Normal distribution
From Wikipedia, the free encyclopedia
Probability density function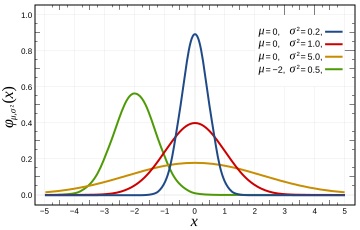 The red line is the standard normal distribution |
|
Cumulative distribution function Colors match the image above |
|
| Parameters | μ location (real) σ2 > 0 squared scale (real) |
|---|---|
| Support |  |
| Probability density function (pdf) |  |
| Cumulative distribution function (cdf) |  |
| Mean | μ |
| Median | μ |
| Mode | μ |
| Variance | σ2 |
| Skewness | 0 |
| Excess kurtosis | 0 |
| Entropy |  |
| Moment-generating function (mgf) |  |
| Characteristic function |  |
In probability theory and statistics, the normal distribution or Gaussian distribution is a continuous probability distribution that describes data that clusters around a mean or average. The graph of the associated probability density function is bell-shaped, with a peak at the mean, and is known as the Gaussian function or bell curve.
The normal distribution can be used to describe, at least approximately, any variable that tends to cluster around the mean. For example, the heights of adult males in the United States are roughly normally distributed, with a mean of about 70 inches. Most men have a height close to the mean, though a small number of outliers have a height significantly above or below the mean. A histogram of male heights will appear similar to a bell curve, with the correspondence becoming closer if more data is used.
For theoretical reasons (such as the central limit theorem), any variable that is the sum of a large number of independent factors is likely to be normally distributed. For this reason, the normal distribution is used throughout statistics, natural science, and social science[1] as a simple model for complex phenomena. For example, the observational error in an experiment is usually assumed to follow a normal distribution, and the propagation of uncertainty is computed using this assumption.
The probability density function for a normal distribution is given by the formula
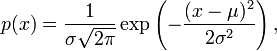
where μ is the mean, σ is the standard deviation (a measure of the “width” of the bell), and exp denotes the exponential function. For a mean of 0 and a standard deviation of 1, this formula simplifies to
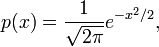
which is known as the standard normal distribution. When properly scaled and translated, the corresponding cumulative distribution function is known as the error function.
The Gaussian distribution is named for Carl Friedrich Gauss, who used it to analyze astronomical data[2], and defined the formula for its probability density function.
Contents |
[edit] History
The normal distribution was first introduced by Abraham de Moivre in an article in the year 1733,[3] which was reprinted in the second edition of his The Doctrine of Chances, 1738 in the context of approximating certain binomial distributions for large n. His result was extended by Laplace in his book Analytical Theory of Probabilities (1812), and is now called the theorem of de Moivre-Laplace.
Laplace used the normal distribution in the analysis of errors of experiments. The important method of least squares was introduced by Legendre in 1805. Gauss, who claimed to have used the method since 1794, justified it rigorously in 1809 by assuming a normal distribution of the errors. The fact the distribution is sometimes called Gaussian is an example of Stigler's Law.
The name "bell curve" goes back to Esprit Jouffret who first used the term "bell surface" in 1872 for a bivariate normal with independent components. The name "normal distribution" was coined independently by Charles S. Peirce, Francis Galton and Wilhelm Lexis around 1875.[citation needed] Despite this terminology, other probability distributions may be more appropriate in some contexts; see the discussion of occurrence, below.
[edit] Characterization
There are various ways to characterize a probability distribution. The most visual is the probability density function (PDF). Equivalent ways are the cumulative distribution function, the moments, the cumulants, the characteristic function, the moment-generating function, the cumulant-generating function, and Maxwell's theorem. See probability distribution for a discussion.
To indicate that a real-valued random variable X is normally distributed with mean μ and variance σ2 ≥ 0, we write

While it is certainly useful for certain limit theorems (e.g. asymptotic normality of estimators) and for the theory of Gaussian processes to consider the probability distribution concentrated at μ (see Dirac measure) as a distribution with mean μ and variance σ2 = 0, this degenerate case is often excluded from the considerations because no density with respect to the Lebesgue measure exists.
The normal distribution may also be parameterized using a precision parameter τ, defined as the reciprocal of σ2. This parameterization has an advantage in numerical applications where σ2 is very close to zero and is more convenient to work with in analysis as τ is a natural parameter of the normal distribution.
[edit] Probability density function
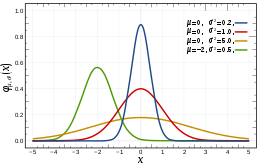
The continuous probability density function of the normal distribution is the Gaussian function

where σ > 0 is the standard deviation, the real parameter μ is the expected value, and
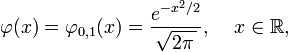
is the density function of the "standard" normal distribution: i.e., the normal distribution with μ = 0 and σ = 1. The integral of 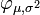 over the real line is equal to one as shown in the Gaussian integral article.
over the real line is equal to one as shown in the Gaussian integral article.
As a Gaussian function with the denominator of the exponent equal to 2, the standard normal density function  is an eigenfunction of the Fourier transform.
is an eigenfunction of the Fourier transform.
The probability density function has notable properties including:
- symmetry about its mean μ
- the mode and median both equal the mean μ
- the inflection points of the curve occur one standard deviation away from the mean, i.e. at μ − σ and μ + σ.
[edit] Cumulative distribution function
The cumulative distribution function (cdf) of a probability distribution, evaluated at a number (lower-case) x, is the probability of the event that a random variable (capital) X with that distribution is less than or equal to x. The cumulative distribution function of the normal distribution is expressed in terms of the density function as follows:

The standard normal cdf is just the general cdf evaluated with μ = 0 and σ = 1:

The standard normal cdf can be expressed in terms of a special function called the error function, as
![\Phi(x)
=\frac{1}{2} \Bigl[ 1 + \operatorname{erf} \Bigl( \frac{x}{\sqrt{2}} \Bigr) \Bigr],
\quad x\in\mathbb{R},](http://upload.wikimedia.org/math/0/0/3/003dabb870f6a1fc0521a85000ea8090.png)
and the cdf itself can hence be expressed as
![\Phi_{\mu,\sigma^2}(x)
=\frac{1}{2} \Bigl[ 1 + \operatorname{erf} \Bigl( \frac{x-\mu}{\sigma\sqrt{2}} \Bigr) \Bigr],
\quad x\in\mathbb{R}.](http://upload.wikimedia.org/math/3/5/3/3537f96b6dfa850f2e6fcb765a03c28c.png)
The complement of the standard normal cdf, 1 − Φ(x), is often denoted Q(x), and is sometimes referred to simply as the Q-function, especially in engineering texts.[4][5] This represents the tail probability of the Gaussian distribution. Other definitions of the Q-function, all of which are simple transformations of Φ, are also used occasionally.[6]
The inverse standard normal cumulative distribution function, or quantile function, can be expressed in terms of the inverse error function:
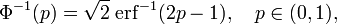
and the inverse cumulative distribution function can hence be expressed as
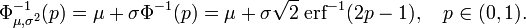
This quantile function is sometimes called the probit function. There is no elementary primitive for the probit function. This is not to say merely that none is known, but rather that the non-existence of such an elementary primitive has been proven. Several accurate methods exist for approximating the quantile function for the normal distribution - see quantile function for a discussion and references.
The values Φ(x) may be approximated very accurately by a variety of methods, such as numerical integration, Taylor series, asymptotic series and continued fractions.
[edit] Strict lower and upper bounds for the cdf
For large x the standard normal cdf 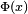 is close to 1 and
is close to 1 and  is close to 0. The elementary bounds
is close to 0. The elementary bounds

in terms of the density  are useful.
are useful.
Using the substitution v = u²/2, the upper bound is derived as follows:

Similarly, using  and the quotient rule,
and the quotient rule,

Solving for  provides the lower bound.
provides the lower bound.
[edit] Generating functions
[edit] Moment generating function
The moment generating function is defined as the expected value of exp(tX). For a normal distribution, the moment generating function is
![\begin{align}
M_X(t) & {} = \mathrm{E} \left[ \exp{(tX)} \right] \\
& {} = \int_{-\infty}^{\infty} \frac{1}{\sigma \sqrt{2\pi} }
\exp{\left( -\frac{(x - \mu)^2}{2 \sigma^2} \right)}
\exp{(tx)} \, dx \\
& {} = \exp{ \left( \mu t + \frac{\sigma^2 t^2}{2} \right)}
\end{align}](http://upload.wikimedia.org/math/e/c/3/ec3e32bd3a987126f3c3b40e239fa768.png)
as can be seen by completing the square in the exponent.
[edit] Cumulant generating function
The cumulant generating function is the logarithm of the moment generating function: g(t) = μt + σ2t2/2. Since this is a quadratic polynomial in t, only the first two cumulants are nonzero.
[edit] Characteristic function
The characteristic function is defined as the expected value of exp(itX), where i is the imaginary unit. So the characteristic function is obtained by replacing t with it in the moment-generating function.
For a normal distribution, the characteristic function is [7]
![\begin{align}
\chi_X(t;\mu,\sigma) &{} = M_X(i t) = \mathrm{E}
\left[ \exp(i t X) \right] \\
&{}=
\int_{-\infty}^{\infty}
\frac{1}{\sigma \sqrt{2\pi}}
\exp
\left(- \frac{(x - \mu)^2}{2\sigma^2}
\right)
\exp(i t x)
\, dx \\
&{}=
\exp
\left(
i \mu t - \frac{\sigma^2 t^2}{2}
\right).
\end{align}](http://upload.wikimedia.org/math/3/7/e/37e8462c5cc0193558226a94aa4f2a03.png)
[edit] Properties
Some properties of the normal distribution:
- If
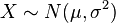 and a and b are real numbers, then
and a and b are real numbers, then 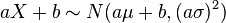 (see expected value and variance).
(see expected value and variance). - If
 and
and 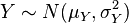 are independent normal random variables, then:
are independent normal random variables, then:
- Their sum is normally distributed with
 (proof). Interestingly, the converse holds: if two independent random variables have a normally-distributed sum, then they must be normal themselves — this is known as Cramér's theorem.
(proof). Interestingly, the converse holds: if two independent random variables have a normally-distributed sum, then they must be normal themselves — this is known as Cramér's theorem. - Their difference is normally distributed with
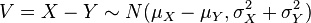 .
. - If the variances of X and Y are equal, then U and V are independent of each other.
- The Kullback-Leibler divergence,

- Their sum is normally distributed with
- If
 and
and 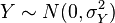 are independent normal random variables, then:
are independent normal random variables, then:
- Their product XY follows a distribution with density p given by
 where K0 is a modified Bessel function of the second kind.
where K0 is a modified Bessel function of the second kind.
- Their ratio follows a Cauchy distribution with
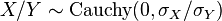 . Thus the Cauchy distribution is a special kind of ratio distribution.
. Thus the Cauchy distribution is a special kind of ratio distribution.
- Their product XY follows a distribution with density p given by
- If
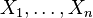 are independent standard normal variables, then
are independent standard normal variables, then 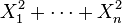 has a chi-square distribution with n degrees of freedom.
has a chi-square distribution with n degrees of freedom. - If are independent standard normal variables, then the sample mean
 and sample variance
and sample variance 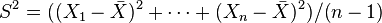 are independent. This property characterizes normal distributions (and helps to explain why the F-test is non-robust with respect to non-normality!)
are independent. This property characterizes normal distributions (and helps to explain why the F-test is non-robust with respect to non-normality!)
[edit] Standardizing normal random variables
As a consequence of Property 1, it is possible to relate all normal random variables to the standard normal.
If X ~ N(μ,σ2), then
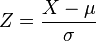
is a standard normal random variable: Z ~ N(0,1). An important consequence is that the cdf of a general normal distribution is therefore
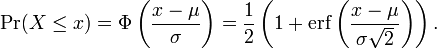
Conversely, if Z is a standard normal distribution, Z ~ N(0,1), then
- X = σZ + μ
is a normal random variable with mean μ and variance σ2.
The standard normal distribution has been tabulated (usually in the form of value of the cumulative distribution function Φ), and the other normal distributions are the simple transformations, as described above, of the standard one. Therefore, one can use tabulated values of the cdf of the standard normal distribution to find values of the cdf of a general normal distribution.
[edit] Moments
The first few moments of the normal distribution are:
| Number | Raw moment | Central moment | Cumulant |
|---|---|---|---|
| 0 | 1 | 1 | |
| 1 | μ | 0 | μ |
| 2 | μ2 + σ2 | σ2 | σ2 |
| 3 | μ3 + 3μσ2 | 0 | 0 |
| 4 | μ4 + 6μ2σ2 + 3σ4 | 3σ4 | 0 |
| 5 | μ5 + 10μ3σ2 + 15μσ4 | 0 | 0 |
| 6 | μ6 + 15μ4σ2 + 45μ2σ4 + 15σ6 | 15σ6 | 0 |
| 7 | μ7 + 21μ5σ2 + 105μ3σ4 + 105μσ6 | 0 | 0 |
| 8 | μ8 + 28μ6σ2 + 210μ4σ4 + 420μ2σ6 + 105σ8 | 105σ8 | 0 |
All cumulants of the normal distribution beyond the second are zero.
Higher central moments (of order 2k) are given by the formula
![E\left[(X-\mu)^{2k}\right]=\frac{(2k)!}{2^k k!} \sigma^{2k}.](http://upload.wikimedia.org/math/c/4/5/c45d4d22ee1da09add1af6a69a6e5d7e.png)
[edit] The central limit theorem
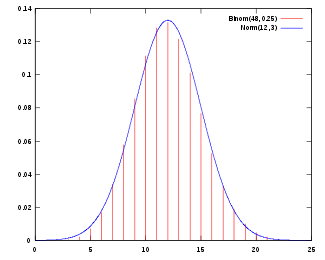
Under certain conditions (such as being independent and identically-distributed with finite variance), the sum of a large number of random variables is approximately normally distributed — this is the central limit theorem.
The practical importance of the central limit theorem is that the normal cumulative distribution function can be used as an approximation to some other cumulative distribution functions, for example:
- A binomial distribution with parameters n and p is approximately normal for large n and p not too close to 1 or 0 (some books recommend using this approximation only if np and n(1 − p) are both at least 5; in this case, a continuity correction should be applied).
The approximating normal distribution has parameters μ = np, σ2 = np(1 − p).
- A Poisson distribution with parameter λ is approximately normal for large λ.
The approximating normal distribution has parameters μ = σ2 = λ.
Whether these approximations are sufficiently accurate depends on the purpose for which they are needed, and the rate of convergence to the normal distribution. It is typically the case that such approximations are less accurate in the tails of the distribution. A general upper bound of the approximation error of the cumulative distribution function is given by the Berry–Esséen theorem.
[edit] Infinite divisibility
The normal distributions are infinitely divisible probability distributions: Given a mean μ, a variance σ 2 ≥ 0, and a natural number n, the sum X1 + . . . + Xn of n independent random variables

has this specified normal distribution (to verify this, use characteristic functions or convolution and mathematical induction).
[edit] Stability
The normal distributions are strictly stable probability distributions.
[edit] Standard deviation and confidence intervals

About 68% of values drawn from a normal distribution are within one standard deviation σ > 0 away from the mean μ; about 95% of the values are within two standard deviations and about 99.7% lie within three standard deviations. This is known as the "68-95-99.7 rule" or the "empirical rule."
To be more precise, the area under the bell curve between μ − nσ and μ + nσ in terms of the cumulative normal distribution function is given by

where erf is the error function. To 12 decimal places, the values for the 1-, 2-, up to 6-sigma points are:
 |
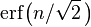 |
|---|---|
| 1 | 0.682689492137 |
| 2 | 0.954499736104 |
| 3 | 0.997300203937 |
| 4 | 0.999936657516 |
| 5 | 0.999999426697 |
| 6 | 0.999999998027 |
The next table gives the reverse relation of sigma multiples corresponding to a few often used values for the area under the bell curve. These values are useful to determine (asymptotic) confidence intervals of the specified levels based on normally distributed (or asymptotically normal) estimators:
 |
|
|---|---|
| 0.80 | 1.28155 |
| 0.90 | 1.64485 |
| 0.95 | 1.95996 |
| 0.98 | 2.32635 |
| 0.99 | 2.57583 |
| 0.995 | 2.80703 |
| 0.998 | 3.09023 |
| 0.999 | 3.29052 |
| 0.9999 | 3.8906 |
| 0.99999 | 4.4172 |
where the value on the left of the table is the proportion of values that will fall within a given interval and n is a multiple of the standard deviation that specifies the width of the interval.
[edit] Exponential family form
The Normal distribution is a two-parameter exponential family form with natural parameters μ and 1/σ2, and natural statistics X and X2. The canonical form has parameters 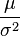 and
and  and sufficient statistics
and sufficient statistics 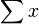 and
and 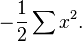
[edit] Complex normal distribution
Consider the complex Gaussian random variable,

where X and Y are real and independent Gaussian variables with equal variances  . The pdf of the joint variables is then
. The pdf of the joint variables is then
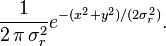
Because  , the resulting pdf for the complex Gaussian variable Z is
, the resulting pdf for the complex Gaussian variable Z is
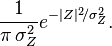
[edit] Related distributions
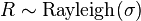 is a Rayleigh distribution if
is a Rayleigh distribution if 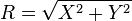 where
where 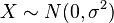 and
and 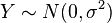 are two independent normal distributions.
are two independent normal distributions. is a chi-square distribution with ν degrees of freedom if
is a chi-square distribution with ν degrees of freedom if  where
where 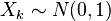 for
for  and are independent.
and are independent.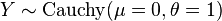 is a Cauchy distribution if Y = X1 / X2 for
is a Cauchy distribution if Y = X1 / X2 for  and
and 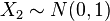 are two independent normal distributions.
are two independent normal distributions.
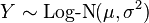 is a log-normal distribution if Y = eX and .
is a log-normal distribution if Y = eX and .
- Relation to stable distribution: if
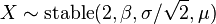 then .
then .
- Truncated normal distribution. If
 then truncating X below at A and above at B will lead to a random variable with mean
then truncating X below at A and above at B will lead to a random variable with mean  where
where 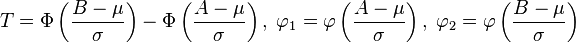 and
and 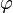 is the probability density function of a standard normal random variable.
is the probability density function of a standard normal random variable.
- If X is a random variable with a normal distribution, and Y = | X | , then Y has a folded normal distribution.
[edit] Descriptive and inferential statistics
[edit] Scores
Many scores are derived from the normal distribution, including percentile ranks ("percentiles" or "quantiles"), normal curve equivalents, stanines, z-scores, and T-scores. Additionally, a number of behavioral statistical procedures are based on the assumption that scores are normally distributed; for example, t-tests and ANOVAs (see below). Bell curve grading assigns relative grades based on a normal distribution of scores.
| This section requires expansion. |
[edit] Normality tests
Normality tests check a given set of data for similarity to the normal distribution. The null hypothesis is that the data set is similar to the normal distribution, therefore a sufficiently small P-value indicates non-normal data.
- Kolmogorov–Smirnov test
- Lilliefors test
- Anderson–Darling test
- Ryan–Joiner test
- Shapiro–Wilk test
- Normal probability plot (rankit plot)
- Jarque–Bera test
- Spiegelhalter's omnibus test
[edit] Estimation of parameters
[edit] Maximum likelihood estimation of parameters
Suppose
are independent and each is normally distributed with expectation μ and variance σ 2 > 0. In the language of statisticians, the observed values of these n random variables make up a "sample of size n from a normally distributed population." It is desired to estimate the "population mean" μ and the "population standard deviation" σ, based on the observed values of this sample. The continuous joint probability density function of these n independent random variables is
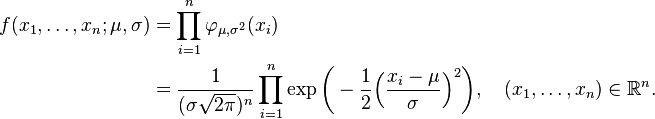
As a function of μ and σ, the likelihood function based on the observations X1, ..., Xn is
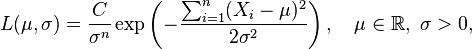
with some constant C > 0 (which in general would be even allowed to depend on X1, ..., Xn, but will vanish anyway when partial derivatives of the log-likelihood function with respect to the parameters are computed, see below).
In the method of maximum likelihood, the values of μ and σ that maximize the likelihood function are taken as estimates of the population parameters μ and σ.
Usually in maximizing a function of two variables, one might consider partial derivatives. But here we will exploit the fact that the value of μ that maximizes the likelihood function with σ fixed does not depend on σ. Therefore, we can find that value of μ, then substitute it for μ in the likelihood function, and finally find the value of σ that maximizes the resulting expression.
It is evident that the likelihood function is a decreasing function of the sum
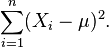
So we want the value of μ that minimizes this sum. Let

be the "sample mean" based on the n observations. Observe that
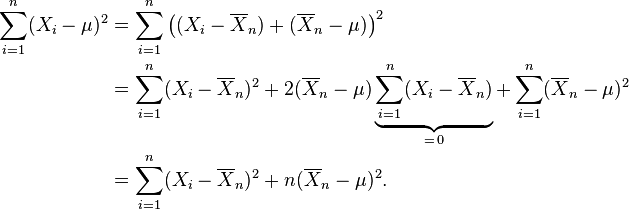
Only the last term depends on μ and it is minimized by

That is the maximum-likelihood estimate of μ based on the n observations X1, ..., Xn. When we substitute that estimate for μ into the likelihood function, we get

It is conventional to denote the "log-likelihood function", i.e., the logarithm of the likelihood function, by a lower-case ℓ, and we have
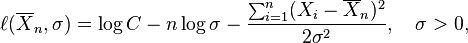
and then
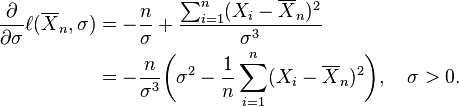
This derivative is positive, zero, or negative according as σ2 is between 0 and

or equal to that quantity, or greater than that quantity. (If there is just one observation, meaning that n = 1, or if X1 = ... = Xn, which only happens with probability zero, then 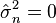 by this formula, reflecting the fact that in these cases the likelihood function is unbounded as σ decreases to zero.)
by this formula, reflecting the fact that in these cases the likelihood function is unbounded as σ decreases to zero.)
Consequently this average of squares of residuals is the maximum-likelihood estimate of σ2, and its square root is the maximum-likelihood estimate of σ based on the n observations. This estimator 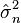 is biased, but has a smaller mean squared error than the usual unbiased estimator, which is n/(n − 1) times this estimator.
is biased, but has a smaller mean squared error than the usual unbiased estimator, which is n/(n − 1) times this estimator.
[edit] Surprising generalization
The derivation of the maximum-likelihood estimator of the covariance matrix of a multivariate normal distribution is subtle. It involves the spectral theorem and the reason it can be better to view a scalar as the trace of a 1×1 matrix than as a mere scalar. See estimation of covariance matrices.
[edit] Unbiased estimation of parameters
The maximum likelihood estimator of the population mean μ from a sample is an unbiased estimator of the mean. The maximum likelihood estimator of the variance is unbiased if we assume the population is known a priori, but in practice that does not happen. However, if we are faced with a sample and have no knowledge of the mean or the variance of the population from which it is drawn, as assumed in the maximum likelihood derivation above, then the maximum likelihood estimator of the variance is biased. An unbiased estimator of the variance σ2 is:

This "sample variance" follows a Gamma distribution if all Xi are independent and identically-distributed:

with mean 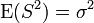 and variance
and variance 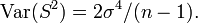
The maximum likelihood estimate of the standard deviation is the square root of the maximum likelihood estimate of the variance. However, neither this nor the square root of the sample variance provides an unbiased estimate for standard deviation: see unbiased estimation of standard deviation for formulae particular to the normal distribution.
[edit] Occurrence
Approximately normal distributions occur in many situations, as explained by the central limit theorem. When there is reason to suspect the presence of a large number of small effects acting additively and independently, it is reasonable to assume that observations will be normal. There are statistical methods to empirically test that assumption, for example the Kolmogorov-Smirnov test.
Effects can also act as multiplicative (rather than additive) modifications. In that case, the assumption of normality is not justified, and it is the logarithm of the variable of interest that is normally distributed. The distribution of the directly observed variable is then called log-normal.
Finally, if there is a single external influence which has a large effect on the variable under consideration, the assumption of normality is not justified either. This is true even if, when the external variable is held constant, the resulting marginal distributions are indeed normal. The full distribution will be a superposition of normal variables, which is not in general normal. This is related to the theory of errors (see below).
To summarize, here is a list of situations where approximate normality is sometimes assumed. For a fuller discussion, see below.
- In counting problems, where the central limit theorem includes a discrete-to-continuum approximation and where infinitely divisible and decomposable distributions are involved, such as
- Binomial random variables, associated with yes/no questions;
- Poisson random variables, associated with rare events;
- In physiological measurements of biological specimens:
- The logarithm of measures of size of living tissue (length, height, skin area, weight);
- The length of inert appendages (hair, claws, nails, teeth) of biological specimens, in the direction of growth; presumably the thickness of tree bark also falls under this category;
- Other physiological measures may be normally distributed, but there is no reason to expect that a priori;
- Measurement errors are often assumed to be normally distributed, and any deviation from normality is considered something which should be explained;
- Financial variables, in the Black–Scholes model
- Changes in the logarithm of exchange rates, price indices, and stock market indices; these variables behave like compound interest, not like simple interest, and so are multiplicative;
- While the Black–Scholes model assumes normality, in reality these variables exhibit heavy tails, as seen in stock market crashes;
- Other financial variables may be normally distributed, but there is no reason to expect that a priori;
- Light intensity
- The intensity of laser light is normally distributed;
- Thermal light has a Bose–Einstein distribution on very short time scales, and a normal distribution on longer timescales due to the central limit theorem.
Of relevance to biology and economics is the fact that complex systems tend to display power laws rather than normality.
[edit] Photon counting
Light intensity from a single source varies with time, as thermal fluctuations can be observed if the light is analyzed at sufficiently high time resolution. Quantum mechanics interprets measurements of light intensity as photon counting, where the natural assumption is to use the Poisson distribution. When light intensity is integrated over large times longer than the coherence time, the Poisson-to-normal approximation is appropriate.
[edit] Measurement errors
Normality is the central assumption of the mathematical theory of errors. Similarly, in statistical model-fitting, an indicator of goodness of fit is that the residuals (as the errors are called in that setting) be independent and normally distributed. The assumption is that any deviation from normality needs to be explained. In that sense, both in model-fitting and in the theory of errors, normality is the only observation that need not be explained, being expected. However, if the original data are not normally distributed (for instance if they follow a Cauchy distribution), then the residuals will also not be normally distributed. This fact is usually ignored in practice.
Repeated measurements of the same quantity are expected to yield results which are clustered around a particular value. If all major sources of errors have been taken into account, it is assumed that the remaining error must be the result of a large number of very small additive effects, and hence normal. Deviations from normality are interpreted as indications of systematic errors which have not been taken into account. Whether this assumption is valid is debatable.
A famous and oft-quoted remark attributed to Gabriel Lippmann says: "Everyone believes in the [normal] law of errors: the mathematicians, because they think it is an experimental fact; and the experimenters, because they suppose it is a theorem of mathematics."[citation needed] Another source may be Henri Poincaré.
[edit] Physical characteristics of biological specimens
The sizes of full-grown animals is approximately lognormal. The evidence and an explanation based on models of growth was first published in the 1932 book Problems of Relative Growth by Julian Huxley.
Differences in size due to sexual dimorphism, or other polymorphisms like the worker/soldier/queen division in social insects, further make the distribution of sizes deviate from lognormality.
The assumption that linear size of biological specimens is normal (rather than lognormal) leads to a non-normal distribution of weight (since weight or volume is roughly proportional to the 2nd or 3rd power of length, and Gaussian distributions are only preserved by linear transformations), and conversely assuming that weight is normal leads to non-normal lengths. This is a problem, because there is no a priori reason why one of length, or body mass, and not the other, should be normally distributed. Lognormal distributions, on the other hand, are preserved by powers so the "problem" goes away if lognormality is assumed.
On the other hand, there are some biological measures where normality is assumed, such as blood pressure of adult humans. This is supposed to be normally distributed, but only after separating males and females into different populations (each of which is normally distributed).
[edit] Financial variables

Already in 1900 Louis Bachelier proposed representing price changes of stocks using the normal distribution. This approach has since been modified slightly. Because of the multiplicative nature of compounding of returns, financial indicators such as stock values and commodity prices exhibit "multiplicative behavior". As such, their periodic changes (e.g., yearly changes) are not normal, but rather lognormal - i.e. logarithmic returns as opposed to values are normally distributed. This is still the most commonly used hypothesis in finance, in particular in option pricing in the Black–Scholes model.
However, in reality financial variables exhibit heavy tails, and thus the assumption of normality understates the probability of extreme events such as stock market crashes. Corrections to this model have been suggested by mathematicians such as Benoît Mandelbrot, who observed that the changes in logarithm over short periods (such as a day) are approximated well by distributions that do not have a finite variance, and therefore the central limit theorem does not apply. Rather, the sum of many such changes gives log-Levy distributions.
[edit] Distribution in testing and intelligence
Sometimes, the difficulty and number of questions on an IQ test is selected in order to yield normal distributed results. Or else, the raw test scores are converted to IQ values by fitting them to the normal distribution. In either case, it is the deliberate result of test construction or score interpretation that leads to IQ scores being normally distributed for the majority of the population. However, the question whether intelligence itself is normally distributed is more involved, because intelligence is a latent variable, therefore its distribution cannot be observed directly.
[edit] Diffusion equation
The probability density function of the normal distribution is closely related to the (homogeneous and isotropic) diffusion equation and therefore also to the heat equation. This partial differential equation describes the time evolution of a mass-density function under diffusion. In particular, the probability density function
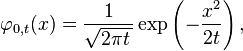
for the normal distribution with expected value 0 and variance t satisfies the diffusion equation:

If the mass-density at time t = 0 is given by a Dirac delta, which essentially means that all mass is initially concentrated in a single point, then the mass-density function at time t will have the form of the normal probability density function with variance linearly growing with t. This connection is no coincidence: diffusion is due to Brownian motion which is mathematically described by a Wiener process, and such a process at time t will also result in a normal distribution with variance linearly growing with t.
More generally, if the initial mass-density is given by a function φ(x), then the mass-density at time t will be given by the convolution of φ and a normal probability density function.
[edit] Use in computational statistics
The normal distribution arises in many areas of statistics. For example, the sampling distribution of the sample mean is approximately normal, even if the distribution of the population from which the sample is taken is not normal. In addition, the normal distribution maximizes information entropy among all distributions with known mean and variance, which makes it the natural choice of underlying distribution for data summarized in terms of sample mean and variance. The normal distribution is the most widely used family of distributions in statistics and many statistical tests are based on the assumption of normality.
[edit] Generating values for normal random variables
For computer simulations, it is often useful to generate values that have a normal distribution. There are several methods and the most basic is to invert the standard normal cdf. More efficient methods are also known, one such method being the Box-Muller transform. An even faster algorithm is the ziggurat algorithm. These are discussed below. A simple approach that is easy to program is as follows. Simply sum 12 uniform (0,1) deviates and subtract 6 (half of 12). This is quite usable in many applications. The sum over these 12 values has an Irwin-Hall distribution; 12 is chosen to give the sum a variance of exactly one. The resulting random deviates are limited to the range (−6, 6) and have a density which is a 12-section eleventh-order polynomial approximation to the normal distribution.[8]
The Box-Muller method says that, if you have two independent random numbers U and V uniformly distributed on (0, 1], (e.g. the output from a random number generator), then two independent standard normally distributed random variables are X and Y, where:


This formulation arises because the chi-square distribution with two degrees of freedom (see property 4 above) is an easily-generated exponential random variable (which corresponds to the quantity lnU in these equations). Thus an angle is chosen uniformly around the circle via the random variable V, a radius is chosen to be exponential and then transformed to (normally distributed) x and y coordinates.
A method that is much faster than the Box-Muller transform but which is still exact is the so-called Ziggurat algorithm developed by George Marsaglia. In about 97% of all cases it uses only two random numbers, one random integer and one random uniform, one multiplication and an if-test. Only in 3% of the cases where the combination of those two falls outside the "core of the ziggurat" a kind of rejection sampling using logarithms, exponentials and more uniform random numbers has to be employed.
There is also some investigation into the connection between the fast Hadamard transform and the normal distribution, since the transform employs just addition and subtraction and by the central limit theorem random numbers from almost any distribution will be transformed into the normal distribution. In this regard a series of Hadamard transforms can be combined with random permutations to turn arbitrary data sets into a normally-distributed data.
[edit] Numerical approximations of the normal distribution and its cdf
The normal distribution function is widely used in scientific and statistical computing. Therefore, it has been implemented in various ways.
The GNU Scientific Library calculates values of the standard normal cdf using piecewise approximations by rational functions. Another approximation method uses third-degree polynomials on intervals.[9] The article on the bc programming language gives an example of how to compute the cdf in Gnu bc.
For a more detailed discussion of how to calculate the normal distribution, see Knuth's The Art of Computer Programming, section 3.4.1C.
[edit] See also
- Behrens–Fisher problem
- Bell curve grading
- Central limit theorem - re-averaged sum of a sufficiently large number of identically distributed independent random variables each with finite mean and variance will be approximately normally distributed
- Chi square distribution
- Data transformation (statistics) - simple techniques to transform data into normal distribution
- Erdős-Kac theorem, on the occurrence of the normal distribution in number theory
- Gaussian blur, convolution using the normal distribution as a kernel
- Gaussian function
- Gaussian process
- Iannis Xenakis, Gaussian distribution in music.
- Inverse Gaussian distribution
- Logistic distribution
- Logit function
- Lognormal distribution
- Multivariate normal distribution
- Matrix normal distribution
- Normal-gamma distribution
- Normally distributed and uncorrelated does not imply independent (an example of two normally distributed uncorrelated random variables that are not independent; this cannot happen in the presence of joint normality)
- Pearson distribution Generalized family of probability distributions that extend the Gaussian distribution to include different skewness and kurtosis values
- Probit function
- Sample size
- Skew normal distribution
- Student's t-distribution
- Sum of normally distributed random variables
- Truncated normal distribution
- Tweedie distributions
[edit] Notes
- ^ Gale Encyclopedia of Psychology - Normal Distribution
- ^ Havil, 2003
- ^ Abraham de Moivre, "Approximatio ad Summam Terminorum Binomii (a + b)n in Seriem expansi" (printed on 12 November 1733 in London for private circulation). This pamphlet has been reprinted in: (1) Richard C. Archibald (1926) “A rare pamphlet of Moivre and some of his discoveries,” Isis, vol. 8, pages 671-683; (2) Helen M. Walker, “De Moivre on the law of normal probability” in David Eugene Smith, A Source Book in Mathematics [New York, New York: McGraw-Hill, 1929; reprinted: New York, New York: Dover, 1959], vol. 2, pages 566-575.; (3) Abraham De Moivre, The Doctrine of Chances (2nd ed.) [London: H. Woodfall, 1738; reprinted: London: Cass, 1967], pages 235-243; (3rd ed.) [London: A Millar, 1756; reprinted: New York, New York: Chelsea, 1967], pages 243-254; (4) Florence N. David, Games, Gods and Gambling: A History of Probability and Statistical Ideas [London: Griffin, 1962], Appendix 5, pages 254-267.
- ^ The Q-function
- ^ http://www.eng.tau.ac.il/~jo/academic/Q.pdf
- ^ Normal Distribution Function - from Wolfram MathWorld
- ^ M.A. Sanders. "Characteristic function of the univariate normal distribution". http://www.planetmathematics.com/CharNormal.pdf. Retrieved on 2009-03-06.
- ^ Johnson NL, Kotz S, Balakrishnan N. (1995) Continuous Univariate Distributions Volume 2, Wiley. Equation(26.48)
- ^ Andy Salter. "B-Spline curves". http://www.doc.ic.ac.uk/~dfg/AndysSplineTutorial/BSplines.html. Retrieved on 2008-12-05.
[edit] References
- John Aldrich. Earliest Uses of Symbols in Probability and Statistics. Electronic document, retrieved March 20, 2005. (See "Symbols associated with the Normal Distribution".)
- Abraham de Moivre (1738). The Doctrine of Chances.
- Stephen Jay Gould (1981). The Mismeasure of Man. First edition. W. W. Norton. ISBN 0-393-01489-4 .
- Havil, 2003. Gamma, Exploring Euler's Constant, Princeton, NJ: Princeton University Press, p. 157.
- R. J. Herrnstein and Charles Murray (1994). The Bell Curve: Intelligence and Class Structure in American Life. Free Press. ISBN 0-02-914673-9 .
- Pierre-Simon Laplace (1812). Analytical Theory of Probabilities.
- Jeff Miller, John Aldrich, et al. Earliest Known Uses of Some of the Words of Mathematics. In particular, the entries for "bell-shaped and bell curve", "normal" (distribution), "Gaussian", and "Error, law of error, theory of errors, etc.". Electronic documents, retrieved December 13, 2005.
- S. M. Stigler (1999). Statistics on the Table, chapter 22. Harvard University Press. (History of the term "normal distribution".)
- Eric W. Weisstein et al. Normal Distribution at MathWorld. Electronic document, retrieved March 20, 2005.
- Marvin Zelen and Norman C. Severo (1964). Probability Functions. Chapter 26 of Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, ed, by Milton Abramowitz and Irene A. Stegun. National Bureau of Standards.
[edit] External links
The normal distribution
- Mathworld: Normal Distribution
- PlanetMath: normal random variable
- Intuitive derivation.
- Is normal distribution due to Karl Gauss? Euler, his family of gamma functions, and place in history of statistics
- Maxwell demons: Simulating probability distributions with functions of propositional calculus
- Visualization of normal distribution
Online results and applications
- Drawing Normal/Bell Curves with JavaScript
- Normal distribution table
- Public Domain Normal Distribution Table
- Distribution Calculator – Calculates probabilities and critical values for normal, t, chi-square and F-distribution.
- Java Applet on Normal Distributions
- Interactive Distribution Modeler (incl. Normal Distribution).
- Free Area Under the Normal Curve Calculator from Daniel Soper's Free Statistics Calculators website.
- Interactive Graph of the Standard Normal Curve Quickly Visualize the one and two-tailed area of the Standard Normal Curve
- Javascript calculator which calculates the probability that a value randomly chosen from a Normal Distribution is greater than, less than or between chosen values
- Standard Normal Distribution Table for the iPhone
Algorithms and approximations
- GNU Scientific Library – Reference Manual – The Gaussian Distribution
- Calculating the Cumulative Normal distribution, C++, VBA, sitmo.com
- An algorithm for computing the inverse normal cumulative distribution function by Peter J. Acklam – has examples for several programming languages
- An Approximation to the Inverse Normal(0, 1) Distribution, gatech.edu
- Handbook of Mathematical Functions: Polynomial and Rational Approximations for P(x) and Z(x), Abramowitz and Stegun
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||

