Bootstrapping (statistics)
From Wikipedia, the free encyclopedia
|
|
This article includes a list of references or external links, but its sources remain unclear because it lacks inline citations. Please improve this article by introducing more precise citations where appropriate. (March 2009) |
In statistics, bootstrapping is a modern, computer-intensive, general purpose approach to statistical inference, falling within a broader class of resampling methods.
Bootstrapping is the practice of estimating properties of an estimator (such as its variance) by measuring those properties when sampling from an approximating distribution. One standard choice for an approximating distribution is the empirical distribution of the observed data. In the case where a set of observations can be assumed to be from an independent and identically distributed population, this can be implemented by constructing a number of resamples of the observed dataset (and of equal size to the observed dataset), each of which is obtained by random sampling with replacement from the original dataset.
It may also be used for constructing hypothesis tests. It is often used as an alternative to inference based on parametric assumptions when those assumptions are in doubt, or where parametric inference is impossible or requires very complicated formulas for the calculation of standard errors.
The advantage of bootstrapping over analytical methods is its great simplicity - it is straightforward to apply the bootstrap to derive estimates of standard errors and confidence intervals for complex estimators of complex parameters of the distribution, such as percentile points, proportions, odds ratio, and correlation coefficients.
The disadvantage of bootstrapping is that while (under some conditions) it is asymptotically consistent, it does not provide general finite-sample guarantees, and has a tendency to be overly optimistic.[citation needed] The apparent simplicity may conceal the fact that important assumptions are being made when undertaking the bootstrap analysis (e.g. independence of samples) where these would be more formally stated in other approaches.
Contents |
[edit] Informal description
Bootstrapping allows one to gather many alternative versions of the single statistic that would ordinarily be calculated from one sample. For example, assume we are interested in the height of people world wide. As we can not measure all the population, we sample only a small part of it. From that sample only one value of a statistic can be obtained, i.e one mean, or one standard deviation etc., and hence we don't see how variable that statistic is. When using bootstrapping, we randomly extract a new sample of N heights out of the N sampled data, where each person can be selected many times. By doing this several times, we create a large number of datasets that we might have seen and compute the statistic for each of these datasets. Thus we get an estimate of the distribution of the statistic. The key to the strategy is to create alternative versions of data that "we might have seen".
[edit] Example: Fisher's iris data
To introduce the basic ideas and the value of the method, Fisher's famous Iris flower data set will be used, where only the species virginica and versicolor are considered. The analysis was performed in R.
The species can be modeled by logistic regression as a function of sepal length (that is, the other variables available are ignored). Fitting the logistic regression model by maximum likelihood gives the following parameter estimates and their standard errors:
| Estimate | Std. Error | |
|---|---|---|
| Intercept | −12.57 | 2.91 |
| Sepal Length | 2.01 | 0.47 |
It is known that maximum likelihood estimators are asymptotically normally distributed[citation needed]. We can check this assumption using a bootstrap procedure as follows:
- Sample n observations with replacement from the original data, where n is the number of observations.
- Fit the logistic regression model by maximum likelihood.
- Repeat this bootstrap sampling many times (B rounds).
- Use the sampling distribution of the estimates thus computed to be an approximation to the 'true' population sampling distribution.
The plot below contains kernel density plots of the two parameters in the model, as estimated from 10,000 bootstrap samples.

The distributions of the parameter estimates are clearly not normal. That is, the asymptotic assumptions about the maximum likelihood estimates cannot be relied on, and quantities such as confidence intervals and hypothesis tests that rely on those assumptions will be suspect.
One way to estimate confidence intervals from bootstrap samples is to take the α and 1 − α quantiles of the estimated values. These are called bootstrap percentile intervals. In this case, for the intercept and for sepal length, the bootstrap 95% percentile intervals are (-20.02, -7.08) and (1.26, 3.20) respectively. These can be contrasted with the asymptotic intervals derived from the maximum likelihood estimates plus or minus 1.96 standard errors: (-18.26, -6.87) and (1.10, 2.93). The intervals from the asymptotic theory are apparently too narrow (as well as being symmetric).
This simple bootstrap method is not the only way of making improved inferences over the asymptotic approach. Other bootstrap schemes are available, as are approaches based on likelihood or Bayesian considerations. (In fact, the simple bootstrap scheme used here can be quite easily criticized.)
There are more complicated bootstraps for sampling without replacement, two-sample problems, regression, time series, hierarchical sampling, mediation analyses, and other statistical problems.
[edit] How many bootstrap samples are enough?
In the example with Fisher's iris data, 10,000 bootstrap samples were used. However, no explanation was given for this number. It seems that the number of bootstrap samples recommended in the literature has increased as available computing power has increased. Whereas a few years ago, 10,000 samples would have seemed excessive, the above example ran in just a few minutes.
As a general guideline, 1000 samples is often enough for a first look. However, if the results really matter, as many samples as is reasonable given available computing power and time should be used.
[edit] Types of bootstrap scheme
In univariate problems, it is usually acceptable to resample the individual observations with replacement. However, in small samples, a parametric bootstrap approach might be preferred, and for some problems a smooth bootstrap will likely be preferred.
For regression problems, various other alternatives are available.
[edit] Smooth bootstrap
Under this scheme, a small amount of (usually normally distributed) zero-centered random noise is added on to each resampled observation. This is equivalent to sampling from a kernel density estimate of the data.
[edit] Parametric bootstrap
In this case, a parametric model is fit to the data, often by maximum likelihood, and samples of random numbers are drawn from this parametric model. Then, the quantity, or estimate, of interest is calculated from these samples.
[edit] Case resampling
In regression problems, case resampling refers to the simple scheme of resampling individual cases - often rows of a data set. For regression problems, so long as the data set is fairly large, this simple scheme is often acceptable (and this is the method used in the iris example above). However, the method is open to criticism.
In regression problems, the explanatory variables are often fixed, or at least observed with more control than the response variable. Also, the range of the explanatory variables defines the information available from them. Therefore, to resample cases means that each bootstrap sample will lose some information. As such, alternative bootstrap procedures should be considered.
[edit] Resampling residuals
Another approach to bootstrapping in regression problems is to resample residuals. The method proceeds as follows.
- Fit the model and retain the fitted values
 and the residuals
and the residuals  .
. - For each pair, (xi,yi), in which xi is the (possibly multivariate) explanatory variable, add a randomly resampled residual,
 , to the response variable yi. In other words create synthetic response variables
, to the response variable yi. In other words create synthetic response variables  where j is selected randomly from the list
where j is selected randomly from the list  for every i.
for every i. - Refit the model using the fictitious response variables
 , and retain the quantities of interest (often the parameters,
, and retain the quantities of interest (often the parameters,  , estimated from the synthetic ).
, estimated from the synthetic ). - Repeat steps 2 and 3 many, many, times.
This scheme has the advantage that it retains the information in the explanatory variables. However, a question arises as to which residuals to resample. Raw residuals are one option, another is studentized residuals (in linear regression). Whilst there are arguments in favour of using studentized residuals, in practice it often makes little difference and it is easy to run both schemes and compare the results against each other.
[edit] Wild bootstrap
This is the same as resampling residuals but with the additional step that each randomly resampled residual is randomly multiplied by 1 or -1. This method assumes that the 'true' residual distribution is symmetric and can offer advantages over simple residual sampling for smaller sample sizes.
[edit] Choice of statistic - pivoting
In situations where it is essential to extract as much information as possible from a data-set, consideration needs to be given to exactly what estimate or statistic should be the subject of the bootstrapping. Suppose inference is required about the mean of some observations. Then two possibilities are:
- generate bootstrap samples of the sample mean to construct a confidence interval for the mean;
- generate bootstrap samples of the new statistic (mean divided by sample standard deviation), construct a confidence interval for this, then derive the final confidence interval for the mean by multiplying the end-points of the initial interval by the sample standard deviation of the original sample.
The results will be different, and simulations results suggest that the second approach is better. The approach may derive partly from the standard parametric approach for Normal distributions, but is rather more general. The idea is to try to make use of a pivotal quantity, or to find a derived statistic that is approximately pivotal. See also ancillary statistic.
[edit] Example applications
[edit] Application to testing for mediation
Bootstrapping is becoming the most popular method of testing mediation [1] [2] because it does not require the normality assumption to be met, and because it can be effectively utilized with smaller sample sizes (N < 20). However, mediation continues to be (perhaps inappropriately) most frequently determined using (1) the logic of Baron and Kenny [3] or (2) the Sobel test.
[edit] Example: smoothed bootstrap
Newcomb's speed-of-light data are used in the book Bayesian Data Analysis by Gelman et al. and can be found via the classic data sets page. Some analysis of these data appears on the robust statistics page.
The data set contains two obvious outliers so that, as an estimate of location, the median is to be preferred over the mean. Bootstrapping is a method often employed for estimating confidence intervals for medians. However, the median is a discrete statistic, and this fact shows up in the bootstrap distribution.
In order to smooth over the discreteness of the median, we can add a small amount of N(0,σ2) random noise to each bootstrap sample. We choose  for sample size n.
for sample size n.
Histograms of the bootstrap distribution and the smooth bootstrap distribution appear below. The bootstrap distribution is very jagged because there are only a small number of values that the median can take. The smoothed bootstrap distribution overcomes this jaggedness.
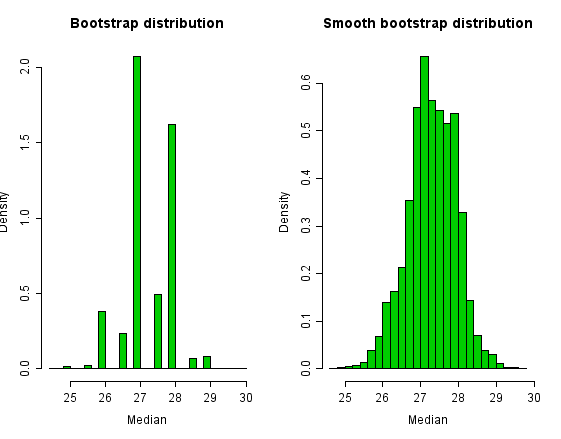
Although the bootstrap distribution of the median looks ugly and intuitively wrong, confidence intervals from it are not bad in this example. The simple 95% percentile interval is (26, 28.5) for the simple bootstrap and (25.98, 28.46) for the smoothed bootstrap.
[edit] Relationship to other resampling methods
The bootstrap is distinguished from :
- the jackknife procedure, used to estimate biases of sample statistics and to estimate variances, and
- cross-validation, used when the outcome of the basic analysis is the result of a search for the best of many possibilities, with the judgement being based on the sample of data available.
For more details see bootstrap resampling.
Bootstrap aggregating (bagging) is a meta-algorithm based on averaging the results of multiple bootstrap samples.
[edit] See also
[edit] References and further reading
- Chernick, Michael R. (1999). Bootstrap Methods, A practitioner's guide. Wiley Series in Probability and Statistics.
- Davison, A. C.; Hinkley, D. Bootstrap Methods and their Applications. (1997). Bootstrap Methods and their Applications. Cambridge: Cambridge Series in Statistical and Probabilistic Mathematics. software.
- Davison, A. C.; Hinkley, D. Bootstrap Methods and their Applications. (2006). Bootstrap Methods and their Applications (8th ed.). Cambridge: Cambridge Series in Statistical and Probabilistic Mathematics.
- Diaconis, P. & Efron, B. (May 1983). "Computer-intensive methods in statistics". Scientific American: 116–130.
- Efron, B. (1979). "Bootstrap Methods: Another Look at the Jackknife". The Annals of Statistics 7 (1): 1–26.
- Efron, B. (1981). "Nonparametric estimates of standard error: The jackknife, the bootstrap and other methods". Biometrika 68: 589–599. doi:.
- Efron, B. (1982). The jackknife, the bootstrap, and other resampling plans. 38. Society of Industrial and Applied Mathematics CBMS-NSF Monographs.
- Efron, B.; Tibshirani, R. (1993). An Introduction to the Bootstrap. Chapman & Hall/CRC. software.
- Edgington, E. S. (1995). Randomization tests. New York: M. Dekker.
- Hesterberg, T. C., D. S. Moore, S. Monaghan, A. Clipson, and R. Epstein (2005): Bootstrap Methods and Permutation Tests, software.
- Mooney, C Z & Duval, R D (1993). Bootstrapping. A Nonparametric Approach to Statistical Inference. Sage University Paper series on Quantitative Applications in the Social Sciences, 07-095. Newbury Park, CA: Sage
- Simon, J. L. (1997): Resampling: The New Statistics.
[edit] External links
- Bootstrap tutorial from ICASSP 99: Tutorial from a signal processing perspective
- Animations for bootstrapping i.i.d data by Yihui Xie using the R
- bootstrapping tutorial
- package animation
- Bootstrap Technology for RAM analysis
- Bootstrap Information Technology and Design of Intelligent Inference Machine
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

