Conditional probability
From Wikipedia, the free encyclopedia
|
|
This article is missing citations or needs footnotes. Please help add inline citations to guard against copyright violations and factual inaccuracies. (December 2007) |
Conditional probability is the probability of some event A, given the occurrence of some other event B. Conditional probability is written P(A|B), and is read "the probability of A, given B".
Joint probability is the probability of two events in conjunction. That is, it is the probability of both events together. The joint probability of A and B is written 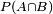 or
or 
Marginal probability is then the unconditional probability P(A) of the event A; that is, the probability of A, regardless of whether event B did or did not occur. If B can be thought of as the event of a random variable X having a given outcome, the marginal probability of A can be obtained by summing (or integrating, more generally) the joint probabilities over all outcomes for X. For example, if there are two possible outcomes for X with corresponding events B and B', this means that 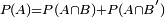 . This is called marginalization.
. This is called marginalization.
In these definitions, note that there need not be a causal or temporal relation between A and B. A may precede B or vice versa or they may happen at the same time. A may cause B or vice versa or they may have no causal relation at all. Notice, however, that causal and temporal relations are informal notions, not belonging to the probabilistic framework. They may apply in some examples, depending on the interpretation given to events.
Conditioning of probabilities, i.e. updating them to take account of (possibly new) information, may be achieved through Bayes' theorem. In such conditioning, the probability of A given only initial information I, P(A|I), is known as the prior probability. The updated conditional probability of A, given I and the outcome of the event B, is known as the posterior probability, P(A|B,I).
Contents |
[edit] Introduction
Consider the simple scenario of rolling two fair six-sided dice, labelled die 1 and die 2. Define the following three events:
- A: Dice 1 lands on 3.
- B: Dice 2 lands on 1.
- C: The dice sum to 8.
The prior probability of each event describes how likely the outcome is before the dice are rolled, without any knowledge of the roll's outcome. For example, die 1 is equally likely to fall on each of its 6 sides, so P(A) = 1/6. Similarly P(B) = 1/6. Likewise, of the 6 × 6 = 36 possible ways that a pair of dice can land, just 5 result in a sum of 8 (namely 2 and 6, 3 and 5, 4 and 4, 5 and 3, and 6 and 2), so P(C) = 5/36.
Some of these events can both occur at the same time; for example events A and C can happen at the same time, in the case where die 1 lands on 3 and die 2 lands on 5. This is the only one of the 36 outcomes where both A and C occur, so its probability is 1/36. The probability of both A and C occurring is called the joint probability of A and C and is written 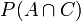 , so
, so 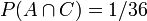 . On the other hand, if die 2 lands on 1, the dice cannot sum to 8, so
. On the other hand, if die 2 lands on 1, the dice cannot sum to 8, so 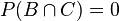 .
.
Now suppose we roll the dice and cover up die 2, so we can only see die 1, and observe that die 1 landed on 3. Given this partial information, the probability that the dice sum to 8 is no longer 5/36; instead it is 1/6, since die 2 must land on 5 to achieve this result. This is called the conditional probability, because it is the probability of C under the condition that A is observed, and is written P(C | A), which is read "the probability of C given A." Similarly, P(C | B) = 0, since if we observe die 2 landed on 1, we already know the dice can't sum to 8, regardless of what the other die landed on.
On the other hand, if we roll the dice and cover up die 2, and observe die 1, this has no impact on the probability of event B, which only depends on die 2. We say events A and B are statistically independent or just independent and in this case
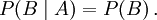
In other words, the probability of B occurring after observing that die 1 landed on 3 is the same as before we observed die 1.
Intersection events and conditional events are related by the formula:

In this example, we have:
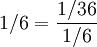
As noted above,  , so by this formula:
, so by this formula:

On multiplying across by P(A),
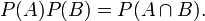
In other words, if two events are independent, their joint probability is the product of the prior probabilities of each event occurring by itself.
[edit] Definition
Given a probability space  and two events
and two events  with P(B) > 0, the conditional probability of A given B is defined by
with P(B) > 0, the conditional probability of A given B is defined by
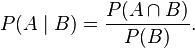
If P(B) = 0 then 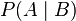 is undefined (see Borel–Kolmogorov paradox for an explanation). However it is possible to define a conditional probability with respect to a σ-algebra of such events (such as those arising from a continuous random variable). See conditional expectation for more information.
is undefined (see Borel–Kolmogorov paradox for an explanation). However it is possible to define a conditional probability with respect to a σ-algebra of such events (such as those arising from a continuous random variable). See conditional expectation for more information.
[edit] Derivation
The following derivation is taken from Grinstead and Snell's Introduction to Probability.[1]
Let  be the original sample space, with elementary outcomes or elementary events ωi, and the probability operation P given as
be the original sample space, with elementary outcomes or elementary events ωi, and the probability operation P given as ![P: \Omega \rightarrow [0,1]](http://upload.wikimedia.org/math/5/8/7/587475e4ab42d2244fa029093062b5f8.png) , for example
, for example ![P(\omega_i) \in [0,1]](http://upload.wikimedia.org/math/8/0/4/804cc1959083e56d849d3779297b77c3.png) .
.
Suppose event 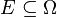 has occurred and an altered probability P(ωi | E) is to be assigned to the elementary events to reflect the fact that E has occurred.
has occurred and an altered probability P(ωi | E) is to be assigned to the elementary events to reflect the fact that E has occurred.
For all  we want to make sure that the intuitive result P(ωj | E) = 0 is true.
we want to make sure that the intuitive result P(ωj | E) = 0 is true.
Also, without further information provided, we can be certain that the relative magnitude of probabilities is conserved:
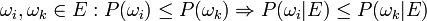 .
.
This requirement leads us to state:

where  , i.e. α is a positive constant or scaling factor to reflect the above requirement.
, i.e. α is a positive constant or scaling factor to reflect the above requirement.
Since we know E has occurred, we can state
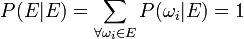
which allows us to say:
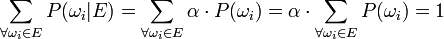
From the above we obtain:

This leads us to state the following:
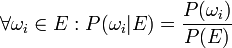
Now for an event  and since
and since  :
:
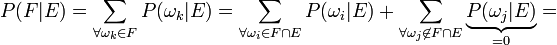

[edit] Statistical independence
Two random events A and B are statistically independent if and only if

Thus, if A and B are independent, then their joint probability can be expressed as a simple product of their individual probabilities.
Equivalently, for two independent events A and B with non-zero probabilities,

and

In other words, if A and B are independent, then the conditional probability of A, given B is simply the individual probability of A alone; likewise, the probability of B given A is simply the probability of B alone.
[edit] Mutual exclusivity
Two events A and B are mutually exclusive if and only if 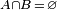 . Then
. Then 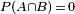 .
.
Therefore, if P(B) > 0 then  is defined and equal to 0.
is defined and equal to 0.
[edit] The conditional probability fallacy
The conditional probability fallacy is the assumption that P(A|B) is approximately equal to P(B|A). The mathematician John Allen Paulos discusses this in his book Innumeracy (p. 63 et seq.), where he points out that it is a mistake often made even by doctors, lawyers, and other highly educated non-statisticians. It can be overcome by describing the data in actual numbers rather than probabilities.
The relation between P(A|B) and P(B|A) is given by Bayes' theorem:

In other words, one can only assume that P(A|B) is approximately equal to P(B|A) if the prior probabilities P(A) and P(B) are also approximately equal.
[edit] An example
In the following constructed but realistic situation, the difference between P(A|B) and P(B|A) may be surprising, but is at the same time obvious.
In order to identify individuals having a serious disease in an early curable form, one may consider screening a large group of people. While the benefits are obvious, an argument against such screenings is the disturbance caused by false positive screening results: If a person not having the disease is incorrectly found to have it by the initial test, they will most likely be quite distressed until a more careful test shows that they do not have the disease. Even after being told they are well, their lives may be affected negatively.
The magnitude of this problem is best understood in terms of conditional probabilities.
Suppose 1% of the group suffer from the disease, and the rest are well. Choosing an individual at random,
- P(ill) = 1% = 0.01 and P(well) = 99% = 0.99.
Suppose that when the screening test is applied to a person not having the disease, there is a 1% chance of getting a false positive result, i.e.
- P(positive | well) = 1%, and P(negative | well) = 99%.
Finally, suppose that when the test is applied to a person having the disease, there is a 1% chance of a false negative result, i.e.
- P(negative | ill) = 1% and P(positive | ill) = 99%.
Now, one may calculate the following:
The fraction of individuals in the whole group who are well and test negative:

The fraction of individuals in the whole group who are ill and test positive:
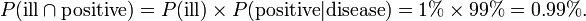
The fraction of individuals in the whole group who have false positive results:

The fraction of individuals in the whole group who have false negative results:

Furthermore, the fraction of individuals in the whole group who test positive:
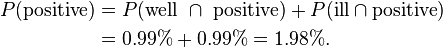
Finally, the probability that an individual actually has the disease, given that the test result is positive:
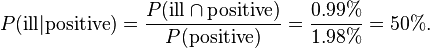
In this example, it should be easy to relate to the difference between the conditional probabilities P(positive | ill) (which is 99%) and P(ill | positive) (which is 50%): the first is the probability that an individual who has the disease tests positive; the second is the probability that an individual who tests positive actually has the disease. With the numbers chosen here, the last result is likely to be deemed unacceptable: half the people testing positive are actually false positives.
[edit] Second type of conditional probability fallacy
Another type of fallacy is interpreting conditional probabilities of events (or a series of events) as (unconditional) probabilities, or seeing them as being in the same order of magnitude. A conditional probability of an event and its (total) probability are linked with each other through the formula of total probability, but without additional information one of them says little about the other. The fallacy to view P(A|B) as P(A) or as being close to P(A) is often related with some forms of statistical bias but it can be subtle.
Here is an example: One of the conditions for the legendary wild-west hero Wyatt Earp to have become a legend was having survived all the duels he survived. Indeed, it is reported that he was never wounded, not even scratched by a bullet. The probability of this to happen is very small, contributing to his fame because events of very small probabilities attract attention. However, the point is that the degree of attention depends very much on the observer. Somebody impressed by a specific event (here seeing a "hero") is prone to view effects of randomness differently from others which are less impressed.
In general makes not much sense to ask after observation of a remarkable series of events "What is the probability of this?", because this is a conditional probability upon observation. The distinction between conditional and unconditional probabilities can be intricate if the observer who asks "What is the probability?" is himself/herself outcome of a random selection. The name "Wyatt Earp effect" was coined in an article "Der Wyatt Earp Effekt" (in German) showing through several examples its subtlety and impact in various scientific domains.
[edit] Conditioning on a random variable
There is also a concept of the conditional probability of an event given a discrete random variable. Such a conditional probability is a random variable in its own right.
Suppose X is a random variable that can be equal either to 0 or to 1. As above, one may speak of the conditional probability of any event A given the event X = 0, and also of the conditional probability of A given the event X = 1. The former is denoted P(A|X = 0) and the latter P(A|X = 1). Now define a new random variable Y, whose value is P(A|X = 0) if X = 0 and P(A|X = 1) if X = 1. That is

This new random variable Y is said to be the conditional probability of the event A given the discrete random variable X:

According to the "law of total probability", the expected value of Y is just the marginal (or "unconditional") probability of A.
More generally still, it is possible to speak of the conditional probability of an event given a sigma-algebra. See conditional expectation.
[edit] See also
- Likelihood function
- Posterior probability
- Probability theory
- Monty Hall problem
- Prosecutor's fallacy
- Conditioning (probability)
- Conditional expectation
- Conditional probability distribution
- Bayes' Theorem
[edit] References
- F. Thomas Bruss Der Wyatt-Earp-Effekt oder die betoerende Macht kleiner Wahrscheinlichkeiten (in German), Spektrum der Wissenschaft (German Edition of Scientific American), Vol 2, 110–113, (2007).

