Computational complexity theory
From Wikipedia, the free encyclopedia
Computational complexity theory is a branch of the theory of computation in computer science that investigates the problems related to the resources required to run algorithms, and the inherent difficulty in providing algorithms that are efficient for both general and specific computational problems.
Contents |
[edit] Definitions
An engineer might ask "As the size of the input to an algorithm increases, by what factor does the running time and memory requirements increase? And what are the implications of that?" In other words, complexity theory, among other things, investigates the scalability of computational problems and algorithms. In particular, it places practical limits on what computers can and cannot do.
A problem is a collection of related questions, where each question is a finite string, not enumerated but written in an algebra called Big O notation, where the actual amount of resources uses numbers only to represent orders of magnitude and not the exact resources used by a particular machine.
[edit] Example
The problem of integer factorization is:
- given an integer find all of the primes into which it can be factored.
A particular question is called an instance. For example, "give the factors of the number 15" is one instance of the factorization problem. But it is not usually solved simply for the number 15; that would be a simple matter of making a back-of-the-envelope calculation and plugging the results into the program so it can regurgitate them on demand. The aim is to solve for any integer, not just 15.
[edit] Analysis
[edit] Big O notation
The time complexity of a problem is the number of steps that it takes to solve an instance of the problem as a function of the size of the input, using the most efficient known algorithm. If an instance has length n and can be solved in n2 steps we can say the problem has a time complexity of n2.
But of course, the exact amount of resources will depend on what machine or language is being used. To avoid that difficulty, the Big O notation is generally used (the O stands for the "order" of the calculation). If a problem runs in O(n2) on one computer, then (barring perverse effects) it will also run in O(n2) on all others, even though it may take longer or shorter depending on what resources they have. So this notation allows us to generalize away from the details of a particular computer.
For example, searching an unsorted list of words for a particular word will take, on average, half the time of the size of the list, because if one starts from the beginning or end one must (on average) inspect half the words in the list before finding it. If the word does not exist, one must inspect the whole list to discover that fact, so actually it could be worse, depending on how likely it is that a word in the input is in the list.
But a binary search algorithm is logarithmic in time over size (it is O(logn)). By analogy, humans roughly know where an entry would be in a phone book or dictionary, and use strategies quickly to get to their target, such as using headwords or a thumb index quickly to get roughly to the right place, then use a linear search when they are close to the target.
It is important to note that most computational complexity theory is useful in other engineering fields and has made contributions to mathematics that would be of interest even if computers did not exist.
[edit] Worst case analysis
A common approach to computational complexity is the worst-case analysis, the estimation of the largest amount of computational resources (time or space) needed to run an algorithm. In many cases, the worst-case estimates are rather too pessimistic to explain the good performance of some algorithm in real use on real input. To address this, other approaches have been sought, such as average-case analysis or smoothed analysis.
[edit] Axiomatic analysis
An axiomatic approach to computational complexity was developed by Manuel Blum. He introduced measures of complexity such as the size of a machine and measures of the computational overhead of recursive functions. The complexity of algorithms are special cases of the axiomatic complexity measure. Blum axioms help in the study of computational complexity in the most general cases.
An important aspect of the theory is to categorize computational problems and algorithms into complexity classes. The most important open question of complexity theory is whether the complexity class P is the same as the complexity class NP, or whether it is a strict subset as is generally believed[who?].
Shortly after the question was first posed, it was realised that many important industry problems in the field of operations research are of an NP subclass called NP-complete. NP-complete problems have solutions that are quick to check, yet current methods to find those solutions are not "efficiently scalable" (as described more formally below). That is, it is believed that a good algorithm exists, but finding it takes longer than the algorithm itself. Another subclass of problems are NP-hard.
If the NP class is larger than P, it can be proved[citation needed] that no efficient scalable solutions exist.
The fact that the P − NP problem has not been solved, prompts and justifies various research areas in the theory, such as:
- spotting and solving special cases of common computational problems
- the study of the computational complexity itself
- finding heuristic solutions
- researching into the hierarchies of complexity classes
- exploring multivariate algorithmic approaches such as Parameterized complexity.
[edit] Graph theory
Graph theory is used practically to solve many requirements of computer programs, Many are NP-hard, which presumes that any exact algorithm requires time exponential to its input size.
The relatively new idea of parameterized complexity is to take a two-dimensional view, where in addition to the input size we consider a parameter k; a typical parameter is the estimated size of the output. A problem is called Fixed-parameter tractable (FPT) if an instance of size n can be solved in f(k)nO(1) time, where f is some arbitrary computable function that absorbs the exponential part of the running time. Thus, whenever the parameter turns out to be small, in practice, one can expect good running times.
Various techniques to design fixed-parameter algorithms include data reduction, iterative compression, and colorcoding.
[edit] History
The first publication on computational complexity appeared in 1956.[1] But this publication in Russian was for a long time unknown in the Western world.
The beginning of studies in computational complexity can be attributed not only to Trahtenbrot,[2] but also to Rabin.[3][4][5][6][7]
Hartmanis and Stearns' paper[7] became the most popular in this area. As a result, some researchers attribute the beginning of computational complexity theory only to Hartmanis, Lewis and Stearns.[8]
Andrey Kolmogorov's research in the theory of algorithms influenced the development of computational complexity theory. A notable early discovery was the Karatsuba algorithm in 1960, for the multiplication of two numbers. This algorithm disproved Kolmogorov's 1956 conjecture that the fastest multiplication algorithm must be O(n2), and thus helped launch the study of algorithms in earnest. In 1967, Manuel Blum developed an axiomatic complexity theory based on his axioms and proved an important result, the so called, speed-up theorem.
The field was subsequently expanded by many researchers, including:
- Manuel Blum
- Allan Borodin
- Stephen Cook
- Michael Fellows
- Michael R. Garey
- Oded Goldreich
- Juris Hartmanis
- David S. Johnson
- Richard Karp
- Marek Karpinski
- Donald Knuth
- Leonid Levin
- Christos H. Papadimitriou
- Alexander Razborov
- Richard Stearns
- Leslie Valiant
- Andrew Yao
On August 6, 2002, the AKS primality test was published in a paper "PRIMES is in P"[9] by three Indian computer scientists. They showed a deterministic primality-proving algorithm they had made. The algorithm determines whether a number is a Prime number or Composite number in polynomial time, and was soon improved by others. The key significance of AKS is that it was the first published primality-proving algorithm to be all of general, polynomial, deterministic, and unconditional. The authors received the 2006 Gödel Prize and the 2006 Fulkerson Prize for their work.
[edit] Computational complexity theory topics
[edit] Time and space complexity
Complexity theory attempts to describe how difficult it is for an algorithm to find a solution to a problem. This differs from computability theory, which describes whether a problem can be solved at all: a branch of science probably made most famous by Alan Turing's essay On Computable Numbers, with an Application to the Entscheidungsproblem.
[edit] Decision problems
Much of complexity theory deals with decision problems. A decision problem is one where the answer is always "yes" or "no". Some problems are undecidable, or at least seem so, so complexity theory can be used to distinguish problems where it is certain to get a correct "yes" or "no" (not necessarily both). A problem that reverses which can be relied upon is called a complement of that problem.
For example, the problem IS − PRIME says "yes" if its input is a prime and "no" otherwise, while the problem IS − COMPOSITE says "yes" if the number is not prime. Either may be unpredictable when the correct result would be "no", they may say "yes" or perhaps never finish even if they were actually going to produce the right result, given an infinite number of monkeys.
Decision problems are often interesting to researchers because a problem can always be reduced to a decision problem. For instance, a problem HAS − FACTOR may be:
- Given integers n and k find whether n has any prime factors less than k.
If we can solve this problem with known maximum resources we can use that solution to solve the next problem FACTORIZE without many more, using a binary search on factors of k until we find the smallest, divide out that factor and repeat until all the factors are found (i.e. we end up with 1 or 0).
[edit] Cheer up, it could be worse
An important result in complexity theory is no matter how hard a problem can get (i.e. how much time and space it needs) there will always be a harder problem. The time hierarchy theorem proves this, from which the similar space hierarchy theorem can be derived.
[edit] Resources
Complexity theory analyzes the difficulty of computational problems in terms of many different computational resources. A problem can be described in terms of many requirements it makes on resources: time, space, randomness, alternation, and other less-intuitive measures[vague]. A complexity class is the class of all problems which can be solved using a certain amount of a certain computational resource.
There are other measures of computational complexity. For instance, communication complexity is a measure of complexity for distributed computations.
A different measure of problem complexity, which is useful in some cases, is circuit complexity. This is a measure of the size of a boolean circuit needed to compute the answer to a problem, in terms of the number of logic gates required to build the circuit. Such a measure is useful, for example, when designing hardware microchips to compute the function instead of software.
Perhaps the most studied computational resources are for determinism in time or space. These resources represent the amount of time or space needed by a deterministic computer. These resources are of great practical interest, and are well-studied.
Some computational problems are easier to analyze in terms of more unusual resources. For example, a nondeterministic Turing machine is a computational model that is allowed to branch out to check many different possibilities at once. The nondeterministic Turing machine has very little to do with how we physically want to compute algorithms, but its branching exactly captures many of the mathematical models we want to analyze, so that nondeterministic time is a very important resource in analyzing computational problems.
Many more unusual computational resources have been used in complexity theory. Technically, any complexity measure can be viewed as a computational resource, and complexity measures are very broadly defined by the Blum complexity axioms.
[edit] Complexity classes
A complexity class is the class of all of the computational problems which can be solved using a certain amount of a certain computational resource.
The complexity class P is the class of decision problems that can be solved by a deterministic machine in polynomial time. This class corresponds to an intuitive idea of the problems which can be effectively solved in the worst cases.[10]
The complexity class NP is the set of decision problems that can be solved by a non-deterministic Turing machine in polynomial time. This class contains many problems that people would like to be able to solve effectively, including the Boolean satisfiability problem, the Hamiltonian path problem and the vertex cover problem. All the problems in this class have the property that their solutions can be checked efficiently.[10]
Many complexity classes can be characterized in terms of the mathematical logic needed to express them – this field is called descriptive complexity.
[edit] NP completeness and other open questions
[edit] P = NP
The question of whether NP = P (can problems that can be solved in non-deterministic polynomial time also always be solved in deterministic polynomial time?) is one of the most important open questions in theoretical computer science because of the wide implications of a solution.[10] If the answer is yes, many important problems can be shown to have more efficient solutions that are now used with reluctance because of unknown edge cases. These include various types of integer programming in operations research, many problems in logistics, protein structure prediction in biology, and the ability to find formal proofs of pure mathematics theorems.[11][12]
The P = NP problem is one of the Millennium Prize Problems proposed by the Clay Mathematics Institute the solution of which is a US$1,000,000 prize for the first person to provide a solution.[13]
Questions like this motivate the concepts of hard and complete
[edit] Hard
A class of problems X is hard for a class of problems Y if every problem in Y can be transformed "easily" (that is to say, it may take a lot of effort but the person solving the problem knows a solution exists) into some problem in X that produces the same solution. The definition of "hard" (or rather "easy") problems differs by context. For P = NP, "hard" means NP-hard— a class of problems that are not necessarily in NP themselves, but to which any they can be reduced to an NP problem in polynomial time.
[edit] Complete
The class X is complete for Y if it is hard for Y and is also a subset of of it.
Thus, the class of NP-complete problems contains the most "difficult" problems in NP, in the sense that they are the ones most likely not to be in P. Because the problem P = NP is not solved, being able to reduce another problem to a known NP-complete problem would indicate that there is no known polynomial-time solution for it.[why?] Similarly, because all NP problems can be reduced to the set, finding an NP-complete problem that can be solved in polynomial time would mean that P = NP.[10]
[edit] Incomplete
Incomplete problems are those in NP that are neither NP-complete nor in P. In other words, incomplete problems can neither be solved in polynomial time nor are they hard problems.
It has been shown[citation needed] that if P = NP is found false then there exist NP-incomplete problems.[14][15]
[edit] Graph isomorphism
An important unsolved problem in this context is, whether the graph isomorphism problem is in P, NP-complete, or NP-incomplete. The answer is not known, but there are strong hints that the problem is at least not NP-complete.[16] The graph isomorphism problem asks whether two given graphs are isomorphic.
[edit] The NP=co-NP problem
co-NP is the class containing the complement problems (i.e. problems with the yes/no answers reversed) of NP problems. It is believed[who?] that the two classes are not equal; however, it has not yet been proven. It has been shown[15] that if these two complexity classes are not equal no NP-complete problem can be in co-NP and no co-NP-complete problem can be in NP.
Every problem in P is also in both NP and co-NP. Integer factorization is an example of a problem in both NP and co-NP that is not known to be in P.
[edit] Intractability
Problems that can be solved but not fast enough for the solution to be useful are called intractable[17]). Naive complexity theory assumes problems that lack polynomial-time solutions are intractable for more than the smallest inputs. Problems that are known to be intractable in this sense include those that are EXPTIME-complete. If NP is not the same as P, then the NP-complete problems are also intractable in this sense. What this means in practice is open to debate.
To see why exponential-time solutions might be unusable in practice, consider a problem that requires O(2n) operations to solve. For small n, say 100, and to assume for the sake of example the computer does 1012 operations each second, a solution would take about 4 * 1010 years, which is roughly the age of the universe. On the other hand, a problem that requires n15 operations would be in P, yet a solution would also take about the same time. And a problem that required 2n / 1000000[vague] operations would not be in P, but would be solvable for quite large cases.
[edit] Practice
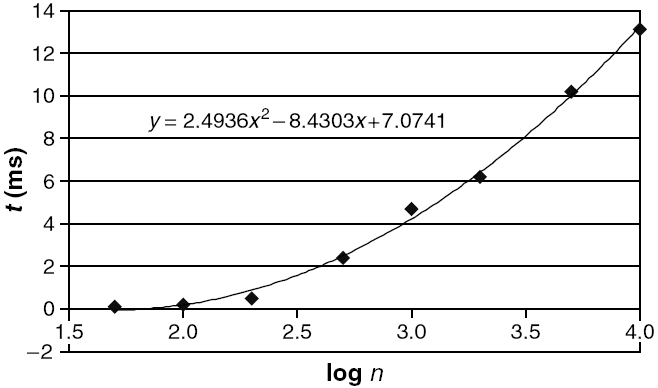
Saying that a problem is not in P does not imply that all large cases of the problem are hard or even that most of them are. For example the decision problem in Presburger arithmetic has been shown not to be in P, yet algorithms have been written that solve the problem in reasonable times in most cases. Similarly, algorithms can solve the NP-complete knapsack problem over a wide range of sizes in less than quadratic time (see graph).
[edit] See also
- Algorithmic efficiency - discusses practical methods for improving an algorithms efficiency
- Amortized analysis
- Complexity
- Cyclomatic complexity
- Game complexity
- List of computability and complexity topics
- List of important publications in computational complexity theory
- List of open problems in computational complexity theory
- Parameterized Complexity
- Performance analysis - the measurement of an algorithms performance at run-time
- The Complexity of Songs
- Run-time analysis - discusses estimated run-time by analyzing the algorithm
[edit] References
- ^ Trahtenbrot (1956).
- ^ Trahtenbrot (1967).
- ^ Rabin, M. O. (1959). "Speed of Computation of Functions and Classification of Recursive Sets".: 1–2, Proc. 3rd Conference of Scientific Societies.
- ^ Rabin, M. O. (1960), Tech. Report 2, Degree of Difficulty of Computing a Function and a Partial Ordering of Recursive Sets, Jerusalem: Hebrew University, Jerusalem
- ^ Rabin, M. O. (1963). Real-time computation. Israel Journal of Math. pp. 203-211., Hartmanis, Lewis and Stearns
- ^ Hartmanis and Stearns (1964)
- ^ a b Hartmanis and Stearns (1965)
- ^ Aho, Hopcroft and Ullman (1976)
- ^ Agrawal, Manindra; Kayal, Neeraj; Saxena, Nitin, "PRIMES is in P", Annals of Mathematics, 160 (2004), 781–793
- ^ a b c d Sipser, Michael (2006). "Time Complexity". Introduction to the Theory of Computation (2nd edition ed.). USA: Thomson Course Technology. ISBN 0534950973.
- ^ Berger, Bonnie A.; Leighton, Terrance (1998). "Protein folding in the hydrophobic-hydrophilic (HP) model is NP-complete". Journal of Computational Biology 5 (1): p27–40. PMID 9541869.
- ^ Cook, Stephen (April 2000). The P versus NP Problem. Clay Mathematics Institute. http://www.claymath.org/millennium/P_vs_NP/Official_Problem_Description.pdf. Retrieved on 2006-10-18.
- ^ Jaffe, Arthur M. (2006). "The Millennium Grand Challenge in Mathematics". Notices of the AMS 53 (6). http://www.ams.org/notices/200606/fea-jaffe.pdf. Retrieved on 2006-10-18.
- ^ a b Ladner, Richard E. (1975). "On the structure of polynomial time reducibility" (PDF). Journal of the ACM (JACM) 22 (1): 151–171. doi:. http://delivery.acm.org/10.1145/330000/321877/p155-ladner.pdf?key1=321877&key2=7146531911&coll=&dl=ACM&CFID=15151515&CFTOKEN=6184618.
- ^ a b Du, Ding-Zhu; Ko, Ker-I (2000). Theory of Computational Complexity. John Wiley & Sons. ISBN 978-0-471-34506-0.
- ^ Arvind, Vikraman; Kurur, Piyush P. (2006), "Graph isomorphism is in SPP", Information and Computation 204 (5): 835–852, doi:
- ^ Hopcroft, et al (2007), p. 368
- ^ Pisinger, D. 2003. "Where are the hard knapsack problems?" Technical Report 2003/08, Department of Computer Science, University of Copenhagen, Copenhagen, Denmark
[edit] Further reading
- Aho, A.V., Hopcroft, J.E., and Ullman, J.D. (1976) The Design and Analysis of Computer Algorithms, Reading, Mass., Addison-Wesley P.C.
- Arora, Sanjeev; Barak, Boaz, "Complexity Theory: A Modern Approach", Cambridge University Press, March 2009.
- Blum, Manuel (1967) On the Size of Machines, Information and Control, v. 11, pp. 257–265
- Blum M. (1967) A Machine-independent Theory of Complexity of Recursive Functions, Journal of the ACM, v. 14, No.2, pp. 322–336
- Downey R. and M. Fellows (1999) Parameterized Complexity, Springer-Verlag.
- Fortnow, Lance; Homer, Steve, (2002/2003). A Short History of Computational Complexity. In D. van Dalen, J. Dawson, and A. Kanamori, editors, The History of Mathematical Logic. North-Holland, Amsterdam.
- Hartmanis, J., Lewis, P.M., and Stearns, R.E. (1965) Classification of computations by time and memory requirements, Proc. IfiP Congress 65, pp. 31–35
- Hartmanis, J., and Stearns, R.E. (1964) Computational Complexity of Recursive Sequences, IEEE Proc. 5th Annual Symp. on Switching Circuit Theory and Logical Design, pp. 82–90
- Hartmanis, J., and Stearns, R.E. (1965) On the Computational Complexity of Algorithms, Transactions American Mathematical Society, No. 5, pp. 285–306
- Hopcroft, J.E., Motwani, R. and Ullman, J.D. (2007) Introduction to Automata Theory, Languages, and Computation, Addison Wesley, Boston/San Francisco/New York
- van Leeuwen, Jan, (ed.) Handbook of Theoretical Computer Science, Volume A: Algorithms and Complexity, The MIT Press/Elsevier, 1990. ISBN 978-0-444-88071-0 (Volume A). QA 76.H279 1990. Huge compendium of information, 1000s of references in the various articles.
- Mertens, Stephan, "Computational Complexity for Physicists", Computing in Science & Engineering, vol. 4, no. 3, May/June 2002, pp 31–47
- Trahtenbrot, B.A. (1956) Signalizing Functions and Table Operators, Research Notices of the Pensa Pedagogical Institute, v. 4, pp. 75–87 (in Russian)
- Trahtenbrot, B.A. Complexity of Algorithms and Computations, NGU, Novosibirsk, 1967 (in Russian)
- Wilf, Herbert S., Algorithms and Complexity, Englewood Cliffs, N.J. : Prentice-Hall, 1986. ISBN 0130219738
[edit] External links
|
|||||

