Mathematical model
From Wikipedia, the free encyclopedia
- Note: The term model has a different meaning in model theory, a branch of mathematical logic. An artifact which is used to illustrate a mathematical idea is also called a mathematical model and this usage is the reverse of the sense explained below.
A mathematical model uses mathematical language to describe a system. Mathematical models are used not only in the natural sciences and engineering disciplines (such as physics, biology, earth science, meteorology, and electrical engineering) but also in the social sciences (such as economics, psychology, sociology and political science); physicists, engineers, computer scientists, and economists use mathematical models most extensively.
Eykhoff (1974) defined a mathematical model as 'a representation of the essential aspects of an existing system (or a system to be constructed) which presents knowledge of that system in usable form'.[1]
Mathematical models can take many forms, including but not limited to dynamical systems, statistical models, differential equations, or game theoretic models. These and other types of models can overlap, with a given model involving a variety of abstract structures.
Contents |
[edit] Examples of mathematical models
- Population Growth. A simple (though approximate) model of population growth is the Malthusian growth model. The preferred population growth model is the logistic function.
- Model of a particle in a potential-field. In this model we consider a particle as being a point of mass m which describes a trajectory which is modeled by a function x : R → R3 given its coordinates in space as a function of time. The potential field is given by a function V:R3 → R and the trajectory is a solution of the differential equation
-
- Note this model assumes the particle is a point mass, which is certainly known to be false in many cases we use this model, for example, as a model of planetary motion.
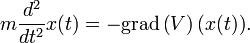
- Model of rational behavior for a consumer. In this model we assume a consumer faces a choice of n commodities labeled 1,2,...,n each with a market price p1, p2,..., pn. The consumer is assumed to have a cardinal utility function U (cardinal in the sense that it assigns numerical values to utilities), depending on the amounts of commodities x1, x2,..., xn consumed. The model further assumes that the consumer has a budget M which she uses to purchase a vector x1, x2,..., xn in such a way as to maximize U(x1, x2,..., xn). The problem of rational behavior in this model then becomes an optimization problem, that is:
-

- subject to:


- This model has been used in general equilibrium theory, particularly to show existence and Pareto optimality of economic equilibria. However, the fact that this particular formulation assigns numerical values to levels of satisfaction is the source of criticism (and even ridicule). However, it is not an essential ingredient of the theory and again this is an idealization.
- Neighbour-sensing model explains the mushroom formation from the initially chaotic fungal network.
Modeling contains selecting and identifying relevant aspects of a situation in real world.
[edit] Background
Often when engineers analyze a system to be controlled or optimized, they use a mathematical model. In analysis, engineers can build a descriptive model of the system as a hypothesis of how the system could work, or try to estimate how an unforeseeable event could affect the system. Similarly, in control of a system, engineers can try out different control approaches in simulations.
A mathematical model usually describes a system by a set of variables and a set of equations that establish relationships between the variables. The values of the variables can be practically anything; real or integer numbers, boolean values or strings, for example. The variables represent some properties of the system, for example, measured system outputs often in the form of signals, timing data, counters, and event occurrence (yes/no). The actual model is the set of functions that describe the relations between the different variables.
[edit] Building blocks
There are six basic groups of variables[citation needed]: decision variables, input variables, state variables, exogenous variables, random variables, and output variables. Since there can be many variables of each type, the variables are generally represented by vectors.
Decision variables are sometimes known as independent variables. Exogenous variables are sometimes known as parameters or constants. The variables are not independent of each other as the state variables are dependent on the decision, input, random, and exogenous variables. Furthermore, the output variables are dependent on the state of the system (represented by the state variables).
Objectives and constraints of the system and its users can be represented as functions of the output variables or state variables. The objective functions will depend on the perspective of the model's user. Depending on the context, an objective function is also known as an index of performance, as it is some measure of interest to the user. Although there is no limit to the number of objective functions and constraints a model can have, using or optimizing the model becomes more involved (computationally).
[edit] Classifying mathematical models
Many mathematical models can be classified in some of the following ways:
- Linear vs. nonlinear: Mathematical models are usually composed by variables, which are abstractions of quantities of interest in the described systems, and operators that act on these variables, which can be algebraic operators, functions, differential operators, etc. If all the operators in a mathematical model present linearity, the resulting mathematical model is defined as linear. A model is considered to be nonlinear otherwise.
The question of linearity and nonlinearity is dependent on context, and linear models may have nonlinear expressions in them. For example, in a statistical linear model, it is assumed that a relationship is linear in the parameters, but it may be nonlinear in the predictor variables. Similarly, a differential equation is said to be linear if it can be written with linear differential operators, but it can still have nonlinear expressions in it. In a mathematical programming model, if the objective functions and constraints are represented entirely by linear equations, then the model is regarded as a linear model. If one or more of the objective functions or constraints are represented with a nonlinear equation, then the model is known as a nonlinear model.
Nonlinearity, even in fairly simple systems, is often associated with phenomena such as chaos and irreversibility. Although there are exceptions, nonlinear systems and models tend to be more difficult to study than linear ones. A common approach to nonlinear problems is linearization, but this can be problematic if one is trying to study aspects such as irreversibility, which are strongly tied to nonlinearity. - Deterministic vs. probabilistic (stochastic): A deterministic model is one in which every set of variable states is uniquely determined by parameters in the model and by sets of previous states of these variables. Therefore, deterministic models perform the same way for a given set of initial conditions. Conversely, in a stochastic model, randomness is present, and variable states are not described by unique values, but rather by probability distributions.
- Static vs. dynamic: A static model does not account for the element of time, while a dynamic model does. Dynamic models typically are represented with difference equations or differential equations.
- Lumped vs. distributed parameters: If the model is homogeneous (consistent state throughout the entire system) the parameters parameters are distributed. If the model is heterogeneous (varying state within the system), then the parameters are lumped. Distributed parameters are typically represented with partial differential equations.
[edit] A priori information
Mathematical modeling problems are often classified into black box or white box models, according to how much a priori information is available of the system. A black-box model is a system of which there is no a priori information available. A white-box model (also called glass box or clear box) is a system where all necessary information is available. Practically all systems are somewhere between the black-box and white-box models, so this concept only works as an intuitive guide for approach.
Usually it is preferable to use as much a priori information as possible to make the model more accurate. Therefore the white-box models are usually considered easier, because if you have used the information correctly, then the model will behave correctly. Often the a priori information comes in forms of knowing the type of functions relating different variables. For example, if we make a model of how a medicine works in a human system, we know that usually the amount of medicine in the blood is an exponentially decaying function. But we are still left with several unknown parameters; how rapidly does the medicine amount decay, and what is the initial amount of medicine in blood? This example is therefore not a completely white-box model. These parameters have to be estimated through some means before one can use the model.
In black-box models one tries to estimate both the functional form of relations between variables and the numerical parameters in those functions. Using a priori information we could end up, for example, with a set of functions that probably could describe the system adequately. If there is no a priori information we would try to use functions as general as possible to cover all different models. An often used approach for black-box models are neural networks which usually do not make assumptions about incoming data. The problem with using a large set of functions to describe a system is that estimating the parameters becomes increasingly difficult when the amount of parameters (and different types of functions) increases.
[edit] Subjective information
Sometimes it is useful to incorporate subjective information into a mathematical model. This can be done based on intuition, experience, or expert opinion, or based on convenience of mathematical form. Bayesian statistics provides a theoretical framework for incorporating such subjectivity into a rigorous analysis: one specifies a prior probability distribution (which can be subjective) and then updates this distribution based on empirical data. An example of when such approach would be necessary is a situation in which an experimenter bends a coin slightly and tosses it once, recording whether it comes up heads, and is then given the task of predicting the probability that the next flip comes up heads. After bending the coin, the true probability that the coin will come up heads is unknown, so the experimenter would need to make an arbitrary decision (perhaps by looking at the shape of the coin) about what prior distribution to use. Incorporation of the subjective information is necessary in this case to get an accurate prediction of the probability, since otherwise one would guess 1 or 0 as the probability of the next flip being heads, which would be almost certainly wrong.[2]
[edit] Complexity
In general, model complexity involves a trade-off between simplicity and accuracy of the model. Occam's Razor is a principle particularly relevant to modeling; the essential idea being that among models with roughly equal predictive power, the simplest one is the most desirable. While added complexity usually improves the fit of a model, it can make the model difficult to understand and work with, and can also pose computational problems, including Numerical instability. Thomas Kuhn argues that as science progresses, explanations tend to become more complex before a Paradigm shift offers radical simplification.
For example, when modeling the flight of an aircraft, we could embed each mechanical part of the aircraft into our model and would thus acquire an almost white-box model of the system. However, the computational cost of adding such a huge amount of detail would effectively inhibit the usage of such a model. Additionally, the uncertainty would increase due to an overly complex system, because each separate part induces some amount of variance into the model. It is therefore usually appropriate to make some approximations to reduce the model to a sensible size. Engineers often can accept some approximations in order to get a more robust and simple model. For example Newton's classical mechanics is an approximated model of the real world. Still, Newton's model is quite sufficient for most ordinary-life situations, that is, as long as particle speeds are well below the speed of light, and we study macro-particles only.
[edit] Training
Any model which is not pure white-box contains some parameters that can be used to fit the model to the system it shall describe. If the modelling is done by a neural network, the optimization of parameters is called training. In more conventional modelling through explicitly given mathematical functions, parameters are determined by curve fitting.
[edit] Model evaluation
A crucial part of the modeling process is the evaluation of whether or not a given mathematical model describes a system accurately. This question can be difficult to answer as it involves several different types of evaluation.
[edit] Fit to empirical data
Usually the easiest part of model evaluation is checking whether a model fits experimental measurements or other empirical data. In models with parameters, a common approach to test this fit is to split the data into two disjoint subsets: training data and verification data. The training data are used to estimate the model parameters. An accurate model will closely match the verification data even though this data was not used to set the model's parameters. This practice is referred to as cross-validation in statistics.
Defining a metric to measure distances between observed and predicted data is a useful tool of assessing model fit. In statistics, decision theory, and some economic models, a loss function plays a similar role.
While it is rather straightforward to test the appropriateness of parameters, it can be more difficult to test the validity of the general mathematical form of a model. In general, more mathematical tools have been developed to test the fit of statistical models than models involving Differential equations. Tools from nonparametric statistics can sometimes be used to evaluate how well data fits a known distribution or to come up with a general model that makes only minimal assumptions about the model's mathematical form.
[edit] Scope of the model
Assessing the scope of a model, that is, determining what situations the model is applicable to, can be less straightforward. If the model was constructed based on a set of data, one must determine for what systems or situations the data is a typical set of data from.
The question of whether the model describes well the properties of the system between data points is called interpolation, and the same question for events or data points outside the observed data is called extrapolation.
As an example of the typical limitations of the scope of a model, in evaluating Newtonian classical mechanics, we can note that Newton made his measurements without advanced equipment, so he could not measure properties of particles travelling at speeds close to the speed of light. Likewise, he did not measure the movements of molecules and other small particles, but macro particles only. It is then not surprising that his model does not extrapolate well into these domains, even though his model is quite sufficient for ordinary life physics.
[edit] Philosophical considerations
Many types of modeling implicitly involve claims about causality. This is usually (but not always) true of models involving differential equations. As the purpose of modeling is to increase our understanding of the world, the validity of a model rests not only on its fit to empirical observations, but also on its ability to extrapolate to situations or data beyond those originally described in the model. One can argue that a model is worthless unless it provides some insight which goes beyond what is already known from direct investigation of the phenomenon being studied.
An example of such criticism is the argument that the mathematical models of Optimal foraging theory do not offer insight that goes beyond the common-sense conclusions of evolution and other basic principles of ecology.[3].
[edit] See also
- Biologically-inspired computing
- Cliodynamics
- Computer simulation
- Differential equations
- Dynamical systems
- Model
- Model (economics)
- Mathematical biology
- Mathematical models in physics
- Mathematical diagram
- Mathematical psychology
- Mathematical sociology
- Simulation
- Statistical model
[edit] References
- ^ Eykhoff, Pieter System Identification: Parameter and State Estimation, Wiley & Sons, (1974). ISBN 0471249807
- ^ MacKay, D.J. Information Theory, Inference, and Learning Algorithms, Cambridge, (2003-2004). ISBN 0521642981
- ^ Optimal Foraging Theory: A Critical Review - Annual Review of Ecology and Systematics, 15(1):523 - First Page Image
|
|
This article needs additional citations for verification. Please help improve this article by adding reliable references (ideally, using inline citations). Unsourced material may be challenged and removed. (May 2008) |
[edit] Further reading
- Books
- Aris, Rutherford [ 1978 ] ( 1994 ). Mathematical Modelling Techniques, New York : Dover. ISBN 0-486-68131-9
- Lin, C.C. & Segel, L.A. ( 1988 ). Mathematics Applied to Deterministic Problems in the Natural Sciences, Philadelphia : SIAM. ISBN 0-89871-229-7
- Gershenfeld, N., The Nature of Mathematical Modeling, Cambridge University Press, (1998).ISBN 0521570956
- Yang, X.-S., Mathematical Modelling for Earth Sciences, Dudedin Academic, (2008). ISBN 1903765927
- Specific applications
- Peierls, Rudolf. Model-making in physics, Contemporary Physics, Volume 21 (1), January 1980, 3-17
- Korotayev A., Malkov A., Khaltourina D. ( 2006 ). Introduction to Social Macrodynamics: Compact Macromodels of the World System Growth. Moscow : Editorial URSS. ISBN 5-484-00414-4
[edit] External links
- General reference material
- McLaughlin, Michael P. ( 1999 ) 'A Tutorial on Mathematical Modeling' PDF (264 KiB)
- Patrone, F. Introduction to modeling via differential equations, with critical remarks.
- Plus teacher and student package: Mathematical Modelling. Brings together all articles on mathematical modelling from Plus, the online mathematics magazine produced by the Millennium Mathematics Project at the University of Cambridge.
- Software

