Reliability engineering
From Wikipedia, the free encyclopedia
Reliability engineering is an engineering field, that deals with the study of reliability: the ability of a system or component to perform its required functions under stated conditions for a specified period of time.[1] It is often reported in terms of a probability.
[edit] Overview

Reliability may be defined in several ways:
- The idea that something is fit for purpose with respect to time;
- The capacity of a device or system to perform as designed;
- The resistance to failure of a device or system;
- The ability of a device or system to perform a required function under stated conditions for a specified period of time;
- The probability that a functional unit will perform its required function for a specified interval under stated conditions.
- The ability of something to "fail well" (fail without catastrophic consequences)
Reliability engineers rely heavily on statistics, probability theory, and reliability theory. Many engineering techniques are used in reliability engineering, such as reliability prediction, Weibull analysis, thermal management, reliability testing and accelerated life testing. Because of the large number of reliability techniques, their expense, and the varying degrees of reliability required for different situations, most projects develop a reliability program plan to specify the reliability tasks that will be performed for that specific system.
The function of reliability engineering is to develop the reliability requirements for the product, establish an adequate reliability program, and perform appropriate analyses and tasks to ensure the product will meet its requirements. These tasks are managed by a reliability engineer, who usually holds an accredited engineering degree and has additional reliability-specific education and training. Reliability engineering is closely associated with maintainability engineering and logistics engineering. Many problems from other fields, such as security engineering, can also be approached using reliability engineering techniques. This article provides an overview of some of the most common reliability engineering tasks. Please see the references for a more comprehensive treatment.
Many types of engineering employ reliability engineers and use the tools and methodology of reliability engineering. For example:
- System engineers design complex systems having a specified reliability
- Mechanical engineers may have to design a machine or system with a specified reliability
- Automotive engineers have reliability requirements for the automobiles (and components) which they design
- Electronics engineers must design and test their products for reliability requirements.
- In software engineering and systems engineering the reliability engineering is the subdiscipline of ensuring that a system (or a device in general) will perform its intended function(s) when operated in a specified manner for a specified length of time. Reliability engineering is performed throughout the entire life cycle of a system, including development, test, production and operation.
[edit] Reliability theory
Main articles: reliability theory, failure rate.
Reliability theory is the foundation of reliability engineering. For engineering purposes, reliability is defined as:
-
-
- the probability that a device will perform its intended function during a specified period of time under stated conditions.
-
Mathematically, this may be expressed as,
-
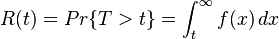 ,
,
-
- where
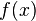 is the failure probability density function and t is the length of the period of time (which is assumed to start from time zero).
is the failure probability density function and t is the length of the period of time (which is assumed to start from time zero).
- where
Reliability engineering is concerned with four key elements of this definition:
-
- First, reliability is a probability. This means that failure is regarded as a random phenomenon: it is a recurring event, and we do not express any information on individual failures, the causes of failures, or relationships between failures, except that the likelihood for failures to occur varies over time according to the given probability function. Reliability engineering is concerned with meeting the specified probability of success, at a specified statistical confidence level.
- Second, reliability is predicated on "intended function:" Generally, this is taken to mean operation without failure. However, even if no individual part of the system fails, but the system as a whole does not do what was intended, then it is still charged against the system reliability. The system requirements specification is the criterion against which reliability is measured.
- Third, reliability applies to a specified period of time. In practical terms, this means that a system has a specified chance that it will operate without failure before time
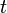 . Reliability engineering ensures that components and materials will meet the requirements during the specified time. Units other than time may sometimes be used. The automotive industry might specify reliability in terms of miles, the military might specify reliability of a gun for a certain number of rounds fired. A piece of mechanical equipment may have a reliability rating value in terms of cycles of use.
. Reliability engineering ensures that components and materials will meet the requirements during the specified time. Units other than time may sometimes be used. The automotive industry might specify reliability in terms of miles, the military might specify reliability of a gun for a certain number of rounds fired. A piece of mechanical equipment may have a reliability rating value in terms of cycles of use. - Fourth, reliability is restricted to operation under stated conditions. This constraint is necessary because it is impossible to design a system for unlimited conditions. A Mars Rover will have different specified conditions than the family car. The operating environment must be addressed during design and testing.
[edit] Reliability program plan
Many tasks, methods, and tools can be used to achieve reliability. Every system requires a different level of reliability. A commercial airliner must operate under a wide range of conditions. The consequences of failure are grave, but there is a correspondingly higher budget. A pencil sharpener may be more reliable than an airliner, but has a much different set of operational conditions, insignificant consequences of failure, and a much lower budget.
A reliability program plan is used to document exactly what tasks, methods, tools, analyses, and tests are required for a particular system. For complex systems, the reliability program plan is a separate document. For simple systems, it may be combined with the systems engineering management plan or integrated Logistics Support management plan. The reliability program plan is essential for a successful reliability program and is developed early during system development. It specifies not only what the reliability engineer does, but also the tasks performed by others. The reliability program plan is approved by top program management.
[edit] Reliability requirements
For any system, one of the first tasks of reliability engineering is to adequately specify the reliability requirements. Reliability requirements address the system itself, test and assessment requirements, and associated tasks and documentation. Reliability requirements are included in the appropriate system/subsystem requirements specifications, test plans, and contract statements.
[edit] System reliability parameters
Requirements are specified using reliability parameters. The most common reliability parameter is the Mean_Time_Between_Failures (MTBF), which can also be specified as the failure rate or the number of failures during a given period. These parameters are very useful for systems that are operated on a regular basis, such as most vehicles, machinery, and electronic equipment. Reliability increases as the MTBF increases. The MTBF is usually specified in hours, but can also be used with other units of measurement such as miles or cycles.
In other cases, reliability is specified as the probability of mission success. For example, reliability of a scheduled aircraft flight can be specified as a dimensionless probability or a percentage. refer to system safety engineering.
A special case of mission success is the single-shot device or system. These are devices or systems that remain relatively dormant and only operate once. Examples include automobile airbags, thermal batteries and missiles. Single-shot reliability is specified as a probability of success, or is subsumed into a related parameter. Single-shot missile reliability may be incorporated into a requirement for the probability of hit.
For such systems, the probability of failure on demand (PFD) is the reliability measure. This PFD is derived from failure rate and mission time for non-repairable systems. For repairable systems, it is obtained from failure rate and mean-time-to-repair (MTTR) and test interval. This measure may not be unique for a given system as this measure depends on the kind of demand. In addition to system level requirements, reliability requirements may be specified for critical subsystems. In all cases, reliability parameters are specified with appropriate statistical confidence intervals.
[edit] Reliability modelling
Reliability modelling is the process of predicting or understanding the reliability of a component or system. Two separate fields of investigation are common: The physics of failure approach uses an understanding of the failure mechanisms involved, such as crack propagation or chemical corrosion; The parts stress modelling approach is an empirical method for prediction based on counting the number and type of components of the system, and the stress they undergo during operation.
For systems with a clearly defined failure time (which is sometimes not given for systems with a drifting parameter), the empirical distribution function of these failure times can be determined. This is done in general in an accelerated experiment with increased stress. These experiments can be divided into two main categories:
Early failure rate studies determine the distribution with a decreasing failure rate over the first part of the bathtub curve. Here in general only moderate stress is necessary. The stress is applied for a limited period of time in what is called a censored test. Therefore, only the part of the distribution with early failures can be determined.
In so-called zero defect experiments, only limited information about the failure distribution is acquired. Here the stress, stress time, or the sample size is so low that not a single failure occurs. Due to the insufficient sample size, only an upper limit of the early failure rate can be determined. At any rate, it looks good for the customer if there are no failures.
In a study of the intrinsic failure distribution, which is often a material property, higher stresses are necessary to get failure in a reasonable period of time. Several degrees of stress have to be applied to determine an acceleration model. The empirical failure distribution is often parametrised with a Weibull or a log-normal model.
It is a general praxis to model the early failure rate with an exponential distribution. This less complex model for the failure distribution has only one parameter: the constant failure rate. In such cases, the Chi-square distribution can be used to find the goodness of fit for the estimated failure rate. Compared to a model with a decreasing failure rate, this is quite pessimistic. Combined with a zero-defect experiment this becomes even more pessimistic. The effort is greatly reduced in this case: one does not have to determine a second model parameter (e.g. the shape parameter of a Weibull distribution, or its confidence interval (e.g by an MLE / Maximum likelihood approach) - and the sample size is much smaller.
[edit] Reliability test requirements
Because reliability is a probability, even highly reliable systems have some chance of failure. However, testing reliability requirements is problematic for several reasons. A single test is insufficient to generate enough statistical data. Multiple tests or long-duration tests are usually very expensive. Some tests are simply impractical. Reliability engineering is used to design a realistic and affordable test program that provides enough evidence that the system meets its requirement. Statistical confidence levels are used to address some of these concerns. A certain parameter is expressed along with a corresponding confidence level: for example, an MTBF of 1000 hours at 90% confidence level. From this specification, the reliability engineer can design a test with explicit criteria for the number of hours and number of failures until the requirement is met or failed.
The combination of reliability parameter value and confidence level greatly affects the development cost and the risk to both the customer and producer. Care is needed to select the best combination of requirements. Reliability testing may be performed at various levels, such as component, subsystem, and system. Also, many factors must be addressed during testing, such as extreme temperature and humidity, shock, vibration, and heat. Reliability engineering determines an effective test strategy so that all parts are exercised in relevant environments. For systems that must last many years, reliability engineering may be used to design an accelerated life test.
[edit] Requirements for reliability tasks
Reliability engineering must also address requirements for various reliability tasks and documentation during system development, test, production, and operation. These requirements are generally specified in the contract statement of work and depend on how much leeway the customer wishes to provide to the contractor. Reliability tasks include various analyses, planning, and failure reporting. Task selection depends on the criticality of the system as well as cost. A critical system may require a formal failure reporting and review process throughout development, whereas a non-critical system may rely on final test reports. The most common reliability program tasks are documented in reliability program standards, such as MIL-STD-785 and IEEE 1332. Failure reporting analysis and corrective action systems are a common approach for product/process reliability monitoring.
[edit] Design for reliability
Design For Reliability (DFR), is an emerging discipline that refers to the process of designing reliability into products. This process encompasses several tools and practices and describes the order of their deployment that an organization needs to have in place in order to drive reliability into their products. Typically, the first step in the DFR process is to set the system’s reliability requirements. Reliability must be "designed in" to the system. During system design, the top-level reliability requirements are then allocated to subsystems by design engineers and reliability engineers working together.
Reliability design begins with the development of a model. Reliability models use block diagrams and fault trees to provide a graphical means of evaluating the relationships between different parts of the system. These models incorporate predictions based on parts-count failure rates taken from historical data. While the predictions are often not accurate in an absolute sense, they are valuable to assess relative differences in design alternatives.

One of the most important design techniques is redundancy. This means that if one part of the system fails, there is an alternate success path, such as a backup system. An automobile brake light might use two light bulbs. If one bulb fails, the brake light still operates using the other bulb. Redundancy significantly increases system reliability, and is often the only viable means of doing so. However, redundancy is difficult and expensive, and is therefore limited to critical parts of the system. Another design technique, physics of failure, relies on understanding the physical processes of stress, strength and failure at a very detailed level. Then the material or component can be re-designed to reduce the probability of failure. Another common design technique is component derating: Selecting components whose tolerance significantly exceeds the expected stress, as using a heavier gauge wire that exceeds the normal specification for the expected electrical current.
Many tasks, techniques and analyses are specific to particular industries and applications. Commonly these include:
-
- Built-in test (BIT)
- Failure mode and effects analysis (FMEA)
- Reliability simulation modeling
- Thermal analysis
- Reliability Block Diagram analysis
- Fault tree analysis
- Root cause analysis
- Sneak circuit analysis
- Accelerated Testing
- Reliability Growth analysis
- Weibull analysis
- Electromagnetic analysis
- Statistical interference
- Avoid Single Point of Failure
Results are presented during the system design reviews and logistics reviews. Reliability is just one requirement among many system requirements. Engineering trade studies are used to determine the optimum balance between reliability and other requirements and constraints.
[edit] Reliability testing

The purpose of reliability testing is to discover potential problems with the design as early as possible and, ultimately, provide confidence that the system meets its reliability requirements.
Reliability testing may be performed at several levels. Complex systems may be tested at component, circuit board, unit, assembly, subsystem and system levels. (The test level nomenclature varies among applications.) For example, performing environmental stress screening tests at lower levels, such as piece parts or small assemblies, catches problems before they cause failures at higher levels. Testing proceeds during each level of integration through full-up system testing, developmental testing, and operational testing, thereby reducing program risk. System reliability is calculated at each test level. Reliability growth techniques and failure reporting, analysis and corrective active systems (FRACAS) are often employed to improve reliability as testing progresses. The drawbacks to such extensive testing are time and expense. Customers may choose to accept more risk by eliminating some or all lower levels of testing.
It is not always feasible to test all system requirements. Some systems are prohibitively expensive to test; some failure modes may take years to observe; some complex interactions result in a huge number of possible test cases; and some tests require the use of limited test ranges or other resources. In such cases, different approaches to testing can be used, such as accelerated life testing, design of experiments, and simulations.
The desired level of statistical confidence also plays an important role in reliability testing. Statistical confidence is increased by increasing either the test time or the number of items tested. Reliability test plans are designed to achieve the specified reliability at the specified confidence level with the minimum number of test units and test time. Different test plans result in different levels of risk to the producer and consumer. The desired reliability, statistical confidence, and risk levels for each side influence the ultimate test plan. Good test requirements ensure that the customer and developer agree in advance on how reliability requirements will be tested.
A key aspect of reliability testing is to define "failure". Although this may seem obvious, there are many situations where it is not clear whether a failure is really the fault of the system. Variations in test conditions, operator differences, weather, and unexpected situations create differences between the customer and the system developer. One strategy to address this issue is to use a scoring conference process. A scoring conference includes representatives from the customer, the developer, the test organization, the reliability organization, and sometimes independent observers. The scoring conference process is defined in the statement of work. Each test case is considered by the group and "scored" as a success or failure. This scoring is the official result used by the reliability engineer.
As part of the requirements phase, the reliability engineer develops a test strategy with the customer. The test strategy makes trade-offs between the needs of the reliability organization, which wants as much data as possible, and constraints such as cost, schedule, and available resources. Test plans and procedures are developed for each reliability test, and results are documented in official reports.
[edit] Accelerated testing
The purpose of accelerated life testing is to induce field failure in the laboratory at a much faster rate by providing a harsher, but nonetheless representative, environment. In such a test the product is expected to fail in the lab just as it would have failed in the field—but in much less time. The main objective of an accelerated test is either of the following:
-
- To discover failure modes
- To predict the normal field life from the high stress lab life
An Accelerated testing program can be broken down into the following steps:
-
- Define objective and scope of the test
- Collect required information about the product
- Identify the stress(es)
- Determine level of stress(es)
- Conduct the Accelerated test and analyse the accelerated data.
Common way to determine a life stress relationship are
-
- Arrhenius Model
- Eyring Model
- Inverse Power Law Model
- Temperature-Humidity Model
- Temperature Non-thermal Model
[edit] Software reliability
Software reliability is a special aspect of reliability engineering. System reliability, by definition, includes all parts of the system, including hardware, software, operators and procedures. Traditionally, reliability engineering focuses on critical hardware parts of the system. Since the widespread use of digital integrated circuit technology, software has become an increasingly critical part of most electronics and, hence, nearly all present day systems. There are significant differences, however, in how software and hardware behave. Most hardware unreliability is the result of a component or material failure that results in the system not performing its intended function. Repairing or replacing the hardware component restores the system to its original unfailed state. However, software does not fail in the same sense that hardware fails. Instead, software unreliability is the result of unanticipated results of software operations. Even relatively small software programs can have astronomically large combinations of inputs and states that are infeasible to exhaustively test. Restoring software to its original state only works until the same combination of inputs and states results in the same unintended result. Software reliability engineering must take this into account.
Despite this difference in the source of failure between software and hardware — software doesn’t wear out — some in the software reliability engineering community believe statistical models used in hardware reliability are nevertheless useful as a measure of software reliability, describing what we experience with software: the longer you run software, the higher the probability you’ll eventually use it in an untested manner and find a latent defect that results in a failure (Shooman 1987), (Musa 2005), (Denney 2005).
As with hardware, software reliability depends on good requirements, design and implementation. Software reliability engineering relies heavily on a disciplined software engineering process to anticipate and design against unintended consequences. There is more overlap between software quality engineering and software reliability engineering than between hardware quality and reliability. A good software development plan is a key aspect of the software reliability program. The software development plan describes the design and coding standards, peer reviews, unit tests, configuration management, software metrics and software models to be used during software development.
A common reliability metric is the number of software faults, usually expressed as faults per thousand lines of code. This metric, along with software execution time, is key to most software reliability models and estimates. The theory is that the software reliability increases as the number of faults (or fault density) goes down. Establishing a direct connection between fault density and mean-time-between-failure is difficult, however, because of the way software faults are distributed in the code, their severity, and the probability of the combination of inputs necessary to encounter the fault. Nevertheless, fault density serves as a useful indicator for the reliability engineer. Other software metrics, such as complexity, are also used.
Testing is even more important for software than hardware. Even the best software development process results in some software faults that are nearly undetectable until tested. As with hardware, software is tested at several levels, starting with individual units, through integration and full-up system testing. Unlike hardware, it is inadvisable to skip levels of software testing. During all phases of testing, software faults are discovered, corrected, and re-tested. Reliability estimates are updated based on the fault density and other metrics. At system level, mean-time-between-failure data is collected and used to estimate reliability. Unlike hardware, performing the exact same test on the exact same software configuration does not provide increased statistical confidence. Instead, software reliability uses different metrics such as test coverage.
Eventually, the software is integrated with the hardware in the top-level system, and software reliability is subsumed by system reliability. The Software Engineering Institute's Capability Maturity Model is a common means of assessing the overall software development process for reliability and quality purposes.
[edit] Reliability operational assessment
After a system is produced, reliability engineering monitors, assesses, and corrects deficiencies. Monitoring includes electronic and visual surveillance of critical parameters identified during the fault tree analysis design stage. The data is constantly analyzed using statistical techniques, such as Weibull analysis and linear regression, to ensure the system reliability meets requirements. Reliability data and estimates are also key inputs for system logistics. Data collection is highly dependent on the nature of the system. Most large organizations have quality control groups that collect failure data on vehicles, equipment, and machinery. Consumer product failures are often tracked by the number of returns. For systems in dormant storage or on standby, it is necessary to establish a formal surveillance program to inspect and test random samples. Any changes to the system, such as field upgrades or recall repairs, require additional reliability testing to ensure the reliability of the modification. Since it is not possible to anticipate all the failure modes of a given system, especially ones with a human element, failures will occur. The reliability program also includes a systematic root cause analysis that identifies the causal relationships involved in the failure such that effective corrective actions may be implemented. When possible, system failures and corrective actions are reported to the reliability engineering organization.
One of the most common methods for Reliability Operational Assessment is a FRACAS – a systematic approach for reliability, safety and logistics assessment based on Failure / Incident reporting, management, analysis and corrective/preventive actions. Organizations today are adopting this method and utilize commercial systems such as a Web based FRACAS application enabling and organization to create a failure/incident data repository from which statistics can be derived to view accurate and genuine reliability, safety and quality performances.
Some of the common outputs from a FRACAS system includes: Field MTBF, MTTR, Spares Consumption, Reliability Growth, Failure/Incidents distribution by type, location, part no., serial no, symptom etc.
[edit] Reliability organizations
Systems of any significant complexity are developed by organizations of people, such as a commercial company or a government agency. The reliability engineering organization must be consistent with the company's organizational structure. For small, non-critical systems, reliability engineering may be informal. As complexity grows, the need arises for a formal reliability function. Because reliability is important to the customer, the customer may even specify certain aspects of the reliability organization.
There are several common types of reliability organizations. The project manager or chief engineer may employ one or more reliability engineers directly. In larger organizations, there is usually a product assurance or specialty engineering organization, which may include reliability, maintainability, quality, safety, human factors, logistics, etc. In such case, the reliability engineer reports to the product assurance manager or specialty engineering manager.
In some cases, a company may wish to establish an independent reliability organization. This is desirable to ensure that the system reliability, which is often expensive and time consuming, is not unduly slighted due to budget and schedule pressures. In such cases, the reliability engineer works for the project on a day-to-day basis, but is actually employed and paid by a separate organization within the company.
Because reliability engineering is critical to early system design, it has become common for reliability engineers, however the organization is structured, to work as part of an integrated product team.
[edit] Certification
The American Society for Quality has a program to become a Certified Reliability Engineer, CRE. Certification is based on education, experience, and a certification test: periodic recertification is required. The body of knowledge for the test includes: reliability management, design evaluation, product safety, statistical tools, design and development, modeling, reliability testing, collecting and using data, etc.
Another highly respected certification program is the CRP (Certified Reliability Professional). To achieve certification, candidates must complete a series of courses focused on important Reliability Engineering topics, successfully apply the learned body of knowledge in the workplace and publicly present this expertise in an industry conference or journal.
[edit] Reliability engineering education
Some Universities offer graduate degrees in Reliability Engineering (e.g., see University of Maryland, College Park and Concordia University, Montreal, Canada). Other reliability engineers typically have an engineering degree, which can be in any field of engineering, from an accredited university or college program. Many engineering programs offer reliability courses, and some universities have entire reliability engineering programs. A reliability engineer may be registered as a Professional Engineer by the state, but this is not required by most employers. There are many professional conferences and industry training programs available for reliability engineers. Several professional organizations exist for reliability engineers, including the IEEE Reliability Society, the American Society for Quality (ASQ), and the Society of Reliability Engineers (SRE).
[edit] See also
- Bayesian inference
- Burn in
- Failing badly
- Failure rate
- Human reliability
- Integrated Logistics Support
- Highly accelerated stress test
- Highly Accelerated Life Test
- Logistic engineering
- Performance engineering
- Professional engineer
- Product qualification
- Quality engineering
- Reliability
- Reliable system design
- Reliability theory
- Reliability theory of aging and longevity
- Redundancy (total quality management)
- Security engineering
- Single Point of Failure
- Software engineering
- Systems engineering
- Safety engineering
- Statistics
- Temperature cycling
[edit] References
|
|
This article needs additional citations for verification. Please help improve this article by adding reliable references (ideally, using inline citations). Unsourced material may be challenged and removed. (October 2008) |
[edit] Further reading
- Blanchard, Benjamin S. (1992), Logistics Engineering and Management (Fourth Ed.), Prentice-Hall, Inc., Englewood Cliffs, New Jersey.
- Ebeling, Charles E., (1997), An Introduction to Reliability and Maintainability Engineering, McGraw-Hill Companies, Inc., Boston.
- Denney, Richard (2005) Succeeding with Use Cases: Working Smart to Deliver Quality. Addison-Wesley Professional Publishing. ISBN . Discusses the use of software reliability engineering in use case driven software development.
- Gano, Dean L. (2007), "Apollo Root Cause Analysis" (Third Edition), Apollonian Publications, LLC., Richland, Washington
- Kapur, K.C., and Lamberson, L.R., (1977), Reliability in Engineering Design, John Wiley & Sons, New York.
- Kececioglu, Dimitri, (1991) "Reliability Engineering Handbook", Prentice-Hall, Englewood Cliffs, New Jersey
- Trevor Kletz (1998) Process Plants: A Handbook for Inherently Safer Design CRC ISBN: 1560326190
- Leemis, Lawrence, (1995) Reliability: Probabilistic Models and Statistical Methods, 1995, Prentice-Hall. ISBN 0-13-720517-1
- Frank Lees (2005). Loss Prevention in the Process Industries (3rdEdition ed.). Elsevier. ISBN 978-0-7506-7555-0.
- MacDiarmid, Preston; Morris, Seymour; et al., (1995), Reliability Toolkit: Commercial Practices Edition, Reliability Analysis Center and Rome Laboratory, Rome, New York.
- Modarres, Mohammad; Kaminskiy, Mark; Krivtsov, Vasiliy (1999), "Reliability Engineering and Risk Analysis: A Practical Guide, CRC Press, ISBN 0-8247-2000-8.
- Musa, John (2005) Software Reliability Engineering: More Reliable Software Faster and Cheaper, 2nd. Edition, AuthorHouse. ISBN
- Neubeck, Ken (2004) "Practical Reliability Analysis", Prentice Hall, New Jersey
- Neufelder, Ann Marie, (1993), Ensuring Software Reliability, Marcel Dekker, Inc., New York.
- O'Connor, Patrick D. T. (2002), Practical Reliability Engineering (Fourth Ed.), John Wiley & Sons, New York.
- Shooman, Martin, (1987), Software Engineering: Design, Reliability, and Management, McGraw-Hill, New York.
- Tobias, Trindade, (1995), Applied Reliability, Chapman & Hall/CRC, ISBN 0-442-00469-9
- Springer Series in Reliability Engineering
- Nelson, Wayne B., (2004), Accelerated Testing - Statistical Models, Test Plans, and Data Analysis, John Wiley & Sons, New York, ISBN 0-471-69736-2
[edit] US standards
- MIL-STD-785, Reliability Program for Systems and Equipment Development and Production, U.S. Department of Defense.
- MIL-HDBK-217, Reliability Prediction of Electronic Equipment, U.S. Department of Defense.
- MIL-STD-2173, Reliability Centered Maintenance Requirements, U.S. Department of Defense (superseded by NAVAIR 00-25-403)
- MIL-HDBK-338B, Electronic Reliability Design Handbook, U.S. Department of Defense.
- MIL-STD-1629A, PROCEDURES FOR PERFORMING A FAILURE MODE, EFFECTS AND CRlTlCALlTY ANALYSIS
- MIL-HDBK-781A, Reliability Test Methods, Plans, and Environments for Engineering Development, Qualification, and Production, U.S. Department of Defense.
- IEEE 1332, IEEE Standard Reliability Program for the Development and Production of Electronic Systems and Equipment, Institute of Electrical and Electronics Engineers.
- Federal Standard 1037C in support of MIL-STD-188
[edit] UK standards
In the UK, there are more up to date standards maintained under the sponsorship of UK MOD as Defence Standards. The relevant Standards include:
DEF STAN 00-40 Reliability and Maintainability (R&M)
- PART 1: Issue 5: Management Responsibilities and Requirements for Programmes and Plans
- PART 4: (ARMP-4)Issue 2: Guidance for Writing NATO R&M Requirements Documents
- PART 6: Issue 1: IN-SERVICE R & M
- PART 7 (ARMP-7) Issue 1: NATO R&M Terminology Applicable to ARMP’s
DEF STAN 00-41 : Issue 3: RELIABILITY AND MAINTAINABILITY MOD GUIDE TO PRACTICES AND PROCEDURES
DEF STAN 00-42 RELIABILITY AND MAINTAINABILITY ASSURANCE GUIDES
- PART 1: Issue 1: ONE-SHOT DEVICES/SYSTEMS
- PART 2: Issue 1: SOFTWARE
- PART 3: Issue 2: R&M CASE
- PART 4: Issue 1: Testability
- PART 5: Issue 1: IN-SERVICE RELIABILITY DEMONSTRATIONS
DEF STAN 00-43 RELIABILITY AND MAINTAINABILITY ASSURANCE ACTIVITY
- PART 2: Issue 1: IN-SERVICE MAINTAINABILITY DEMONSTRATIONS
DEF STAN 00-44 RELIABILITY AND MAINTAINABILITY DATA COLLECTION AND CLASSIFICATION
- PART 1: Issue 2: MAINTENANCE DATA & DEFECT REPORTING IN THE ROYAL NAVY, THE ARMY AND THE ROYAL AIR FORCE
- PART 2: Issue 1: DATA CLASSIFICATION AND INCIDENT SENTENCING - GENERAL
- PART 3: Issue 1: INCIDENT SENTENCING - SEA
- PART 4: Issue 1: INCIDENT SENTENCING - LAND
DEF STAN 00-45 Issue 1: RELIABILITY CENTERED MAINTENANCE
DEF STAN 00-49 Issue 1: RELIABILITY AND MAINTAINABILITY MOD GUIDE TO TERMINOLOGY DEFINITIONS
These can be obtained from DSTAN. There are also many commercial standards, produced by many organistions including the SAE, MSG, ARP, and IEE.
[edit] External links
|
|
This article's external links may not follow Wikipedia's content policies or guidelines. Please improve this article by removing excessive or inappropriate external links. |
- American Society for Quality
- Carnegie Mellon Software Engineering Institute
- IEEE Reliability Society
- NASA Hardware and Software Reliability report
- NIST/SEMATECH, "Engineering Statistics Handbook", [1]
- Reliability Information Analysis Center
- Safety and Reliability Society
- Society of Reliability Engineers
- University of Maryland Reliability Engineering Program
- Models and methods regarding reliability analysis
- UK Defence Standardization Organisation's Home on the Web
- Center for Risk and Reliability at University of Maryland, College Park
- Reliability and Safety Software Tools
- On-line Reliability Engineering Resources for the Reliability
- Reliability Software
Professional
- Reliability Basics (various analysis overviews)
- Online Reliability calculator
- Online expertise center about reliability (PoF)
- Reliability Engineer's Toolbox - Automated tools and electronic information for reliability engineering activities.
|
||||||||||||||||||||

