CUDA
From Wikipedia, the free encyclopedia
| Developed by | NVIDIA Corporation |
|---|---|
| Latest release | 2.1 / November 2008 |
| Operating system | Windows Vista, Windows XP, Linux, Mac OS X |
| Type | GPGPU |
| License | Proprietary, Freeware |
| Website | Nvidia's CUDA zone |
CUDA (Compute Unified Device Architecture) is a parallel computing architecture developed by NVIDIA. Simply put, CUDA is the computing engine in NVIDIA graphics processing units or GPUs, that is accessible to software developers through industry standard programming languages. Programmers use 'C for CUDA', compiled through a PathScale Open64 C compiler,[1] to code algorithms for execution on the GPU. CUDA architecture supports all computational interfaces through including C. Third party wrappers are also available for Python, Fortran and Java.
The latest drivers all contain the necessary CUDA components. CUDA works with all NVIDIA GPUs from the G8X series onwards, including GeForce, Quadro and the Tesla line. NVIDIA states that programs developed for the GeForce 8 series will also work without modification on all future Nvidia video cards, due to binary compatibility. CUDA gives developers access to the native instruction set and memory of the parallel computational elements in CUDA GPUs. Using CUDA, the latest NVIDIA GPUs effectively become open architectures like CPUs. Unlike CPUs however, GPUs have a parallel "many-core" architecture, each core capable of running thousands of threads simultaneously - if an application is suited to this kind of an architecture, the GPU can offer large performance benefits.
In the computer gaming industry, in addition to graphics rendering, graphics cards are used in game physics calculations (physical effects like debris, smoke, fire, fluids), an example being PhysX and Bullet (software). CUDA has also been used to accelerate non-graphical applications in computational biology, cryptography and other fields by an order of magnitude or more.[2][3][4][5] An example of this is the BOINC distributed computing client.[6]
CUDA provides both a low level API and a higher level API. The initial CUDA SDK was made public 15 February 2007. NVIDIA has released versions of the CUDA API for Microsoft Windows and Linux. Mac OS X was also added as a fully supported platform in version 2.0[7], which supersedes the beta released February 14, 2008.[8]
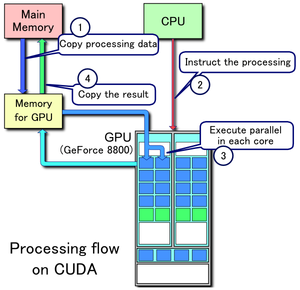
1. Copy data from main mem to GPU mem
2. CPU instructs the process to GPU
3. GPU execute parallel in each core
4. Copy the result from GPU mem to main mem
Contents |
[edit] Advantages
CUDA has several advantages over traditional general purpose computation on GPUs (GPGPU) using graphics APIs.
- Scattered reads – code can read from arbitrary addresses in memory.
- Shared memory – CUDA exposes a fast shared memory region (16KB in size) that can be shared amongst threads. This can be used as a user-managed cache, enabling higher bandwidth than is possible using texture lookups.[9]
- Faster downloads and readbacks to and from the GPU
- Full support for integer and bitwise operations, including integer texture lookups.
[edit] Limitations
- It uses a recursion-free, function-pointer-free subset of the C language, plus some simple extensions. However, a single process must run spread across multiple disjoint memory spaces, unlike other C language runtime environments.
- Texture rendering is not supported.
- Recursive functions are not supported and must be converted to loops.
- For double precision there are no deviations from the IEEE 754 standard. In single precision, Denormals and signalling NaNs are not supported; only two IEEE rounding modes are supported (chop and round-to-nearest even), and those are specified on a per-instruction basis rather than in a control word (whether this is a limitation is arguable); and the precision of division/square root is slightly lower than single precision.
- The bus bandwidth and latency between the CPU and the GPU may be a bottleneck.
- Threads should be run in groups of at least 32 for best performance, with total number of threads numbering in the thousands. Branches in the program code do not impact performance significantly, provided that each of 32 threads takes the same execution path; the SIMD execution model becomes a significant limitation for any inherently divergent task (e.g., traversing a ray tracing acceleration data structure).
- CUDA-enabled GPUs are only available from NVIDIA (GeForce 8 series and above, Quadro and Tesla).[10]
[edit] Supported GPUs
A table of devices officially supporting CUDA (Note that many applications require at least 256 MB of dedicated VRAM).[11]
|
|
|
See the Comparison of Nvidia graphics processing units for more information.
[edit] Example
This example code in C++ loads a texture from an image into an array on the GPU:
cudaArray* cu_array; texture<float, 2> tex; // Allocate array cudaMalloc(&cu_array, cudaCreateChannelDesc<float>(), width, height); // Copy image data to array cudaMemcpy(cu_array, image, width*height, cudaMemcpyHostToDevice); // Bind the array to the texture cudaBindTexture(tex, cu_array); // Run kernel dim3 blockDim(16, 16, 1); dim3 gridDim(width / blockDim.x, height / blockDim.y, 1); kernel<<< gridDim, blockDim, 0 >>>(d_odata, width, height); cudaUnbindTexture(tex); __global__ void kernel(float* odata, int height, int width) { unsigned int x = blockIdx.x*blockDim.x + threadIdx.x; unsigned int y = blockIdx.y*blockDim.y + threadIdx.y; float c = texfetch(tex, x, y); odata[y*width+x] = c; }
Below is an example given in Python that computes the product of two arrays on the GPU. The python language bindings can be obtained from PyCUDA.
import pycuda.driver as drv import numpy drv.init() dev = drv.Device(0) ctx = dev.make_context() mod = drv.SourceModule(""" __global__ void multiply_them(float *dest, float *a, float *b) { const int i = threadIdx.x; dest[i] = a[i] * b[i]; } """) multiply_them = mod.get_function("multiply_them") a = numpy.random.randn(400).astype(numpy.float32) b = numpy.random.randn(400).astype(numpy.float32) dest = numpy.zeros_like(a) multiply_them( drv.Out(dest), drv.In(a), drv.In(b), block=(400,1,1)) print dest-a*b
[edit] See also
- AMD FireStream
- GPGPU - general purpose computation on GPUs.
- Close to Metal
- OpenCL
- BrookGPU
- Lib Sh
- Comparison of MPI, OpenMP, and Stream Processing
- Nvidia Corporation
- Graphics Processing Unit (GPU)
- Stream processing
- Shader
- Jacket: A CUDA-engine for MATLAB
- Larrabee (GPU)
- Molecular modeling on GPU
[edit] References
- ^ NVIDIA on DailyTech
- ^ Giorgos Vasiliadis, Spiros Antonatos, Michalis Polychronakis, Evangelos P. Markatos and Sotiris Ioannidis (September 2008, Boston, MA, USA). "Gnort: High Performance Network Intrusion Detection Using Graphics Processors" (PDF). Proceedings of the 11th International Symposium On Recent Advances In Intrusion Detection (RAID). http://www.ics.forth.gr/dcs/Activities/papers/gnort.raid08.pdf.
- ^ Schatz, M.C., Trapnell, C., Delcher, A.L., Varshney, A. (2007). "High-throughput sequence alignment using Graphics Processing Units.". BMC Bioinformatics 8:474: 474. doi:. http://www.biomedcentral.com/1471-2105/8/474.
- ^ Pyrit - Google Code http://code.google.com/p/pyrit/
- ^ Use your NVIDIA GPU for scientific computing, BOINC official site (December 18 2008)
- ^ NVIDIA CUDA Software Development Kit (CUDA SDK) - Release Notes Version 2.0 for MAC OSX
- ^ CUDA 1.1 - Now on Mac OS X- (Posted on Feb 14, 2008)
- ^ Silberstein, Mark (2007). "Efficient computation of Sum-products on GPUs" (PDF). http://www.technion.ac.il/~marks/docs/SumProductPaper.pdf.
- ^ "CUDA-Enabled Products". CUDA Zone. NVIDIA Corporation. http://www.nvidia.com/object/cuda_learn_products.html. Retrieved on 2008-11-03.
- ^ CUDA-Enabled GPU Products
[edit] External links
- Nvidia CUDA official website
- A conversation with Jen-Hsun Huang, CEO Nvidia Charlie Rose, February 5, 2009
- Nvidia CUDA GPU Computing developer forums
- Nvidia CUDA developer registration for professional developers and researchers
- Beyond3D – Introducing CUDA Nvidia's Vision for GPU Computing March 10, 2007
- University of Illinois Nvidia CUDA Course taught by Wen-mei Hwu and David Kirk, Spring 2009
- CUDA: Breaking the Intel & AMD Dominance
- A CUDA-based Engine for MATLAB
- Ascalaph Liquid GPU molecular dynamics.
- CUDA implementation for multi-core processors
- Integrate CUDA with Visual C++, September 26, 2008
- CUDA.NET - .NET library for CUDA, Linux/Windows compliant
- Using NVIDIA GPU for scientific computing with BOINC software
- CUDA.CS.MSU.SU Russian CUDA developer community
|
||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||

