Precision and recall
From Wikipedia, the free encyclopedia
|
|
It has been suggested that Precision (information retrieval) and Recall (information retrieval) be merged into this article or section. (Discuss) |

Precision and Recall are two widely used statistical classifications.
Precision can be seen as a measure of exactness or fidelity, whereas Recall is a measure of completeness.
In an Information Retrieval scenario, Precision is defined as the number of relevant documents retrieved by a search divided by the total number of documents retrieved by that search, and Recall is defined as the number of relevant documents retrieved by a search divided by the total number of existing relevant documents (which should have been retrieved).
In a statistical classification task, the Precision for a class is the number of true positives (i.e. the number of items correctly labeled as belonging to the class) divided by the total number of elements labeled as belonging to the class (i.e. the sum of true positives and false positives, which are items incorrectly labeled as belonging to the class). Recall in this context is defined as the number of true positives divided by the total number of elements that actually belong to the class (i.e. the sum of true positives and false negatives, which are items which were not labeled as belonging to that class but should have been).
In Information Retrieval, a perfect Precision score of 1.0 means that every result retrieved by a search was relevant (but says nothing about whether all relevant documents were retrieved) whereas a perfect Recall score of 1.0 means that all relevant documents were retrieved by the search (but says nothing about how many irrelevant documents were also retrieved).
In a classification task, a Precision score of 1.0 for a class C means that every item labeled as belonging to class C does indeed belong to class C (but says nothing about the number of items from class C that were not labeled correctly) whereas a Recall of 1.0 means that every item from class C was labeled as belonging to class C (but says nothing about how many other items were incorrectly also labeled as belonging to class C).
Often, there is an inverse relationship between Precision and Recall, where it is possible to increase one at the cost of reducing the other. For example, an information retrieval system (such as a search engine) can often increase its Recall by retrieving more documents, at the cost of increasing number of irrelevant documents retrieved (decreasing Precision). Similarly, a classification system for deciding whether or not, say, a fruit is an orange, can achieve high Precision by only classifying fruits with the exact right shape and color as oranges, but at the cost of low Recall due to the number of false negatives from oranges that did not quite match the specification.
Usually, Precision and Recall scores are not discussed in isolation. Instead, either values for one measure are compared for a fixed level at the other measure (e.g. precision at a recall level of 0.75) or both are combined into a single measure, such as the F-measure, which is the weighted harmonic mean of precision and recall (see below), or the Matthews Correlation Coefficient.
Contents |
[edit] Definition (information retrieval context)
In Information Retrieval contexts, Precision and Recall are defined in terms of a set of retrieved documents (e.g. the list of documents produced by a web search engine for a query) and a set of relevant documents (e.g. the list of all documents on the internet that are relevant for a certain topic).
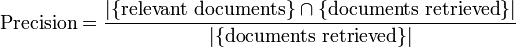
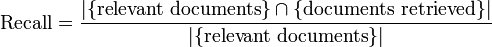
[edit] Definition (classification context)
In the context of classification tasks, the terms true positives, true negatives, false positives and false negatives (see also Type I and type II errors) are used to compare the given classification of an item (the class label assigned to the item by a classifier) with the desired correct classification (the class the item actually belongs to). This is illustrated by the table below:
| correct result / classification | |||
|---|---|---|---|
| E1 | E2 | ||
| obtained result / classification |
E1 | tp (true positive) |
fp (false positive) |
| E2 | fn (false negative) |
tn (true negative) |
|
Precision and Recall are then defined as
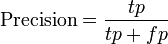

[edit] Probabilistic Interpretation
It is possible to interpret Precision and Recall not as ratios but as probabilities:
- Precision is the probability that a (randomly selected) retrieved document is relevant.
- Recall is the probability that a (randomly selected) relevant document is retrieved in a search.
[edit] F-measure
A popular measure that combines Precision and Recall is the weighted harmonic mean of precision and recall, the traditional F-measure or balanced F-score:

This is also known as the F1 measure, because recall and precision are evenly weighted.
It is a special case of the general Fβ measure (for non-negative real values of β):

Two other commonly used F measures are the F2 measure, which weights recall twice as much as precision, and the F0.5 measure, which weights precision twice as much as recall.
The F-measure was derived by van Rijsbergen (1979) so that Fβ "measures the effectiveness of retrieval with respect to a user who attaches β times as much importance to recall as precision". It is based on van Rijsbergen's effectiveness measure E = 1 − (1 / (α / P + (1 − α) / R)). Their relationship is Fβ = 1 − E where α = 1 / (β2 + 1).
[edit] See also
[edit] Sources
- Makhoul, John; Francis Kubala; Richard Schwartz; Ralph Weischedel: Performance measures for information extraction. In: Proceedings of DARPA Broadcast News Workshop, Herndon, VA, February 1999.
- Baeza-Yates, R.; Ribeiro-Neto, B. (1999). Modern Information Retrieval. New York: ACM Press, Addison-Wesley. Seiten 75 ff. ISBN 0-201-39829-X
- van Rijsbergen, C.V.: Information Retrieval. London; Boston. Butterworth, 2nd Edition 1979. ISBN 0-408-70929-4

