Covariance
From Wikipedia, the free encyclopedia
In probability theory and statistics, covariance is a measure of how much two variables change together (variance is a special case of the covariance when the two variables are identical).
If two variables tend to vary together (that is, when one of them is above its expected value, then the other variable tends to be above its expected value too), then the covariance between the two variables will be positive. On the other hand, if one of them tends to be above its expected value when the other variable is below its expected value, then the covariance between the two variables will be negative.
Contents |
[edit] Definition
The covariance between two real-valued random variables X and Y, with expected values  and
and  is defined as
is defined as
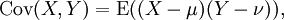
where E is the expected value operator. This can also be written:

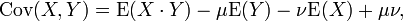

Random variables whose covariance is zero are called uncorrelated.
If X and Y are independent, then their covariance is zero. This follows because under independence,

Recalling the final form of the covariance derivation given above, and substituting, we get

The converse, however, is generally not true: Some pairs of random variables have covariance zero although they are not independent. Under some additional assumptions, covariance zero sometimes does entail independence, as for example in the case of multivariate normal distributions.
The units of measurement of the covariance Cov(X, Y) are those of X times those of Y. By contrast, correlation, which depends on the covariance, is a dimensionless measure of linear dependence.
[edit] Properties
If X, Y, W, and V are real-valued random variables and a, b, c, d are constant ("constant" in this context means non-random), then the following facts are a consequence of the definition of covariance:






For sequences X1, ..., Xn and Y1, ..., Ym of random variables, we have

For a sequence X1, ..., Xn of random variables, and constants a1, ..., an, we have
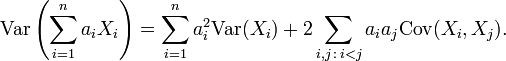
[edit] Incremental computation
Covariance can be computed efficiently from incrementally available values using a generalization of the computational formula for the variance:
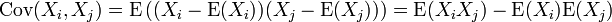
[edit] Relationship to inner products
Many of the properties of covariance can be extracted elegantly by observing that it satisfies similar properties to those of an inner product:
- (1) bilinear: for constants a and b and random variables X, Y, and U, Cov(aX + bY, U) = a Cov(X, U) + b Cov(Y, U)
- (2) symmetric: Cov(X, Y) = Cov(Y, X)
- (3) positive semi-definite: Var(X) = Cov(X, X) ≥ 0, and Cov(X, X) = 0 implies that X is a constant random variable (K).
It can be shown that the covariance is an inner product over some subspace of the vector space of random variables with finite second moment.
[edit] Covariance matrix, operator, bilinear form, and function
For column-vector valued random variables X and Y with respective expected values μ and ν, and respective scalar components m and n, the covariance is defined to be the m×n matrix called the covariance matrix:

For vector-valued random variables, Cov(X, Y) and Cov(Y, X) are each other's transposes.
More generally, for a probability measure P on a Hilbert space H with inner product 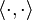 , the covariance of P is the bilinear form Cov: H × H → H given by
, the covariance of P is the bilinear form Cov: H × H → H given by

for all x and y in H. The covariance operator C is then defined by

(from the Riesz representation theorem, such operator exists if Cov is bounded). Since Cov is symmetric in its arguments, the covariance operator is self-adjoint (the infinite-dimensional analogy of the transposition symmetry in the finite-dimensional case). When P is a centred Gaussian measure, C is also a nuclear operator. In particular, it is a compact operator of trace class, that is, it has finite trace.
Even more generally, for a probability measure P on a Banach space B, the covariance of P is the bilinear form on the algebraic dual  , defined by
, defined by

where  is now the value of the linear functional x on the element z.
is now the value of the linear functional x on the element z.
Quite similarly, the covariance function of a function-valued random element (in special cases called random process or random field) z is

where z(x) is now the value of the function z at the point x, i.e., the value of the linear functional  evaluated at z.
evaluated at z.
[edit] Comments
The covariance is sometimes called a measure of "linear dependence" between the two random variables. That does not mean the same thing as in the context of linear algebra (see linear dependence). When the covariance is normalized, one obtains the correlation matrix. From it, one can obtain the Pearson coefficient, which gives us the goodness of the fit for the best possible linear function describing the relation between the variables. In this sense covariance is a linear gauge of dependence.
[edit] See also
- Covariance function
- Covariance matrix
- Autocovariance
- Analysis of covariance
- Sample mean and sample covariance
[edit] External links
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||

