Scale-invariant feature transform
From Wikipedia, the free encyclopedia
| Feature detection | |
 Output of a typical corner detection algorithm |
|
| Edge detection | |
|---|---|
| Canny | |
| Canny-Deriche | |
| Differential | |
| Sobel | |
| Interest point detection | |
| Corner detection | |
| Harris operator | |
| Shi and Tomasi | |
| Level curve curvature | |
| SUSAN | |
| FAST | |
| Blob detection | |
| Laplacian of Gaussian (LoG) | |
| Difference of Gaussians (DoG) | |
| Determinant of Hessian (DoH) | |
| Maximally stable extremal regions | |
| Ridge detection | |
| Affine invariant feature detection | |
| Affine shape adaptation | |
| Harris affine | |
| Hessian affine | |
| Feature description | |
| SIFT | |
| SURF | |
| GLOH | |
| LESH | |
| Scale-space | |
| Scale-space axioms | |
| Implementation details | |
| Pyramids | |
Scale-invariant feature transform (or SIFT) is an algorithm in computer vision to detect and describe local features in images. The algorithm was published by David Lowe in 1999.[1]
Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, and match moving.
The algorithm is patented; the owner is the University of British Columbia.[2]
Contents |
[edit] Features
The detection and description of local image features can help in object recognition. The SIFT features are local and based on the appearance of the object at particular interest points, and are invariant to image scale and rotation. They are also robust to changes in illumination, noise, and minor changes in viewpoint. In addition to these properties, they are highly distinctive, relatively easy to extract, allow for correct object identification with low probability of mismatch and are easy to match against a (large) database of local features. Object description by set of SIFT features is also robust to partial occlusion; as few as 3 SIFT features from an object are enough to compute its location and pose. Recognition can be performed in close-to-real time, at least for small databases and on modern computer hardware.[citations needed]
[edit] Algorithm
[edit] Scale-space extrema detection
This is the stage where the interest points, which are called keypoints in the SIFT framework, are detected. For this, the image is convolved with Gaussian filters at different scales, and then the difference of successive Gaussian-blurred images are taken. Keypoints are then taken as maxima/minima of the Difference of Gaussians (DoG) that occur at multiple scales. Specifically, a DoG image 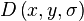 is given by
is given by
 ,
,- where
 is the original image
is the original image  convolved with the Gaussian blur
convolved with the Gaussian blur  at scale kσ, i.e.,
at scale kσ, i.e.,

Hence a DoG image between scales kiσ and kjσ is just the difference of the Gaussian-blurred images at scales kiσ and kjσ. For scale-space extrema detection in the SIFT algorithm, the image is first convolved with Gaussian-blurs at different scales. The convolved images are grouped by octave (an octave corresponds to doubling the value of σ), and the value of ki is selected so that we obtain a fixed number of convolved images per octave. Then the Difference-of-Gaussian images are taken from adjacent Gaussian-blurred images per octave.
Once DoG images have been obtained, keypoints are identified as local minima/maxima of the DoG images across scales. This is done by comparing each pixel in the DoG images to its eight neighbors at the same scale and nine corresponding neighboring pixels in each of the neighboring scales. If the pixel value is the maximum or minimum among all compared pixels, it is selected as a candidate keypoint.
This keypoint detection step is a variation of one of the blob detection methods by detecting scale-space extrema of the scale normalized Laplacian,[3] that is detecting points that are local extrema with respect to both space and scale, in the discrete case by comparisons with the nearest 26 neighbours in a discretized scale-space volume. The difference of Gaussians operator can be seen as an approximation to the Laplacian, here expressed in a pyramid setting.
[edit] Keypoint localization

Scale-space extrema detection produces too many keypoint candidates, some of which are unstable. The next step in the algorithm is to perform a detailed fit to the nearby data for accurate location, scale, and ratio of principal curvatures. This information allows points to be rejected that have low contrast (and are therefore sensitive to noise) or are poorly localized along an edge.
[edit] Interpolation of nearby data for accurate position
First, for each candidate keypoint, interpolation of nearby data is used to accurately determine its position. The initial approach was to just locate each keypoint at the location and scale of the candidate keypoint.[1] The new approach calculates the interpolated location of the maximum, which substantially improves matching and stability.[4] The interpolation is done using the quadratic Taylor expansion of the Difference-of-Gaussian scale-space function, with the candidate keypoint as the origin. This Taylor expansion is given by:

where D and its derivatives are evaluated at the candidate keypoint and  is the offset from this point. The location of the extremum,
is the offset from this point. The location of the extremum,  , is determined by taking the derivative of this function with respect to
, is determined by taking the derivative of this function with respect to  and setting it to zero. If the offset is larger than 0.5 in any dimension, then that's an indication that the extremum lies closer to another candidate keypoint. In this case, the candidate keypoint is changed and the interpolation performed instead about that point. Otherwise the offset is added to its candidate keypoint to get the interpolated estimate for the location of the extremum.
and setting it to zero. If the offset is larger than 0.5 in any dimension, then that's an indication that the extremum lies closer to another candidate keypoint. In this case, the candidate keypoint is changed and the interpolation performed instead about that point. Otherwise the offset is added to its candidate keypoint to get the interpolated estimate for the location of the extremum.
[edit] Discarding low-contrast keypoints
To discard the keypoints with low contrast, the value of the second-order Taylor expansion  is computed at the offset . If this value is less than 0.03, the candidate keypoint is discarded. Otherwise it is kept, with final location
is computed at the offset . If this value is less than 0.03, the candidate keypoint is discarded. Otherwise it is kept, with final location  and scale σ, where
and scale σ, where 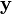 is the original location of the keypoint at scale σ.
is the original location of the keypoint at scale σ.
[edit] Eliminating edge responses
The DoG function will have strong responses along edges, even if the candidate keypoint is unstable to small amounts of noise. Therefore, in order to increase stability, we need to eliminate the keypoints that have poorly determined locations but have high edge responses.
For poorly defined peaks in the DoG function, the principal curvature across the edge would be much larger than the principal curvature along it. Finding these principal curvatures amounts to solving for the eigenvalues of the second-order Hessian matrix, H:

The eigenvalues of H are proportional to the principal curvatures of D. It turns out that the ratio of the two eigenvalues, say α is the larger one, and β the smaller one, with ratio r = α / β, is sufficient for SIFT's purposes. The trace of H, i.e., Dxx + Dyy, gives us the sum of the two eigenvalues, while its determinant, i.e., 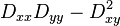 , yields the product. The ratio
, yields the product. The ratio  can be shown to be equal to
can be shown to be equal to  , which depends only on the ratio of the eigenvalues rather than their individual values. R is minimum when the eigenvalues are equal to each other. Therefore the higher the absolute difference between the two eigenvalues, which is equivalent to a higher absolute difference between the two principal curvatures of D, the higher the value of R. It follows that, for some threshold eigenvalue ratio rth, if R for a candidate keypoint is larger than
, which depends only on the ratio of the eigenvalues rather than their individual values. R is minimum when the eigenvalues are equal to each other. Therefore the higher the absolute difference between the two eigenvalues, which is equivalent to a higher absolute difference between the two principal curvatures of D, the higher the value of R. It follows that, for some threshold eigenvalue ratio rth, if R for a candidate keypoint is larger than  , that keypoint is poorly localized and hence rejected. The new approach uses rth = 10.[4]
, that keypoint is poorly localized and hence rejected. The new approach uses rth = 10.[4]
This processing step for suppressing responses at edges is a transfer of a corresponding approach in the Harris operator for corner detection. The difference is that the measure for thresholding is computed from the Hessian matrix instead of a second-moment matrix (see structure tensor).
[edit] Orientation assignment
In this step, each keypoint is assigned one or more orientations based on local image gradient directions. This is the key step in achieving invariance to rotation as the keypoint descriptor can be represented relative to this orientation and therefore achieve invariance to image rotation.
First, the Gaussian-smoothed image 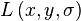 at the keypoint's scale σ is taken so that all computations are performed in a scale-invariant manner. For an image sample
at the keypoint's scale σ is taken so that all computations are performed in a scale-invariant manner. For an image sample  at scale σ, the gradient magnitude,
at scale σ, the gradient magnitude, 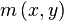 , and orientation,
, and orientation,  , are precomputed using pixel differences:
, are precomputed using pixel differences:


The magnitude and direction calculations for the gradient are done for every pixel in a neighboring region around the keypoint in the Gaussian-blurred image L. An orientation histogram with 36 bins is formed, with each bin covering 10 degrees. Each sample in the neighboring window added to a histogram bin is weighted by its gradient magnitude and by a Gaussian-weighted circular window with a σ that is 1.5 times that of the scale of the keypoint. The peaks in this histogram correspond to dominant orientations. Once the histogram is filled, the orientations corresponding to the highest peak and local peaks that are within 80% of the highest peaks are assigned to the keypoint. In the case of multiple orientations being assigned, an additional keypoint is created having the same location and scale as the original keypoint for each additional orientation.
[edit] Keypoint descriptor
Previous steps found keypoint locations at particular scales and assigned orientations to them. This ensured invariance to image location, scale and rotation. Now we want to compute descriptor vectors for these keypoints such that the descriptors are highly distinctive and partially invariant to the remaining variations, like illumination, 3D viewpoint, etc. This step is image closest in scale to the keypoint's scale. Just like before, the contribution of each pixel is weighted by the gradient magnitude, and by a Gaussian with σ 1.5 times the scale of the keypoint. Histograms contain 8 bins each, and each descriptor contains a 4x4 array of 16 histograms around the keypoint. This leads to a SIFT feature vector with (4 x 4 x 8 = 128 elements). This vector is normalized to enhance invariance to changes in illumination.
Although the dimension of the descriptor, i.e. 128, seems high, descriptors with lower dimension than this don't perform as well across the range of matching tasks,[4] and the computational cost remains low due to the approximate BBF (see below) method used for finding the nearest-neighbor. Longer descriptors continue to do better but not by much and there is an additional danger of increased sensitivity to distortion and occlusion. It is also shown that feature matching accuracy is above 50% for viewpoint changes of up to 50 degrees. Therefore SIFT descriptors are invariant to minor affine changes. To test the distinctiveness of the SIFT descriptors, matching accuracy is also measured against varying number of keypoints in the testing database, and it is shown that matching accuracy decreases only very slightly for very large database sizes, thus indicating that SIFT features are highly distinctive.
[edit] Comparison of SIFT features with other local features
There has been an extensive study done on the performance evaluation of different local descriptors, including SIFT, using a range of detectors.[5] The main results are summarized below:
- SIFT and SIFT-like GLOH features exhibit the highest matching accuracies (recall rates) for an affine transformation of 50 degrees. After this transformation limit, results start getting unreliable.
- Distinctiveness of descriptors is measured by summing the eigenvalues of the descriptors, obtained by the Principal components analysis of the descriptors normalized by their variance. This corresponds to the amount of variance captured by different descriptors, therefore, to their distinctiveness. PCA-SIFT (Principal Components Analysis applied to SIFT descriptors), GLOH and SIFT features give the highest values.
- SIFT-based descriptors outperform other local descriptors on both textured and structured scenes, with the difference in performance larger on the textured scene.
- For scale changes in the range 2-2.5 and image rotations in the range 30 to 45 degrees, SIFT and SIFT-based descriptors again outperform other local descriptors with both textured and structured scene content.
- Performance for all local descriptors degraded on images introduced with a significant amount of blur, with the descriptors that are based on edges, like shape context, performing increasingly poorly with increasing amount blur. This is because edges disappear in the case of a strong blur. But GLOH, PCA-SIFT and SIFT still performed better than the others. This is also true for evaluation in the case of illumination changes.
The evaluations carried out suggests strongly that SIFT-based descriptors, which are region-based, are the most robust and distinctive, and are therefore best suited for feature matching. However, most recent feature descriptors such as SURF have not been evaluated in this study.
SURF has later been shown to have similar performance to SIFT, while at the same time being much faster.[6]
Recently, a slight variation of the descriptor employing an irregular histogram grid has been proposed that significantly improves its performance[7]. Instead of using a 4x4 grid of histogram bins, all bins extend to the center of the feature. This improves the descriptor's robustness to scale changes.
[edit] Applications
[edit] Object recognition using SIFT features
Given SIFT's ability to find distinctive keypoints that are invariant to location, scale and rotation, and robust to affine transformations (changes in scale, rotation, shear, and position) and changes in illumination, they are usable for object recognition. The steps are given below.
- First, SIFT features are obtained from the input image using the algorithm described above.
- These features are matched to the SIFT feature database obtained from the training images. This feature matching is done through a Euclidean-distance based nearest neighbor approach. To increase robustness, matches are rejected for those keypoints for which the ratio of the nearest neighbor distance to the second nearest neighbor distance is greater than 0.8. This discards many of the false matches arising from background clutter. Finally, to avoid the expensive search required for finding the Euclidean distance based nearest neighbor, an approximate algorithm, called the Best-Bin-First (BBF) algorithm is used.[8] This is a fast method for returning the nearest neighbor with high probability, and can give speedup by factor of 1000 while finding nearest neighbor (of interest) 95% of the time.
- Although the distance ratio test described above discards many of the false matches arising from background clutter, we still have matches that belong to different objects. Therefore to increase robustness to object identification, we want to cluster those features that belong to the same object and reject the matches that are left out in the clustering process. This is done using the Hough Transform. This will identify clusters of features that vote for the same object pose. When clusters of features are found to vote for the same pose of an object, the probability of the interpretation being correct is much higher than for any single feature. Each keypoint votes for the set of object poses that are consistent with the keypoint's location, scale, and orientation. Bins that accumulate at least 3 votes are identified as as candidate object/pose matches.
- For each candidate cluster, a least-squares solution for the best estimated affine projection parameters relating the training image to the input image is obtained. If the projection of a keypoint through these parameters lies within half the error range that was used for the parameters in the Hough transform bins, the keypoint match is kept. If fewer than 3 points remain after discarding outliers for a bin, then the object match is rejected. The least-squares fitting is repeated until no more rejections take place. This works better for planar surface recognition than 3D object recognition since the affine model is no longer accurate for 3D objects.
SIFT features can essentially be applied to any task that requires identification of matching locations between images. Work has been done on applications such as recognition of particular object categories in 2D images, 3D reconstruction, motion tracking and segmentation, robot localization, image panorama stitching and epipolar calibration. Some of these are discussed in more detail below.
[edit] Robot localization and mapping
In this application,[9] a trinocular stereo system is used to determine 3D estimates for keypoint locations. Keypoints are used only when they appear in all 3 images with consistent disparities, resulting in very few outliers. As the robot moves, it localizes itself using feature matches to the existing 3D map, and then incrementally adds features to the map while updating their 3D positions using a Kalman filter. This provides a robust and accurate solution to the problem of robot localization in unknown environments.
[edit] Panorama stitching
SIFT feature matching can be used in image stitching for fully automated panorama reconstruction from non-panoramic images. The SIFT features extracted from the input images are matched against each other to find k nearest-neighbors for each feature. These correspondences are then used to find m candidate matching images for each image. Homographies between pairs of images are then computed using RANSAC and a probabilistic model is used for verification. Because there is no restriction on the input images, graph search is applied to find connected components of image matches such that each connected component will correspond to a panorama. Finally for each connected component Bundle adjustment is performed to solve for joint camera parameters, and the panorama is rendered using multi-band blending. Because of the SIFT-inspired object recognition approach to panorama stitching, the resulting system is insensitive to the ordering, orientation, scale and illumination of the images. The input images contain multiple panoramas and noise images, and panoramic sequences are recognized and rendered as output. As said earlier, the algorithm is insensitive to the ordering, scale and orientation of the images. It is also insensitive to noise images which are not part of a panorama.[10]
[edit] 3D scene modeling, recognition and tracking
This application uses SIFT features for 3D object recognition and 3D modeling in context of augmented reality, in which synthetic objects with accurate pose are superimposed on real images. SIFT matching is done for a number of 2D images of a scene or object taken from different angles. This is used with bundle adjustment to build a sparse 3D model of the viewed scene and to simultaneously recover camera poses and calibration parameters. Then the position, orientation and size of the virtual object are defined relative to the coordinate frame of the recovered model. For online match moving, SIFT features again are extracted from the current video frame and matched to the features already computed for the world mode, resulting in a set of 2D-to-3D correspondences. These correspondences are then used to compute the current camera pose for the virtual projection and final rendering. A regularization technique is used to reduce the jitter in the virtual projection.[11]
[edit] 3D SIFT descriptors for human action recognition
This application introduces 3D SIFT descriptors for spatio-temporal data in context of human action recognition in video sequences.[12] The Orientation Assignment and Descriptor Representation stages of the 2D SIFT algorithm are extended to describe SIFT features in a spatio-temporal domain. For application to human action recognition in a video sequence, random sampling of the training videos is carried out at different locations, times and scales. The spatio-temporal regions around these interest points are then described using the 3D SIFT descriptor. These descriptors are then clustered to form a spatio-temporal Bag of words model. 3D SIFT descriptors extracted from the test videos are then matched against these words for human action classification.
The authors report much better results with their 3D SIFT descriptor approach than with other approaches like simple 2D SIFT descriptors and Gradient Magnitude.[13]
[edit] See also
- 3D single object recognition
- autostitch
- Feature detection (computer vision)
- SURF (Speeded Up Robust Features)
[edit] References
- ^ a b Lowe, David G. (1999). "Object recognition from local scale-invariant features". Proceedings of the International Conference on Computer Vision 2: 1150–1157. doi:10.1109/ICCV.1999.790410.
- ^ Nowozin, Sebastian (2005). "autopano-sift". http://user.cs.tu-berlin.de/~nowozin/autopano-sift/. Retrieved on 2008-08-20.
- ^ Lindeberg, Tony (1998). "Feature detection with automatic scale selection". International Journal of Computer Vision 30 (2): 79–116. doi:. http://www.nada.kth.se/cvap/abstracts/cvap198.html.
- ^ a b c Lowe, David G. (2004). "Distinctive Image Features from Scale-Invariant Keypoints". International Journal of Computer Vision 60 (2): 91–110. doi:. http://citeseer.ist.psu.edu/lowe04distinctive.html.
- ^ Mikolajczyk, K.; Schmid, C. (2005). "A performance evaluation of local descriptors". IEEE Transactions on Pattern Analysis and Machine Intelligence 27: 1615–1630. doi:. http://research.microsoft.com/users/manik/projects/trade-off/papers/MikolajczykPAMI05.pdf.
- ^ http://www.tu-chemnitz.de/etit/proaut/rsrc/iav07-surf.pdf
- ^ Cui, Y.; Hasler, N.; Thormaehlen, T.; Seidel, H.-P. (July 2009). "Scale Invariant Feature Transform with Irregular Orientation Histogram Binning". Proceedings of the International Conference on Image Analysis and Recognition (ICIAR 2009), Halifax, Canada: Springer.
- ^ Beis, J.; Lowe, David G. (1997). "Shape indexing using approximate nearest-neighbour search in high-dimensional spaces". Conference on Computer Vision and Pattern Recognition, Puerto Rico: sn: 1000–1006. doi:10.1109/CVPR.1997.609451.
- ^ Se, S.; Lowe, David G.; Little, J. (2001). "Vision-based mobile robot localization and mapping using scale-invariant features". Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) 2: 2051. doi:10.1109/ROBOT.2001.932909.
- ^ Brown, M.; Lowe, David G. (2003). "Recognising Panoramas". Proceedings of the ninth IEEE International Conference on Computer Vision 2: 1218–1225. doi:10.1109/ICCV.2003.1238630.
- ^ Iryna Gordon and David G. Lowe, "What and where: 3D object recognition with accurate pose," in Toward Category-Level Object Recognition, (Springer-Verlag, 2006), pp. 67-82
- ^ Scovanner, Paul; Ali, S; Shah, M (2007). "A 3-dimensional sift descriptor and its application to action recognition". Proceedings of the 15th International Conference on Multimedia: 357-360. doi:10.1145/1291233.1291311.
- ^ Niebles, J. C. Wang, H. and Li, Fei-Fei (2006). "Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words". Proceedings of the British Machine Vision Conference (BMVC). Retrieved on 2008-08-20.
[edit] Implementations
- Sebastian Nowozin (C#)
- Andrea Vedaldi (Matlab/C)
- Andrea Vedaldi (C++)
- David Lowe (C/Matlab)
- Rob Hess (C)
- Dr Krystian Mikolajczyk (C)
- Stephan Saalfeld (Java)
- Adam Chapman / ChangChang Wu (Matlab-GPU implementation)
- Integrating Vision Toolkit (C++) (folder IVT/src/Features/SIFTFeatures, by Pedram Azad and Lars Pätzold)
- libsiftfast (Matlab/C++) Uses x86 SSE optimizations and runs on multiple cores using OpenMP. (For Linux, Windows, and Macs). Under LGPL
- lip-vireo (Linux and Windows versions)

