Instruction pipeline
From Wikipedia, the free encyclopedia
- Pipelining redirects here. For HTTP pipelining, see HTTP pipelining.
An instruction pipeline is a technique used in the design of computers and other digital electronic devices to increase their instruction throughput (the number of instructions that can be executed in a unit of time).
The fundamental idea is to split the processing of a computer instruction into a series of independent steps, with storage at the end of each step. This allows the computer's control circuitry to issue instructions at the processing rate of the slowest step, which is much faster than the time needed to perform all steps at once. The term pipeline refers to the fact that each step is carrying data at once (like water), and each step is connected to the next (like the links of a pipe.)
The origin of pipelining is thought to be either the ILLIAC II project or the IBM Stretch project. The IBM Stretch Project proposed the terms, "Fetch, Decode, and Execute" that became common usage.
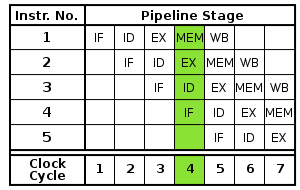
Most modern CPUs are driven by a clock. The CPU consists internally of logic and memory (flip flops). When the clock signal arrives, the flip flops take their new value and the logic then requires a period of time to decode the new values. Then the next clock pulse arrives and the flip flops again take their new values, and so on. By breaking the logic into smaller pieces and inserting flip flops between the pieces of logic, the delay before the logic gives valid outputs is reduced. In this way the clock period can be reduced. For example, the RISC pipeline is broken into five stages with a set of flip flops between each stage.
- Instruction fetch
- Instruction decode and register fetch
- Execute
- Memory access
- Register write back
Hazards: When a programmer (or compiler) writes assembly code, they make the assumption that each instruction is executed before execution of the subsequent instruction is begun. This assumption is invalidated by pipelining. When this causes a program to behave incorrectly, the situation is known as a hazard. Various techniques for resolving hazards such as forwarding and stalling exist.
A non-pipeline architecture is inefficient because some CPU components (modules) are idle while another module is active during the instruction cycle. Pipelining does not completely cancel out idle time in a CPU but making those modules work in parallel improves program execution significantly.
Processors with pipelining are organized inside into stages which can semi-independently work on separate jobs. Each stage is organized and linked into a 'chain' so each stage's output is fed to another stage until the job is done. This organization of the processor allows overall processing time to be significantly reduced.
Unfortunately, not all instructions are independent. In a simple pipeline, completing an instruction may require 5 stages. To operate at full performance, this pipeline will need to run 4 subsequent independent instructions while the first is completing. If 4 instructions that do not depend on the output of the first instruction are not available, the pipeline control logic must insert a stall or wasted clock cycle into the pipeline until the dependency is resolved. Fortunately, techniques such as forwarding can significantly reduce the cases where stalling is required. While pipelining can in theory increase performance over an unpipelined core by a factor of the number of stages (assuming the clock frequency also scales with the number of stages), in reality, most code does not allow for ideal execution.
Contents |
[edit] Advantages and Disadvantages
Pipelining does not help in all cases. There are several possible disadvantages. An instruction pipeline is said to be fully pipelined if it can accept a new instruction every clock cycle. A pipeline that is not fully pipelined has wait cycles that delay the progress of the pipeline.
Advantages of Pipelining:
- The cycle time of the processor is reduced, thus increasing instruction issue-rate in most cases.
- Some combinatorial circuits such as adders or multipliers can be made faster by adding more circuitry. If pipelining is used instead, it can save circuitry vs. a more complex combinatorial circuit.
Disadvantages of Pipelining:
- A non-pipelined processor executes only a single instruction at a time. This prevents branch delays (in effect, every branch is delayed) and problems with serial instructions being executed concurrently. Consequently the design is simpler and cheaper to manufacture.
- The instruction latency in a non-pipelined processor is slightly lower than in a pipelined equivalent. This is due to the fact that extra flip flops must be added to the data path of a pipelined processor.
- A non-pipelined processor will have a stable instruction bandwidth. The performance of a pipelined processor is much harder to predict and may vary more widely between different programs.
[edit] Examples
[edit] Generic pipeline

To the right is a generic pipeline with four stages:
- Fetch
- Decode
- Execute
- Write-back
The top gray box is the list of instructions waiting to be executed; the bottom gray box is the list of instructions that have been completed; and the middle white box is the pipeline.
Execution is as follows:
| Time | Execution |
|---|---|
| 0 | Four instructions are awaiting to be executed |
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 | All instructions are executed |
[edit] Bubble

When a "hiccup" in execution occurs, a "bubble" is created in the pipeline in which nothing useful happens. In cycle 2, the fetching of the purple instruction is delayed and the decoding stage in cycle 3 now contains a bubble. Everything "behind" the purple instruction is delayed as well but everything "ahead" of the purple instruction continues with execution.
Clearly, when compared to the execution above, the bubble yields a total execution time of 8 clock ticks instead of 7.
Bubbles are like stalls, in which nothing useful will happen for the fetch, decode, execute and writeback. It can be completed with a nop code.
[edit] Example 1
A typical instruction to add two numbers might be ADD A, B, C, which adds the values found in memory locations A and B, and then puts the result in memory location C. In a pipelined processor the pipeline controller would break this into a series of tasks similar to:
LOAD A, R1 LOAD B, R2 ADD R1, R2, R3 STORE R3, C LOAD next instruction
The locations 'R1' and 'R2' are registers in the CPU. The values stored in memory locations labeled 'A' and 'B' are loaded (copied) into these registers, then added, and the result is stored in a memory location labeled 'C'.
In this example the pipeline is three stages long- load, execute, and store. Each of the steps are called pipeline stages.
On a non-pipelined processor, only one stage can be working at a time so the entire instruction has to complete before the next instruction can begin. On a pipelined processor, all of the stages can be working at once on different instructions. So when this instruction is at the execute stage, a second instruction will be at the decode stage and a 3rd instruction will be at the fetch stage.
Pipelining doesn't reduce the time it takes to complete an instruction rather it increases the number of instructions that can be processed at once and it reduces the delay between completed instructions- called 'throughput'. The more pipeline stages a processor has, the more instructions it can be working on at once and the less of a delay there is between completed instructions. Every microprocessor manufactured today uses at least 2 stages of pipeline.[citation needed] (The Atmel AVR and the PIC microcontroller each have a 2 stage pipeline). Intel Pentium 4 processors have 20 stage pipelines.
[edit] Example 2
To better visualize the concept, we can look at a theoretical 3-stage pipeline:
| Stage | Description |
|---|---|
| Load | Read instruction from memory |
| Execute | Execute instruction |
| Store | Store result in memory and/or registers |
and a pseudo-code assembly listing to be executed:
LOAD #40, A ; load 40 in A MOVE A, B ; copy A in B ADD #20, B ; add 20 to B STORE B, 0x300 ; store B into memory cell 0x300
This is how it would be executed:
| Load | Execute | Store |
|---|---|---|
| LOAD |
The LOAD instruction is fetched from memory.
| Load | Execute | Store |
|---|---|---|
| MOVE | LOAD |
The LOAD instruction is executed, while the MOVE instruction is fetched from memory.
| Load | Execute | Store |
|---|---|---|
| ADD | MOVE | LOAD |
The LOAD instruction is in the Store stage, where its result (the number 40) will be stored in the register A. In the meantime, the MOVE instruction is being executed. Since it must move the contents of A into B, it must wait for the ending of the LOAD instruction.
| Load | Execute | Store |
|---|---|---|
| STORE | ADD | MOVE |
The STORE instruction is loaded, while the MOVE instruction is finishing off and the ADD is calculating.
And so on. Note that, sometimes, an instruction will depend on the result of another one (like our MOVE example). When more than one instruction references a particular location for an operand, either reading it (as an input) or writing it (as an output), executing those instructions in an order different from the original program order can lead to hazards (mentioned above). There are several established techniques for either preventing hazards from occurring, or working around them if they do.
[edit] Complications
Many designs include pipelines as long as 7, 10 and even 20 stages (like in the Intel Pentium 4) The later "Prescott" and "Cedar Mill" Pentium 4 cores (and their Pentium D derivatives) had a 31-stage pipeline, the longest in mainstream consumer computing. The Xelerator X10q has a pipeline more than a thousand stages long[1] . The downside of a long pipeline is that when a program branches, the processor cannot know where to fetch the next instruction from and must wait until the branch instruction to finish, leaving the pipeline behind it empty. In the extreme case, the performance of a pipelined processor could theoretically approach that of an un-pipelined processor, or even slightly worse if all but one pipeline stages are idle and a small overhead is present between stages. Branch prediction attempts to alleviate this problem by guessing whether the branch will be taken or not and speculatively executing the code path that it predicts will be taken. When its predictions are correct, branch prediction avoids the penalty associated with branching. However, branch prediction itself can end up exacerbating the problem if branches are predicted poorly, as the incorrect code path which has begun execution must be flushed from the pipeline before resuming execution at the correct location.
In certain applications, such as supercomputing, programs are specially written to branch rarely and so very long pipelines are ideal to speed up the computations, as long pipelines are designed to reduce clocks per instruction (CPI). If branching happens constantly, re-ordering branches such that the more likely to be needed instructions are placed into the pipeline can significantly reduce the speed losses associated with having to flush failed branches. Programs such as gcov can be used to examine how often particular branches are actually executed using a technique known as coverage analysis, however such analysis is often a last resort for optimization.
Because of the instruction pipeline, code that the processor loads will not immediately execute. Due to this, updates in the code very near the current location of execution may not take effect because they are already loaded into the Prefetch Input Queue. Instruction caches make this phenomenon even worse. This is only relevant to self-modifying programs.
[edit] See also
[edit] References
[edit] External links
- Branch Prediction in the Pentium Family
- ArsTechnica article on pipelining
- Counterflow Pipeline Processor Architecture
|
||||||||||||||||||||||||||||

