Record linkage
From Wikipedia, the free encyclopedia
Record linkage (RL) refers to the task of finding entries that refer to the same entity in two or more files. Record linkage is an appropriate technique when you have to join data sets that do not have a unique database key in common. A data set that has undergone record linkage is said to be linked.
Record linkage is a useful tool when performing data mining tasks, where the data originated from different sources or different organizations. Most commonly, performing RL on datasets involves joining records of persons based on name, since no National identification number or similar is recorded in the data. In mathematical graph theory, record linkage can be seen as a technique of resolving bipartite graphs.
Contents |
[edit] Naming conventions
Record linkage is the term used by statisticians, epidemiologists and historians among others. Commercial mail and database applications refer to it as "merge/purge processing" or "list washing". Computer scientists often refer to it as "data matching" or as the "object identity problem". Other names used to describe the same concept include "entity resolution", "entity disambiguation", "duplicate detection", "record matching", "instance identification", "deduplication", "coreference resolution", "reference reconciliation" and "database hardening". This confusion of terminology has led to few cross-references between these research communities.[1][2]
[edit] Methods
There are several approaches to record linkage. The most straightforward is a rules-based approach, in which reasonable rules are developed and then refined as common exceptions are found. The advantage to this approach is that it is possible to get a good deal of accuracy without needing a lot of labeled data to train or test the rules on. The disadvantage is that to obtain very high accuracy, more and more exceptions and special cases would need to be handled, and eventually the list of rules gets too complex to be built by hand.
A very popular approach has been Probabilistic Record Linkage (PRL). In this approach, a large set of pairs of records are human-labeled as being matching or differing pairs. Then statistics are calculated from the agreement of fields on matching and differing records to determine weights on each field. During execution, the agreement or disagreement weight for each field is added to get a combined score that represents the probability that the records refer to the same entity. Often there is one threshold above which a pair is considered a match, and another threshold below which it is considered not to be a match. Between the two thresholds a pair is considered to be "possibly a match", and dealt with accordingly (e.g., human reviewed, linked, or not linked, depending on the application).
In recent years, a variety of machine learning techniques have been used in record linkage. It has been recognized that Probabilistic Record Linkage is equivalent to the "Naive Bayes" algorithm in the field of machine learning, and suffers from the same assumption of the independence of its features, which is typically not true. Higher accuracy can often be achieved by using various other machine learning techniques, including a single-layer Perceptron.
Regardless of whether rule-based, PRL or machine learning techniques are used, normalization of the data is very important. Names are often spelled differently in different sources (e.g., "Wm. Smith", "William Smith", "William J. Smith", "Bill Smith", etc.), dates can be recorded various ways ("1/2/73", "1973.1.2", "Jan 2, 1973"), and places can be recorded differently as well ("Berkeley, CA", "Berkeley, Alameda, California, USA", etc.). By normalizing these into a common format and using comparison techniques that handle additional variation, much more consistency can be achieved, resulting in higher accuracy in any record linkage technique.
[edit] History of RL theory
The initial idea goes back to Halbert L. Dunn in 1946[3]. In the 1950s, Howard Borden Newcombe laid the probabilistic foundations of modern record linkage theory.
In 1969, Ivan Fellegi and Alan Sunter formalized these ideas and proved that the probabilistic decision rule they described was optimal when the comparison attributes are conditionally independent. Their pioneering work "A Theory For Record Linkage"[4] is, still today, the mathematical tool for many record linkage applications.
Since the late 1990s, various machine learning techniques have been developed that can, under favorable conditions, be used to estimate the conditional probabilities required by the Fellegi-Sunter (FS) theory. Several researchers have reported that the conditional independence assumption of the FS algorithm is often violated in practice; however, published efforts to explicitly model the conditional dependencies among the comparison attributes have not resulted in an improvement in record linkage quality.[citation needed]
[edit] Mathematical model
In an application with two files, A and B, denote the rows (records) by α(a) in file A and β(b) in file B. Assign K characteristics to each record. The set of records that represent identical entities is defined by

and the complement of set M, namely set U representing different entities is defined as
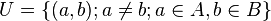 .
.
A vector, γ is defined, that contains the coded agreements and disagreements on each characteristic:
![\gamma \left[ \alpha ( a ), \beta ( b ) \right] = \{ \gamma^{1} \left[ \alpha ( a ) , \beta ( b ) \right] ,..., \gamma^{K} \left[ \alpha ( a ), \beta ( b ) \right] \}](http://upload.wikimedia.org/math/4/c/5/4c5cfcd20633cb889a731783c893cce8.png)
where K is a subscript for the characteristics (sex, age, marital status, etc.) in the files. The conditional probabilities of observing a specific vector γ given 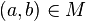 ,
,  are defined as
are defined as
![m(\gamma) = P \left\{ \gamma \left[ \alpha (a), \beta (b) \right] | (a,b) \in M \right\} =
\sum_{(a, b) \in M} P \left\{\gamma\left[ \alpha(a), \beta(b) \right] \right\} \cdot
P \left[ (a, b) | M\right]](http://upload.wikimedia.org/math/4/a/9/4a94646bbc8ca9186d810a923381e0c6.png)
and
![u(\gamma) = P \left\{ \gamma \left[ \alpha (a), \beta (b) \right] | (a,b) \in U \right\} =
\sum_{(a, b) \in U} P \left\{\gamma\left[ \alpha(a), \beta(b) \right] \right\} \cdot
P \left[ (a, b) | U\right],](http://upload.wikimedia.org/math/7/3/2/732006de2ff9c51cb1b533a84dfbdd23.png) respectively.
respectively.
[edit] Applications in historical research
Record linkage is important to social history research since most data sets, such as census records and parish registers were recorded long before the invention of National identification numbers. When old sources are digitized, linking of data sets is a prerequisite for longitudinal study. This process is often further complicated by lack of standard spelling of names, family names that changes according to place of dwelling, changing of administrative boundaries and problems of checking the data against other sources. Record Linkage was among the most prominent themes in the History and computing field in the 1980s, but has since been subject to less attention in research.
[edit] Applications in medical practice and research
Record linkage is an important tool in creating data required for examining the health of the public and of the health care system itself. It can be used to improve data holdings, data collection, quality assessment, and the dissemination of information. Data sources can be examined to eliminate duplicate records, to identify underreporting and missing cases (e.g., census population counts), to create person-oriented health statistics, and to generate disease registries and health surveillance systems. Some cancer registries link various data sources (e.g., hospital admissions, pathology and clinical reports, and death registrations) to generate their registries. Record linkage is also used to create health indicators. For example, fetal and infant mortality is a general indicator of a country's socioeconomic development, public health, and maternal and child services. If infant death records are matched to birth records, it is possible to use birth variables, such as birth weight and gestational age, along with mortality data, such as cause of death, in analyzing the data. Linkages can help in follow-up studies of cohorts or other groups to determine factors such as vital status, residential status, or health outcomes. Tracing is often needed for follow-up of industrial cohorts, clinical trials, and longitudinal surveys to obtain the cause of death and/or cancer.
[edit] References
- ^ Cristen, P & T: Febrl - Freely extensible biomedical record linkage (Manual, release 0.3) p.9
- ^ Elmagarmid, Ahmed; Panagiotis G. Ipeirotis, Vassilios Verykios (January 2007). "Duplicate Record Detection: A Survey" (PDF). IEEE Transactions on Knowledge and Data Engineering 19 (1): pp. 1–16. doi:. http://archive.nyu.edu/handle/2451/27823. Retrieved on 2009-03-30.
- ^ Dunn, Halbert L. (December 1946). "Record Linkage" (PDF). American Journal of Public Health 36 (12): pp. 1412–1416. http://www.ajph.org/cgi/reprint/36/12/1412. Retrieved on 2008-05-31.
- ^ Fellegi, Ivan; Sunter, Alan (December 1969). "A Theory for Record Linkage". Journal of the American Statistical Association 64 (328): pp. 1183–1210. doi:. JSTOR: 2286061..
[edit] External links
- Discussion of record linkage strategy and tactics
- Statistics New Zealand Data Integration Manual
- Data Linkage Project at Penn State, USA
[edit] Software implementations
- Febrl - Open source software application for RL - by the Australian National University.
- Link Plus Probabilistic record linkage program - developed at the US Centers For Disease Control and Prevention
- FRIL - Fine-Grained Record Integration and Linkage Tool - developed at the Emory University and US Centers For Disease Control and Prevention
- SimMetrics Open source library of String Similarity techniques - by Sam Chapman at the University of Sheffield
- The Link King - SAS System application - developed at Washington State's Division of Alcohol and Substance Abuse (DASA) by Kevin M. Campbell
- Data Deduplication and Integration - developed by the CS department at Maryland University

