Statistical classification
From Wikipedia, the free encyclopedia
Statistical classification is a procedure in which individual items are placed into groups based on quantitative information on one or more characteristics inherent in the items (referred to as traits, variables, characters, etc) and based on a training set of previously labeled items.
Formally, the problem can be stated as follows: given training data  produce a classifier
produce a classifier 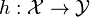 which maps any object
which maps any object 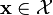 to its true classification label
to its true classification label  defined by some unknown mapping
defined by some unknown mapping  (ground truth). For example, if the problem is filtering spam, then
(ground truth). For example, if the problem is filtering spam, then  is some representation of an email and y is either "Spam" or "Non-Spam".
is some representation of an email and y is either "Spam" or "Non-Spam".
Statistical classification algorithms are typically used in pattern recognition systems.
Note: in community ecology, the term "classification" is synonymous with what is commonly known (in machine learning) as clustering. See that article for more information about purely unsupervised techniques.
- The second problem is to consider classification as an estimation problem, where the goal is to estimate a function of the form

where the feature vector input is 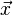 , and the function f is typically parameterized by some parameters
, and the function f is typically parameterized by some parameters  . In the Bayesian approach to this problem, instead of choosing a single parameter vector , the result is integrated over all possible thetas, with the thetas weighted by how likely they are given the training data D:
. In the Bayesian approach to this problem, instead of choosing a single parameter vector , the result is integrated over all possible thetas, with the thetas weighted by how likely they are given the training data D:

- The third problem is related to the second, but the problem is to estimate the class-conditional probabilities
 and then use Bayes' rule to produce the class probability as in the second problem.
and then use Bayes' rule to produce the class probability as in the second problem.
Examples of classification algorithms include:
- Linear classifiers
- Quadratic classifiers
- k-nearest neighbor
- Boosting
- Decision trees
- Neural networks
- Bayesian networks
- Hidden Markov models
An intriguing problem in pattern recognition yet to be solved is the relationship between the problem to be solved (data to be classified) and the performance of various pattern recognition algorithms (classifiers). Van der Walt and Barnard (see reference section) investigated very specific artificial data sets to determine conditions under which certain classifiers perform better and worse than others.
Classifier performance depends greatly on the characteristics of the data to be classified. There is no single classifier that works best on all given problems (a phenomenon that may be explained by the No-free-lunch theorem). Various empirical tests have been performed to compare classifier performance and to find the characteristics of data that determine classifier performance. Determining a suitable classifier for a given problem is however still more an art than a science.
The most widely used classifiers are the Neural Network (Multi-layer Perceptron), Support Vector Machines, k-Nearest Neighbours, Gaussian Mixture Model, Gaussian, Naive Bayes, Decision Tree and RBF classifiers.
Contents |
[edit] Evaluation
The measures Precision and Recall are popular metrics used to evaluate the quality of a classification system. More recently, Receiver Operating Characteristic (ROC) curves have been used to evaluate the tradeoff between true- and false-positive rates of classification algorithms.
[edit] Application domains
- Computer vision
- Medical Imaging and Medical Image Analysis
- Optical character recognition
- Drug discovery and development
- Geostatistics
- Speech recognition
- Handwriting recognition
- Biometric identification
- Natural language processing
- Document classification
- Internet search engines
- Credit scoring
[edit] References
- C.M. van der Walt and E. Barnard, "Data characteristics that determine classifier performance," SAIEE Africa Research Journal, Vol 98 (3), pp 87-93, September 2007.
- C.M. van der Walt, "Data measures that characterise classification problems," Master's dissertation, Department of Electrical, Electronic and Computer Engineering, University of Pretoria, South Africa, February 2008.
[edit] External links
- Classifier showdown A practical comparison of classification algorithms.
- Statistical Pattern Recognition Toolbox for Matlab.
- TOOLDIAG Pattern recognition toolbox.

