Spearman's rank correlation coefficient
From Wikipedia, the free encyclopedia
In statistics, Spearman's rank correlation coefficient or Spearman's rho, named after Charles Spearman and often denoted by the Greek letter ρ (rho) or as rs, is a non-parametric measure of correlation – that is, it assesses how well an arbitrary monotonic function could describe the relationship between two variables, without making any assumptions about the frequency distribution of the variables.
Contents |
[edit] Calculation
In principle, ρ is simply a special case of the Pearson product-moment coefficient in which two sets of data Xi and Yi are converted to rankings xi and yi before calculating the coefficient.[1] In practice, however, a simpler procedure is normally used to calculate ρ. The raw scores are converted to ranks, and the differences di between the ranks of each observation on the two variables are calculated.
If there are no tied ranks, then ρ is given by:
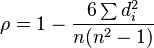
where:
- di = xi − yi = the difference between the ranks of corresponding values Xi and Yi, and
- n = the number of values in each data set (same for both sets).
If tied ranks exist, classic Pearson's correlation coefficient between ranks has to be used instead of this formula:[1]

One has to assign the same rank to each of the equal values. It is an average of their positions in the ascending order of the values:
An example of averaging ranks
In the table below, notice how the rank of values that are the same is the mean of what their ranks would otherwise be.
| Variable Xi | Position in the descending order | Rank xi |
|---|---|---|
| 0.8 | 5 | 5 |
| 1.2 | 4 |  |
| 1.2 | 3 | |
| 2.3 | 2 | 2 |
| 18 | 1 | 1 |
In this case we cannot use the shortcut formula (because of the tied ranks in the data) and must use the second, product-moment form.
[edit] Example
The raw data used in this example is shown below where we want to calculate the correlation between the IQ of someone with the number of hours spent in front of TV per week.
| IQ, Xi | Hours of TV per week, Yi |
| 106 | 7 |
| 86 | 0 |
| 100 | 27 |
| 101 | 50 |
| 99 | 28 |
| 103 | 29 |
| 97 | 20 |
| 113 | 12 |
| 112 | 6 |
| 110 | 17 |
The first step is to sort this data by the second column. Next, two more columns are created (xi and yi). The last of these columns (yi) is assigned 1,2,3,...n, and then the data is sorted by the first original column (Xi). The first of the newly created columns (xi) is assigned 1,2,3,...n. Then a column di is created to hold the differences between the two rank columns (xi and yi). Finally another column 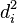 should be created. This is just column di squared.
should be created. This is just column di squared.
After doing this process with the example data you should end up with something like:
| IQ, Xi | Hours of TV per week, Yi | rank xi | rank yi | di | |
| 86 | 0 | 1 | 1 | 0 | 0 |
| 97 | 20 | 2 | 6 | -4 | 16 |
| 99 | 28 | 3 | 8 | -5 | 25 |
| 100 | 27 | 4 | 7 | -3 | 9 |
| 101 | 50 | 5 | 10 | -5 | 25 |
| 103 | 29 | 6 | 9 | -3 | 9 |
| 106 | 7 | 7 | 3 | 4 | 16 |
| 110 | 17 | 8 | 5 | 3 | 9 |
| 112 | 6 | 9 | 2 | 7 | 49 |
| 113 | 12 | 10 | 4 | 6 | 36 |
The values in the column can now be added to find  . The value of n is 10. So these values can now be substituted back into the equation,
. The value of n is 10. So these values can now be substituted back into the equation,
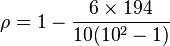
which evaluates to ρ = − 0.175758 which shows that the correlation between IQ and hours spent watching TV is very low (barely any correlation). In the case of ties in the original values, this formula should not be used. Instead, the Pearson correlation coefficient should be calculated on the ranks (where ties are given ranks, as described above).
[edit] Determining significance
The modern approach to testing whether an observed value of ρ is significantly different from zero (we will always have 1 ≥ ρ ≥ −1) is to calculate the probability that it would be greater than or equal to the observed ρ, given the null hypothesis, by using a permutation test. This approach is almost always superior to traditional methods, unless the data set is so large that computing power is not sufficient to generate permutations, or unless an algorithm for creating permutations that are logical under the null hypothesis is difficult to devise for the particular case (but usually these algorithms are straightforward).
Although the permutation test is often trivial to perform for anyone with computing resources and programming experience, traditional methods for determining significance are still widely used. The most basic approach is to compare the observed ρ with published tables for various levels of significance. This is a simple solution if the significance only needs to be known within a certain range or less than a certain value, as long as tables are available that specify the desired ranges. A reference to such a table is given below. However, generating these tables is computationally intensive and complicated mathematical tricks have been used over the years to generate tables for larger and larger sample sizes, so it is not practical for most people to extend existing tables.
An alternative approach available for sufficiently large sample sizes is an approximation to Student's t-distribution with degrees of freedom N-2. For sample sizes above about 20, the variable


has a Student's t-distribution in the null case (zero correlation). In the non-null case (i.e. to test whether an observed ρ is significantly different from a theoretical value, or whether two observed ρs differ significantly) tests are much less powerful, though the t-distribution can again be used.
A generalization of the Spearman coefficient is useful in the situation where there are three or more conditions, a number of subjects are all observed in each of them, and we predict that the observations will have a particular order. For example, a number of subjects might each be given three trials at the same task, and we predict that performance will improve from trial to trial. A test of the significance of the trend between conditions in this situation was developed by E. B. Page and is usually referred to as Page's trend test for ordered alternatives.
[edit] Correspondence analysis based on Spearman's rho
Classic correspondence analysis is a statistical method which gives a score to every value of two nominal variables, in this way that Pearson's correlation coefficient between them is maximized.
There exists an equivalent of this method, called grade correspondence analysis, which maximizes Spearman's rho or Kendall's tau[2].
[edit] See also
- Kendall tau rank correlation coefficient
- Rank correlation
- Chebyshev's sum inequality, rearrangement inequality (These two articles may shed light on the mathematical properties of Spearman's ρ.)
- Pearson product-moment correlation coefficient, a similar correlation method that instead relies on the data being linearly correlated.
[edit] Notes
- ^ a b Myers, Jerome L.; Arnold D. Well (2003). Research Design and Statistical Analysis (second edition ed.). Lawrence Erlbaum. pp. 508. ISBN 0805840370.
- ^ Kowalczyk, T.; Pleszczyńska E. , Ruland F. (eds.) (2004). Grade Models and Methods for Data Analysis with Applications for the Analysis of Data Populations. Studies in Fuzziness and Soft Computing vol. 151. Berlin Heidelberg New York: Springer Verlag. ISBN 9783540211204.
[edit] References
- G.W. Corder, D.I. Foreman, "Nonparametric Statistics for Non-Statisticians: A Step-by-Step Approach", Wiley (2009)
- C. Spearman, "The proof and measurement of association between two things" Amer. J. Psychol. , 15 (1904) pp. 72–101
- M.G. Kendall, "Rank correlation methods" , Griffin (1962)
- M. Hollander, D.A. Wolfe, "Nonparametric statistical methods" , Wiley (1973)
[edit] External links
- Table of critical values of ρ for significance with small samples
- Online calculator
- Chapter 3 part 1 shows the formula to be used when there are ties
- Spearman's rank correlation: Simple notes for students with an example of usage by biologists and a spreadsheet for Microsoft Excel for calculating it (a part of materials for a Research Methods in Biology course).
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||

