Lagrange multipliers
From Wikipedia, the free encyclopedia
|
|
It has been suggested that Constrained_optimization_and_Lagrange_multipliers be merged into this article or section. (Discuss) |

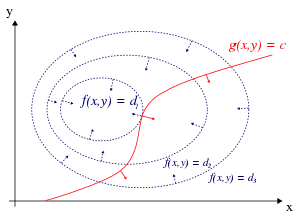
In mathematical optimization, the method of Lagrange multipliers (named after Joseph Louis Lagrange) provides a strategy for finding the maximum/minimum of a function subject to constraints.
For example (see Figure 1 on the right), consider the optimization problem
- maximize
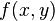
- subject to

We introduce a new variable (λ) called a Lagrange multiplier, and study the Lagrange function defined by

If (x,y) is a maximum for the original constrained problem, then there exists a λ such that (x,y,λ) is a stationary point for the Lagrange function (stationary points are those points where the partial derivatives of Λ are zero). However, not all stationary points yield a solution of the original problem. Thus, the method of Lagrange multipliers yields a necessary condition for optimality in constrained problems.[1]
Contents |
[edit] Introduction
Consider the two-dimensional problem introduced above:
- maximize
- subject to
We can visualize contours of f given by

for various values of d, and the contour of g given by g(x,y) = c.
Suppose we walk along the contour line with g = c. In general the contour lines of f and g may be distinct, so traversing the contour line for g = c could intersect with or cross the contour lines of f. This is equivalent to saying that while moving along the contour line for g = c the value of f can vary. Only when the contour line for g = c intersects contour lines of f tangentially, we do not increase or decrease the value of f — that is, when the contour lines touch but do not cross. A familiar example can be obtained from weather maps, with their contour lines for temperature and pressure: the constrained extrema will occur where the superposed maps show touching lines (isopleths).
The contour lines of f and g touch when the tangent vectors of the contour lines are parallel. Since the gradient of a function is perpendicular to the contour lines, this is the same as saying that the gradients of f and g are parallel. Thus we want points (x,y) where g(x,y) = c and
 ,
,
where
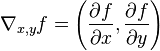
and

is the gradient. The constant λ is required because, even though the directions of both gradient vectors are equal, the magnitudes of the gradient vectors are generally not equal.
To incorporate these conditions into one equation, we introduce an auxiliary function

and solve

This is the method of Lagrange multipliers.
Be aware that the solutions are the stationary points of the Lagrangian Λ; they are not necessarily extrema of Λ. In fact, the function Λ is unbounded: given a point (x,y) that does not lie on the constraint, letting  makes Λ arbitrarily large or small.
makes Λ arbitrarily large or small.
[edit] A more general formulation: The weak Lagrangian principle
Denote the objective function by  and let the constraints be given by
and let the constraints be given by  . The domain of f should be an open set containing all points satisfying the constraints. Furthermore, f and the gk must have continuous first partial derivatives and the gradients of the gk must not be zero on the domain.[2] Now, define the Lagrangian, Λ, as
. The domain of f should be an open set containing all points satisfying the constraints. Furthermore, f and the gk must have continuous first partial derivatives and the gradients of the gk must not be zero on the domain.[2] Now, define the Lagrangian, Λ, as

- k is an index for variables and functions associated with a particular constraint, k.
 without a subscript indicates the vector with elements
without a subscript indicates the vector with elements  , which are taken to be independent variables.
, which are taken to be independent variables.
Observe that both the optimization criteria and constraints gk(x) are compactly encoded as stationary points of the Lagrangian:
 if and only if
if and only if 
 means to take the gradient only with respect to each element in the vector
means to take the gradient only with respect to each element in the vector  , instead of all variables.
, instead of all variables.
and
 implies gk = 0.
implies gk = 0.
Collectively, the stationary points of the Lagrangian,
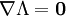 ,
,
give a number of unique equations totaling the length of plus the length of  .
.
The method of Lagrange multipliers is generalized by the Karush–Kuhn–Tucker conditions, which can also take into account inequality constraints of the form h(x) ≤ c.
[edit] Interpretation of the Lagrange multipliers
Often the Lagrange multipliers have an interpretation as some quantity of interest. To see why this might be the case, observe that:
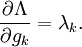
So, λk is the rate of change of the quantity being optimized as a function of the constraint variable. As examples, in Lagrangian mechanics the equations of motion are derived by finding stationary points of the action, the time integral of the difference between kinetic and potential energy. Thus, the force on a particle due to a scalar potential,  , can be interpreted as a Lagrange multiplier determining the change in action (transfer of potential to kinetic energy) following a variation in the particle's constrained trajectory. In economics, the optimal profit to a player is calculated subject to a constrained space of actions, where a Lagrange multiplier is the increase in the value of the objective function due to the relaxation of a given constraint (e.g. through an increase in income or bribery or other means).
, can be interpreted as a Lagrange multiplier determining the change in action (transfer of potential to kinetic energy) following a variation in the particle's constrained trajectory. In economics, the optimal profit to a player is calculated subject to a constrained space of actions, where a Lagrange multiplier is the increase in the value of the objective function due to the relaxation of a given constraint (e.g. through an increase in income or bribery or other means).
[edit] Examples
[edit] Very simple example

Suppose you wish to maximize f(x,y) = x + y subject to the constraint x2 + y2 = 1. The constraint is the unit circle, and the level sets of f are diagonal lines (with slope -1), so one can see graphically that the maximum occurs at  (and the minimum occurs at
(and the minimum occurs at  )
)
Formally, set g(x,y) − c = x2 + y2 − 1, and
- Λ(x,y,λ) = f(x,y) + λ(g(x,y) − c) = x + y + λ(x2 + y2 − 1)
Set the derivative dΛ = 0, which yields the system of equations:
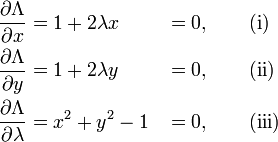
As always, the  equation is the original constraint.
equation is the original constraint.
Combining the first two equations yields x = y (explicitly,  , otherwise (i) yields 1 = 0, so one has x = − 1 / (2λ) = y).
, otherwise (i) yields 1 = 0, so one has x = − 1 / (2λ) = y).
Substituting into (iii) yields 2x2 = 1, so  and the stationary points are and . Evaluating the objective function f on these yields
and the stationary points are and . Evaluating the objective function f on these yields

thus the maximum is 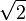 , which is attained at and the minimum is
, which is attained at and the minimum is 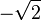 , which is attained at .
, which is attained at .
[edit] Simple example

Suppose you want to find the maximum values for

with the condition that the x and y coordinates lie on the circle around the origin with radius √3, that is,
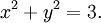
As there is just a single condition, we will use only one multiplier, say λ.
Use the constraint to define a function g(x, y):

The function g(x, y) − c is identically zero on the circle of radius √3. So any multiple of g(x, y) − c may be added to f(x, y) leaving f(x, y) unchanged in the region of interest (above the circle where our original constraint is satisfied). Let

The critical values of Λ occur when its gradient is zero. The partial derivatives are
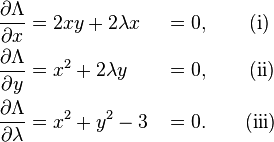
Equation (iii) is just the original constraint. Equation (i) implies x = 0 or λ = −y. In the first case, if x = 0 then we must have  by (iii) and then by (ii) λ = 0. In the second case, if λ = −y and substituting into equation (ii) we have that,
by (iii) and then by (ii) λ = 0. In the second case, if λ = −y and substituting into equation (ii) we have that,

Then x2 = 2y2. Substituting into equation (iii) and solving for y gives this value of y:

Thus there are six critical points:

Evaluating the objective at these points, we find

Therefore, the objective function attains a global maximum (with respect to the constraints) at  and a global minimum at
and a global minimum at  The point
The point  is a local maximum and
is a local maximum and  is a local minimum (since in this case both the values turn out to be zero, so please refer to Hessian Matrices for clarification).
is a local minimum (since in this case both the values turn out to be zero, so please refer to Hessian Matrices for clarification).
[edit] Example: entropy
Suppose we wish to find the discrete probability distribution with maximal information entropy. Then
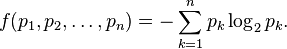
Of course, the sum of these probabilities equals 1, so our constraint is g(p) = 1 with

We can use Lagrange multipliers to find the point of maximum entropy (depending on the probabilities). For all k from 1 to n, we require that
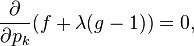
which gives
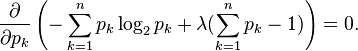
Carrying out the differentiation of these n equations, we get
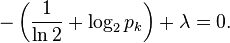
This shows that all pi are equal (because they depend on λ only). By using the constraint ∑k pk = 1, we find

Hence, the uniform distribution is the distribution with the greatest entropy.
[edit] Economics
Constrained optimization plays a central role in economics. For example, the choice problem for a consumer is represented as one of maximizing a utility function subject to a budget constraint. The Lagrange multiplier has an economic interpretation as the shadow price associated with the constraint, in this case the marginal utility of income.
[edit] The strong Lagrangian principle: Lagrange duality
Given a convex optimization problem in standard form

with the domain  having non-empty interior, the Lagrangian function
having non-empty interior, the Lagrangian function  is defined as
is defined as

The vectors λ and ν are called the dual variables or Lagrange multiplier vectors associated with the problem. The Lagrange dual function  is defined as
is defined as

The dual function g is concave, even when the initial problem is not convex. The dual function yields lower bounds on the optimal value p * of the initial problem; for any  and any ν we have
and any ν we have 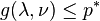 . If a constraint qualification such as Slater's condition holds and the original problem is convex, then we have strong duality, i.e.
. If a constraint qualification such as Slater's condition holds and the original problem is convex, then we have strong duality, i.e. 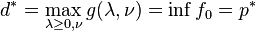 .
.
[edit] See also
| The Wikibook Calculus optimization methods has a page on the topic of |
- Karush–Kuhn–Tucker conditions: generalization of the method of Lagrange multipliers.
- Lagrange multipliers on Banach spaces: another generalization of the method of Lagrange multipliers.
[edit] References
- ^ Vapnyarskii, I.B. (2001), "Lagrange multipliers", in Hazewinkel, Michiel, Encyclopaedia of Mathematics, Kluwer Academic Publishers, ISBN 978-1556080104.
- ^ Gluss, David and Weisstein, Eric W., Lagrange Multiplier at MathWorld.
[edit] External links
Exposition
- Conceptual introduction (plus a brief discussion of Lagrange multipliers in the calculus of variations as used in physics)
- Berkeley Mathematics lecture on Lagrange multipliers
For additional text and interactive applets
- Simple explanation with an example of governments using taxes as Lagrange multipliers
- Applet
- Tutorial and applet
- Video Lecture of Lagrange Multipliers
- Slides accompanying Bertsekas's nonlinear optimization text, with details on Lagrange multipliers (lectures 11 and 12)
- http://eom.springer.de/L/l057190.htm

