar from vector calculus have close analogues here, though beware the complications that arise in the identities below.
- The tangent vector of a curve F : R → M(n,m)
- The gradient of a scalar function f : M(n,m) → R
- The differential or the matrix derivative of a function F : M(n,m) → M(p,q) is an element of M(p,q) ⊗ M(m,n), a fourth rank tensor (the reversal of m and n here indicates the dual space of M(n,m)). In short it is an m×n matrix each of whose entries is a p×q matrix.

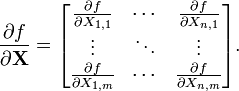

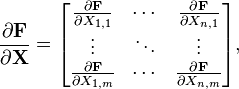

[edit] Identities
Note that matrix multiplication is not commutative, so in these identities, the order must not be changed.
- Chain rule: If Z is a function of Y which in turn is a function of X
- Product rule:

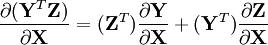
[edit] Examples
[edit] Derivative of linear functions
This section lists some commonly used vector derivative formulas for linear equations evaluating to a vector.



[edit] Derivative of quadratic functions
This section lists some commonly used vector derivative formulas for quadratic matrix equations evaluating to a scalar.

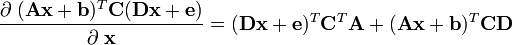
Related to this is the derivative of the Euclidean norm:

[edit] Derivative of matrix traces
This section shows examples of matrix differentiation of common trace equations.

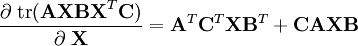
[edit] Relation to other derivatives
There are other commonly used definitions for derivatives in multivariable spaces. For topological vector spaces, the most familiar is the Fréchet derivative, which makes use of a norm. In the case of matrix spaces, there are several matrix norms available, all of which are equivalent since the space is finite-dimensional. However the matrix derivative defined in this article makes no use of any topology on M(n,m). It is defined solely in terms of partial derivatives, which are sensitive only to variations in a single dimension at a time, and thus are not bound by the full differentiable structure of the space. For example, it is possible for a map to have all partial derivatives exist at a point, and yet not be continuous in the topology of the space. See for example Hartogs' theorem. The matrix derivative is not a special case of the Fréchet derivative for matrix spaces, but rather a convenient notation for keeping track of many partial derivatives for doing calculations, though in the case that a function is Fréchet differentiable, the two derivatives will agree.
[edit] Usages
Matrix calculus is used for deriving optimal stochastic estimators, often involving the use of Lagrange multipliers. This includes the derivation of:
[edit] Alternatives
The tensor index notation with its Einstein summation convention is very similar to the matrix calculus, except one writes only a single component at a time. It has the advantage that one can easily manipulate arbitrarily high rank tensors, whereas tensors of rank higher than two are quite unwieldy with matrix notation. Note that a matrix can be considered simply a tensor of rank two.
[edit] See also
[edit] External links
- Matrix Calculus appendix from Introduction to Finite Element Methods book on University of Colorado at Boulder. Uses the Hessian (transpose to Jacobian) definition of vector and matrix derivatives.
- Matrix calculus Matrix Reference Manual , Imperial College London.
- Appendix D to Jon Dattorro, Convex Optimization & Euclidean Distance Geometry. Uses the Hessian definition.
- The Matrix Cookbook, with a derivatives chapter. Uses the Hessian definition.

