Orthogonal matrix
From Wikipedia, the free encyclopedia
In linear algebra, an orthogonal matrix is a square matrix with real entries whose columns (or rows) are orthogonal unit vectors (i.e., orthonormal). Equivalently, a matrix Q is orthogonal if its transpose is equal to its inverse:

As a linear transformation, an orthogonal matrix preserves the dot product of vectors, and therefore acts as an isometry of Euclidean space, such as a rotation or reflection.
The set of n × n orthogonal matrices forms a group O(n), known as the orthogonal group. The subgroup SO(n) consisting of orthogonal matrices with determinant +1 is called the special orthogonal group, and each of its elements is a special orthogonal matrix. As a linear transformation, every special orthogonal matrix acts as a rotation.
The complex analogue of an orthogonal matrix is a unitary matrix.
Contents |
[edit] Overview
An orthogonal matrix is the real specialization of a unitary matrix, and thus always a normal matrix. Although we consider only real matrices here, the definition can be used for matrices with entries from any field. However, orthogonal matrices arise naturally from inner products, and for matrices of complex numbers that leads instead to the unitary requirement. Orthogonal matrices preserve inner product (see "Paul's online math notes", by Paul Dawkins, Theorem 3(c), Lamar University, 2008), so, for vectors u, v in an n-dimensional real inner product space

To see the inner product connection, consider a vector v in an n-dimensional real inner product space. Written with respect to an orthonormal basis, the squared length of v is vTv. If a linear transformation, in matrix form Qv, preserves vector lengths, then

Thus finite-dimensional linear isometries—rotations, reflections, and their combinations—produce orthogonal matrices. The converse is also true: orthogonal matrices imply orthogonal transformations. However, linear algebra includes orthogonal transformations between spaces which may be neither finite-dimensional nor of the same dimension, and these have no orthogonal matrix equivalent.
Orthogonal matrices are important for a number of reasons, both theoretical and practical. The n×n orthogonal matrices form a group, the orthogonal group denoted by O(n), which—with its subgroups—is widely used in mathematics and the physical sciences. For example, the point group of a molecule is a subgroup of O(3). Because floating point versions of orthogonal matrices have advantageous properties, they are key to many algorithms in numerical linear algebra, such as QR decomposition. As another example, with appropriate normalization the discrete cosine transform (used in MP3 compression) is represented by an orthogonal matrix.
[edit] Examples
Below are a few examples of small orthogonal matrices and possible interpretations.



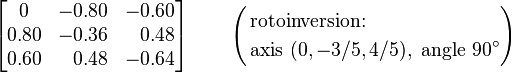

[edit] Elementary constructions
[edit] Lower dimensions
The simplest orthogonal matrices are the 1×1 matrices [1] and [−1] which we can interpret as the identity and a reflection of the real line across the origin.
The 2×2 matrices have the form
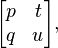
which orthogonality demands satisfy the three equations

In consideration of the first equation, without loss of generality let p = cos θ, q = sin θ; then either t = −q, u = p or t = q, u = −p. We can interpret the first case as a rotation by θ (where θ = 0 is the identity), and the second as a reflection across a line at an angle of θ/2.

The reflection at 45° exchanges x and y; it is a permutation matrix, with a single 1 in each column and row (and otherwise 0):

The identity is also a permutation matrix.
A reflection is its own inverse, which implies that a reflection matrix is symmetric (equal to its transpose) as well as orthogonal. The product of two rotation matrices is a rotation matrix, and the product of two reflection matrices is also a rotation matrix.
[edit] Higher dimensions
Regardless of the dimension, it is always possible to classify orthogonal matrices as purely rotational or not, but for 3×3 matrices and larger the non-rotational matrices can be more complicated than reflections. For example,

represent an inversion through the origin and a rotoinversion about the z axis.
Rotations also become more complicated; they can no longer be completely characterized by an angle, and may affect more than one planar subspace. While it is common to describe a 3×3 rotation matrix in terms of an axis and angle, the existence of an axis is an accidental property of this dimension that applies in no other.
However, we have elementary building blocks for permutations, reflections, and rotations that apply in general.
[edit] Primitives
The most elementary permutation is a transposition, obtained from the identity matrix by exchanging two rows. Any n×n permutation matrix can be constructed as a product of no more than n − 1 transpositions.
A Householder reflection is constructed from a non-null vector v as

Here the numerator is a symmetric matrix while the denominator is a number, the squared magnitude of v. This is a reflection in the hyperplane perpendicular to v (negating any vector component parallel to v). If v is a unit vector, then Q = I − 2vvT suffices. A Householder reflection is typically used to simultaneously zero the lower part of a column. Any orthogonal matrix of size n×n can be constructed as a product of at most n such reflections.
A Givens rotation acts on a two-dimensional (planar) subspace spanned by two coordinate axes, rotating by a chosen angle. It is typically used to zero a single subdiagonal entry. Any rotation matrix of size n×n can be constructed as a product of at most n(n − 1)/2 such rotations. In the case of 3×3 matrices, three such rotations suffice; and by fixing the sequence we can thus describe all 3×3 rotation matrices (though not uniquely) in terms of the three angles used, often called Euler angles.
A Jacobi rotation has the same form as a Givens rotation, but is used as a similarity transformation chosen to zero both off-diagonal entries of a 2×2 symmetric submatrix.
[edit] Properties
[edit] Matrix properties
A real square matrix is orthogonal if and only if its columns form an orthonormal basis of the Euclidean space Rn with the ordinary Euclidean dot product, which is the case if and only if its rows form an orthonormal basis of Rn. It might be tempting to suppose a matrix with orthogonal (not orthonormal) columns would be called an orthogonal matrix, but such matrices have no special interest and no special name; they only satisfy MTM = D, with D a diagonal matrix.
The determinant of any orthogonal matrix is +1 or −1. This follows from basic facts about determinants, as follows:

The converse is not true; having a determinant of +1 is no guarantee of orthogonality, even with orthogonal columns, as shown by the following counterexample.

With permutation matrices the determinant matches the signature, being +1 or −1 as the parity of the permutation is even or odd, for the determinant is an alternating function of the rows.
Stronger than the determinant restriction is the fact that an orthogonal matrix can always be diagonalized over the complex numbers to exhibit a full set of eigenvalues, all of which must have (complex) absolute value 1.
[edit] Group properties
The inverse of every orthogonal matrix is again orthogonal, as is the matrix product of two orthogonal matrices. In fact, the set of all n×n orthogonal matrices satisfies all the axioms of a group. It is a compact Lie group of dimension n(n−1)/2, called the orthogonal group and denoted by O(n).
The orthogonal matrices whose determinant is +1 form a path-connected normal subgroup of O(n) of index 2, the special orthogonal group SO(n) of rotations. The quotient group O(n)/SO(n) is isomorphic to O(1), with the projection map choosing [+1] or [−1] according to the determinant. Orthogonal matrices with determinant −1 do not include the identity, and so do not form a subgroup but only a coset; it is also (separately) connected. Thus each orthogonal group falls into two pieces; and because the projection map splits, O(n) is a semidirect product of SO(n) by O(1). In practical terms, a comparable statement is that any orthogonal matrix can be produced by taking a rotation matrix and possibly negating one of its columns, as we saw with 2×2 matrices. If n is odd, then the semidirect product is in fact a direct product, and any orthogonal matrix can be produced by taking a rotation matrix and possibly negating all of its columns. This follows from the property of determinants that negating a column negates the determinant, and thus negating an odd (but not even) number of columns negates the determinant.
Now consider (n+1)×(n+1) orthogonal matrices with bottom right entry equal to 1. The remainder of the last column (and last row) must be zeros, and the product of any two such matrices has the same form. The rest of the matrix is an n×n orthogonal matrix; thus O(n) is a subgroup of O(n+1) (and of all higher groups).

Since an elementary reflection in the form of a Householder matrix can reduce any orthogonal matrix to this constrained form, a series of such reflections can bring any orthogonal matrix to the identity; thus an orthogonal group is a reflection group. The last column can be fixed to any unit vector, and each choice gives a different copy of O(n) in O(n+1); in this way O(n+1) is a bundle over the unit sphere Sn with fiber O(n).
Similarly, SO(n) is a subgroup of SO(n+1); and any special orthogonal matrix can be generated by Givens plane rotations using an analogous procedure. The bundle structure persists: SO(n) ↪ SO(n+1) → Sn. A single rotation can produce a zero in the first row of the last column, and series of n−1 rotations will zero all but the last row of the last column of an n×n rotation matrix. Since the planes are fixed, each rotation has only one degree of freedom, its angle. By induction, SO(n) therefore has

degrees of freedom, and so does O(n).
Permutation matrices are simpler still; they form, not a Lie group, but only a finite group, the order n! symmetric group Sn. By the same kind of argument, Sn is a subgroup of Sn+1. The even permutations produce the subgroup of permutation matrices of determinant +1, the order n!/2 alternating group.
[edit] Canonical form
More broadly, the effect of any orthogonal matrix separates into independent actions on orthogonal two-dimensional subspaces. That is, if Q is special orthogonal then one can always find an orthogonal matrix P, a (rotational) change of basis, that brings Q into block diagonal form:

where the matrices R1,...,Rk are 2×2 rotation matrices, and with the remaining entries zero. Exceptionally, a rotation block may be diagonal, ±I. Thus, negating one column if necessary, and noting that a 2×2 reflection diagonalizes to a +1 and −1, any orthogonal matrix can be brought to the form
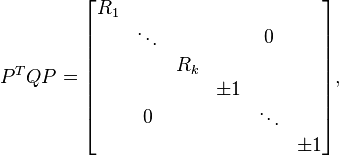
The matrices R1,...,Rk give conjugate pairs of eigenvalues lying on the unit circle in the complex plane; so this decomposition confirms that all eigenvalues have absolute value 1. If n is odd, there is at least one real eigenvalue, +1 or −1; for a 3×3 rotation, the eigenvector associated with +1 is the rotation axis.
[edit] Lie algebra
Suppose the entries of Q are differentiable functions of t, and that t = 0 gives Q = I. Differentiating the orthogonality condition

yields

Evaluation at t = 0 (Q = I) then implies

In Lie group terms, this means that the Lie algebra of an orthogonal matrix group consists of skew-symmetric matrices. Going the other direction, the matrix exponential of any skew-symmetric matrix is an orthogonal matrix (in fact, special orthogonal).
For example, the three-dimensional object physics calls angular velocity is a differential rotation, thus a vector in the Lie algebra  tangent to SO(3). Given ω = (xθ,yθ,zθ), with v = (x,y,z) a unit vector, the correct skew-symmetric matrix form of ω is
tangent to SO(3). Given ω = (xθ,yθ,zθ), with v = (x,y,z) a unit vector, the correct skew-symmetric matrix form of ω is

The exponential of this is the orthogonal matrix for rotation around axis v by angle θ; setting c = cos θ/2, s = sin θ/2,
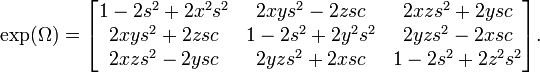
[edit] Numerical linear algebra
[edit] Benefits
Numerical analysis takes advantage of many of the properties of orthogonal matrices for numerical linear algebra, and they arise naturally. For example, it is often desirable to compute an orthonormal basis for a space, or an orthogonal change of bases; both take the form of orthogonal matrices. Having determinant ±1 and all eigenvalues of magnitude 1 is of great benefit for numeric stability. One implication is that the condition number is 1 (which is the minimum), so errors are not magnified when multiplying with an orthogonal matrix. Many algorithms use orthogonal matrices like Householder reflections and Givens rotations for this reason. It is also helpful that, not only is an orthogonal matrix invertible, but its inverse is available essentially free, by exchanging indices.
Permutations are essential to the success of many algorithms, including the workhorse Gaussian elimination with partial pivoting (where permutations do the pivoting). However, they rarely appear explicitly as matrices; their special form allows more efficient representation, such as a list of n indices.
Likewise, algorithms using Householder and Givens matrices typically use specialized methods of multiplication and storage. For example, a Givens rotation affects only two rows of a matrix it multiplies, changing a full multiplication of order n3 to a much more efficient order n. When uses of these reflections and rotations introduce zeros in a matrix, the space vacated is enough to store sufficient data to reproduce the transform, and to do so robustly. (Following Stewart (1976), we do not store a rotation angle, which is both expensive and badly behaved.)
[edit] Decompositions
A number of important matrix decompositions (Golub & Van Loan 1996) involve orthogonal matrices, including especially:
-
- QR decomposition
- M = QR, Q orthogonal, R upper triangular.
- Singular value decomposition
- M = UΣVT, U and V orthogonal, Σ non-negative diagonal.
- Eigendecomposition (Decomposition according to Spectral theorem)
- S = QΛQT, S symmetric, Q orthogonal, Λ diagonal.
- Polar decomposition
- M = QS, Q orthogonal, S symmetric non-negative definite.
[edit] Examples
Consider an overdetermined system of linear equations, as might occur with repeated measurements of a physical phenomenon to compensate for experimental errors. Write Ax = b, where A is m×n, m > n. A QR decomposition reduces A to upper triangular R. For example, if A is 5×3 then R has the form

The linear least squares problem is to find the x that minimizes ‖Ax−b‖, which is equivalent to projecting b to the subspace spanned by the columns of A. (Think of a pigeon flying over a parking lot with the sun straight overhead; its shadow hits the nearest point on the ground.) Assuming the columns of A (and hence R) are independent, the projection solution is found from ATAx = ATb. Now ATA is square (n×n) and invertible, and also equal to RTR. But the lower rows of zeros in R are superfluous in the product, which is thus already in lower-triangular upper-triangular factored form, as in Gaussian elimination (Cholesky decomposition). Here orthogonality is important not only for reducing ATA = (RTQT)QR to RTR, but also for allowing solution without magnifying numerical problems.
In the case of a linear system which is underdetermined, or an otherwise non-invertible matrix, singular value decomposition (SVD) is equally useful. With A factored as UΣVT, a satisfactory solution uses the Moore-Penrose pseudoinverse, VΣ+UT, where Σ+ merely replaces each non-zero diagonal entry with its reciprocal. Set x to VΣ+UTb.
The case of a square invertible matrix also holds interest. Suppose, for example, that A is a 3×3 rotation matrix which has been computed as the composition of numerous twists and turns. Floating point does not match the mathematical ideal of real numbers, so A has gradually lost its true orthogonality. A Gram-Schmidt process could orthogonalize the columns, but it is not the most reliable, nor the most efficient, nor the most invariant method. The polar decomposition factors a matrix into a pair, one of which is the unique closest orthogonal matrix to the given matrix, or one of the closest if the given matrix is singular. (Closeness can be measured by any matrix norm invariant under an orthogonal change of basis, such as the spectral norm or the Frobenius norm.) For a near-orthogonal matrix, rapid convergence to the orthogonal factor can be achieved by a "Newton's method" approach due to Higham (1986) (1990), repeatedly averaging the matrix with its inverse transpose. Dubrulle (1994) has published an accelerated method with a convenient convergence test.
For example, consider a (very!) non-orthogonal matrix for which the simple averaging algorithm takes seven steps

and which acceleration trims to two steps (with γ = 0.353553, 0.565685).

Gram-Schmidt yields an inferior solution, shown by a Frobenius distance of 8.28659 instead of the minimum 8.12404.
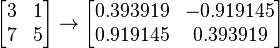
[edit] Randomization
Some numerical applications, such as Monte Carlo methods and exploration of high-dimensional data spaces, require generation of uniformly distributed random orthogonal matrices. In this context, "uniform" is defined in terms of Haar measure, which essentially requires that the distribution not change if multiplied by any freely chosen orthogonal matrix. It does not work to fill a matrix with independent uniformly distributed random entries and then orthogonalize it. It does work to fill it with independent normally distributed random entries, then use QR decomposition, ensuring that the diagonal of R contains only positive entries. Stewart (1980) replaced this with a more efficient idea that Diaconis & Shahshahani (1987) later generalized as the "subgroup algorithm" (in which form it works just as well for permutations and rotations). To generate an (n + 1)×(n + 1) orthogonal matrix, take an n×n one and a uniformly distributed unit vector of dimension n + 1. Construct a Householder reflection from the vector, then apply it to the smaller matrix (embedded in the larger size with a 1 in the bottom corner).
[edit] Spin and Pin
A subtle technical problem afflicts some uses of orthogonal matrices. Not only are the group components with determinant +1 and −1 not connected to each other, even the +1 component, SO(n), is not simply connected (except for SO(1), which is trivial). Thus it is sometimes advantageous, or even necessary, to work with a covering group of SO(n), the spin group, Spin(n). Likewise, O(n) has covering groups, the pin groups, Pin(n). For n > 2, Spin(n) is simply connected, and thus the universal covering group for SO(n). By far the most famous example of a spin group is Spin(3), often seen in the form of unit quaternions or Pauli spin matrices.
In peculiarly Ouroboros fashion, the Pin and Spin groups are found within Clifford algebras, which themselves can be built from orthogonal matrices.
[edit] Rectangular matrices
If Q is a rectangular matrix, then the conditions QTQ = I and QQT = I are not equivalent. The condition QTQ = I says that the columns of Q are orthonormal. This can only happen if Q is an m×n matrix with n ≤ m. Similarly, QQT = I says that the rows of Q are orthonormal, which requires n ≥ m.
There is no standard terminology for these matrices. They are sometimes called "orthonormal matrices", sometimes "orthogonal matrices", and sometimes simply "matrices with orthonormal rows/columns".
[edit] See also
[edit] References
- Diaconis, Persi; Shahshahani, Mehrdad (1987), "The subgroup algorithm for generating uniform random variables", Prob. in Eng. and Info. Sci. 1: 15–32, ISSN 0269-9648
- Dubrulle, Augustine A. (1994), Frobenius Iteration for the Matrix Polar Decomposition, HP Labs Technical Report HPL-94-117, http://www.hpl.hp.com/techreports/94/HPL-94-117.html
- Golub, Gene H.; Van Loan, Charles F. (1996), Matrix Computations (3/e ed.), Baltimore: Johns Hopkins University Press, ISBN 978-0-8018-5414-9
- Higham, Nicholas (1986), "Computing the Polar Decomposition—with Applications", SIAM J. Sci. Stat. Comput. 7 (4): 1160–1174, ISSN 0196-5204, http://locus.siam.org/SISC/volume-07/art_0907079.html
- Higham, Nicholas; Schreiber, Robert (July 1990), "Fast polar decomposition of an arbitrary matrix", SIAM J. Sci. Stat. Comput. 11 (4): 648–655, ISSN 0196-5204, http://locus.siam.org/SISC/volume-11/art_0911038.html [1]
- Stewart, G. W. (1976), "The Economical Storage of Plane Rotations", Numerische Mathematik 25 (2): 137–138, doi:, ISSN 0029-599X
- Stewart, G. W. (1980), "The Efficient Generation of Random Orthogonal Matrices with an Application to Condition Estimators", SIAM J. Numer. Anal. 17 (3): 403–409, doi:, ISSN 0036-1429

