Relational database
From Wikipedia, the free encyclopedia
|
|
This article does not cite any references or sources. Please help improve this article by adding citations to reliable sources (ideally, using inline citations). Unsourced material may be challenged and removed. (October 2008) |
A relational database is a database that groups data using common attributes found in the data set. The resulting "clumps" of organized data are much easier for people to understand.
For example, a data set containing all the real estate transactions in a town can be grouped by the year the transaction occurred; or it can be grouped by the sale price of the transaction; or it can be grouped by the buyer's last name; and so on.
Such a grouping uses the relational model (a technical term for this schema). Hence such a database is called a "relational database."
The software used to do this grouping is called a relational database management system. The term "relational database" often refers to this type of software.
Relational databases are currently the predominate choice in storing financial records, manufacturing and logistical information, personnel data and much more.
Contents |
[edit] Contents
Strictly, a relational database is a collection of relations (frequently called tables). Other items are frequently considered part of the database, as they help to organize and structure the data, in addition to forcing the database to conform to a set of requirements.
[edit] Terminology
The term relational database was originally defined and coined by Edgar Codd at IBM Almaden Research Center in 1970.[1]
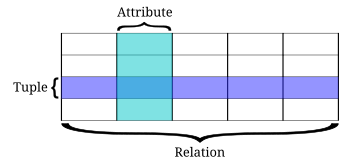
Relational database theory uses a different set of mathematical-based terms, which are equivalent, or roughly equivalent, to SQL database terminology. The table below summarizes some of the most important relational database terms and their SQL database equivalents.
| Relational term | SQL equivalent |
|---|---|
| relation, base relvar | table |
| derived relvar | view, query result, result set |
| tuple | row |
| attribute | column |
[edit] Relations or Tables
A relation is defined as a set of tuples that have the same attributes. A tuple usually represents an object and information about that object. Objects are typically physical objects or concepts. A relation is usually described as a table, which is organized into rows and columns. All the data referenced by an attribute are in the same domain and conform to the same constraints.
The relational model specifies that the tuples of a relation have no specific order and that the tuples, in turn, impose no order on the attributes. Applications access data by specifying queries, which use operations such as select to identify tuples, project to identify attributes, and join to combine relations. Relations can be modified using the insert, delete, and update operators. New tuples can supply explicit values or be derived from a query. Similarly, queries identify tuples for updating or deleting.
[edit] Base and derived relations
In a relational database, all data is stored and accessed via relations. Relations that store data are called "base relations", and in implementations are called "tables". Other relations do not store data, but are computed by applying relational operations to other relations. These relations are sometimes called "derived relations". In implementations these are called "views" or "queries". Derived relations are convenient in that though they may grab information from several relations, they act as a single relation. Also, derived relations can be used as an abstraction layer.
[edit] Domain
A domain describes the set of possible values for a given attribute. Because a domain constrains the attribute's values and name, it can be considered constraints. Mathematically, attaching a domain to an attribute means that "all values for this attribute must be an element of the specified set."
The character data value 'ABC', for instance, is not in the integer domain. The integer value 123, satisfies the domain constraint.
[edit] Constraints
Constraints allow you to further restrict the domain of an attribute. For instance, a constraint can restrict a given integer attribute to values between 1 and 10. Constraints provide one method of implementing business rules in the database. SQL implements constraint functionality in the form of check constraints.
Constraints restrict the data that can be stored in relations. These are usually defined using expressions that result in a boolean value, indicating whether or not the data satisfies the constraint. Constraints can apply to single attributes, to a tuple (restricting combinations of attributes) or to an entire relation.
Since every attribute has an associated domain, there are constraints (domain constraints). The two principal rules for the relational model are known as entity integrity and referential integrity.
[edit] Foreign keys
A foreign key is a reference to a key in another relation, meaning that the referencing tuple has, as one of its attributes, the values of a key in the referenced tuple. Foreign keys need not have unique values in the referencing relation. Foreign keys effectively use the values of attributes in the referenced relation to restrict the domain of one or more attributes in the referencing relation.
A foreign key could be described formally as: "For all tuples in the referencing relation projected over the referencing attributes, there must exist a tuple in the referenced relation projected over those same attributes such that the values in each of the referencing attributes match the corresponding values in the referenced attributes."
[edit] Stored procedures
A stored procedure is executable code that is associated with, and generally stored in, the database. Stored procedures usually collect and customize common operations, like inserting a tuple into a relation, gathering statistical information about usage patterns, or encapsulating complex business logic and calculations. Frequently they are used as an application programming interface (API) for security or simplicity. Implementations of stored procedures on SQL DBMSs often allow developers to take advantage of procedural extensions (often vendor-specific) to the standard declarative SQL syntax.
Stored procedures are not part of the relational database model, but all commercial implementations include them.
[edit] Indices
An index is one way of providing quicker access to data. Indices can be created on any combination of attributes on a relation. Queries that filter using those attributes can find matching tuples randomly using the index, without having to check each tuple in turn. Relational databases typically supply multiple indexing techniques, each of which is optimal for some combination of data distribution, relation size, and typical access pattern. B+ trees, R-trees, and bitmaps.
Indices are usually not considered part of the database, as they are considered an implementation detail, though indices are usually maintained by the same group that maintains the other parts of the database.
[edit] Relational operations
Queries made against the relational database, and the derived relvars in the database are expressed in a relational calculus or a relational algebra. In his original relational algebra, Codd introduced eight relational operators in two groups of four operators each. The first four operators were based on the traditional mathematical set operations:
- The union operator combines the tuples of two relations and removes all duplicate tuples from the result. The relational union operator is equivalent to the SQL UNION operator.
- The intersection operator produces the set of tuples that two relations share in common. Intersection is implemented in SQL in the form of the INTERSECT operator.
- The difference operator acts on two relations and produces the set of tuples from the first relation that do not exist in the second relation. Difference is implemented in SQL in the form of the EXCEPT or MINUS operator.
- The cartesian product of two relations is a join that is not restricted by any criteria, resulting in every tuple of the first relation being matched with every tuple of the second relation. The cartesian product is implemented in SQL as the CROSS JOIN join operator.
The remaining operators proposed by Codd involve special operations specific to relational databases:
- The selection, or restriction, operation retrieves tuples from a relation, limiting the results to only those that meet a specific criteria, i.e. a subset in terms of set theory. The SQL equivalent of selection is the SELECT query statement with a WHERE clause.
- The projection operation is essentially a selection operation in which duplicate tuples are removed from the result. The SQL GROUP BY clause, or the DISTINCT keyword implemented by some SQL dialects, can be used to remove duplicates from a result set.
- The join operation defined for relational databases is often referred to as a natural join. In this type of join, two relations are connected by their common attributes. SQL's approximation of a natural join is the INNER JOIN join operator.
- The relational division operation is a slightly more complex operation, which involves essentially using the tuples of one relation (the dividend) to partition a second relation (the divisor). The relational division operator is effectively the opposite of the cartesian product operator (hence the name).
Other operators have been introduced or proposed since Codd's introduction of the original eight including relational comparison operators and extensions that offer support for nesting and hierarchical data, among others.
[edit] Normalization
Normalization was first proposed by Codd as an integral part of the relational model. It encompasses a set of best practices designed to eliminate the duplication of data, which in turn prevents data manipulation anomalies and loss of data integrity. The most common forms of normalization applied to databases are called the normal forms. Normalization trades reducing redundancy for increased information entropy. Normalization is criticised because it increases complexity and processing overhead required to join multiple tables representing what are conceptually a single item[citation needed].
[edit] Relational database management systems
Relational databases, as implemented in relational database management systems, have become a predominant choice for the storage of information in new databases used for financial records, manufacturing and logistical information, personnel data and much more. Relational databases have often replaced legacy hierarchical databases and network databases because they are easier to understand and use, even though they are much less efficient. As computer power has increased, the inefficiencies of relational databases, which made them impractical in earlier times, have been outweighed by their ease of use. However, relational databases have been challenged by Object Databases, which were introduced in an attempt to address the object-relational impedance mismatch in relational database, and XML databases.
The three leading commercial relational database vendors are Oracle, Microsoft, and IBM.[citation needed] The leading open source implementations are MySQL and PostgreSQL.[citation needed]
[edit] References
- ^ Codd, E.F. (1970). "A Relational Model of Data for Large Shared Data Banks". Communications of the ACM 13 (6): 377–387. doi:.

