Regression toward the mean
From Wikipedia, the free encyclopedia

Regression toward the mean[1][2], also called reversion to the mean,[3] is a principle in statistics that states that if a pair of independent measurements are made from the same distribution, samples far from the mean on the first measurement will tend to be closer to the mean on the second one. Moreover, the farther from the mean on the first measurement, the stronger the effect is. Random variance affects the measurement of any variable: this random variance will cause some samples to be extreme. For the second measurement, these samples will appear to regress because the random variance affecting the samples in the second measurement is independent of the random variance affecting the first. Thus, regression toward the mean is a mathematical inevitability: any measurement of any variable that is affected by random variance must show regression to the mean.
For example, if you give a class of students a test on two successive days, the worst performers on the first day will tend to improve their scores on the second day, and the best performers on the first day will tend to do worse on the second day. The phenomenon occurs because each sample is affected by random variance. Student scores are determined in part by underlying ability and in part by purely stochastic, unpredictable chance. For the first test, some will be lucky, and score more than their ability, and some will be unlucky and score less than their ability. Some of the lucky students on the first test will be lucky again on the second test, but more of them will have (for them) average or below average scores. Therefore a student who was lucky on the first test is more likely to have a worse score on the second test than a better score. Similarly, students who score less than the mean on the first test will tend to see their scores increase for the second test.
The magnitude of regression toward the mean depends on the ratio of error variance over the total variance within the sample. If a measurement is determined largely by random chance, then regression to the mean will be very large. If measurement is determined largely by known factors, regression to the mean will be less. In one extreme case, where all individuals are identical and all differences are caused by measurement error, there will be 100% regression toward the mean. If we ask 10,000 people to flip a fair coin ten times, the people who flipped ten heads the first time are expected to get five heads on a repeat experiment, the same as the people who flipped zero heads the first time. In the other extreme of perfect measurement, there is not any regression toward the mean. We expect the second measurement will be the same as the first.
Contents |
[edit] History
The concept of regression comes from genetics and was popularized by Sir Francis Galton during the late 19th century with the publication of Regression Towards Mediocrity in Hereditary Stature. Galton observed that extreme characteristics (e.g., height) in parents are not passed on completely to their offspring. Rather, the characteristic in the offspring regress towards a mediocre point (a point which has since been identified as the mean). By measuring the heights of hundreds of people, he was able to quantify regression to the mean, and estimate the size of the effect. Galton wrote that, "the average regression of the offspring is a constant fraction of their respective mid-parental deviations." This means that the difference between a child and its parents for some characteristic is proportional to its parents deviation from typical people in the population. So if its parents are each two inches taller than the averages for men and women, on average it will be shorter than its parents by some factor (which, today, we would call one minus the regression coefficient) times two inches. For height, Galton estimated this correlation coefficient to be about 2/3: the height of an individual will measure around a mid-point that is 2/3rds of the parents deviation.
Although Galton popularized the concept of regression, he fundamentally misunderstood the phenomenon; thus, his understanding of regression differs from that of modern statisticians.[citation needed] Galton was correct in his observation that the characteristics of an individual are not determined completely by their parents; there must be another source. However, he explains this by arguing that, "A child inherits partly from his parents, partly from his ancestors. Speaking generally, the further his genealogy goes back, the more numerous and varied will his ancestry become, until they cease to differ from any equally numerous sample taken at haphazard from the race at large."[4] In other words, Galton believed that regression toward the mean was simply an inheritance of characteristics from ancestors that are not expressed in the parents: he did not understand regression to the mean as a statistical phenomenon. In contrast to this view, it is now known that regression toward the mean is a mathematical inevitability: if there is any random variance between the height of an individual and parents - if the correlation is not exactly equal to 1 - then the predictions must regress to the mean regardless of the underlying mechanisms of inheritance, race or culture. Thus, Galton was attributing random variance in height to the ancestry of the individual.
[edit] Why it matters
The most important reason to care about regression toward the mean is in the design of experiments.
Take a hypothetical example of 1,000 males of a similar age who were examined and scored on the risk of experiencing a heart attack. Statistics could be used to measure the success of an intervention on the 50 who were rated at the greatest risk. The intervention could be a change in diet, exercise, or a drug treatment. Even if the interventions are worthless, the test group would be expected to show and improvement on their next physical exam, because of regression toward the mean. The best way to combat this effect is to divide the group randomly into a treatment group that receives the treatment, and a control group that does not. The treatment would then be judged effective only if the treatment group improves more than the control group.
Alternately, a group of disadvantaged children could be tested to identify the ones with most college potential. The top 1% could be identified and supplied them with special enrichment courses, tutoring, counseling and computers. Even if the program is effective, their average scores may well be less when the test is repeated a year later. However, in these circumstances it may be considered unfair to have a control group of disadvantaged children whose special needs are ignored. A mathematical calculation for shrinkage can adjust for this effect, although it will not be as reliable as the control group method (see also Stein's example.)
The effect can also be exploited for general inference and estimation. The hottest place in the country today is more likely to be cooler tomorrow than hotter. The best performing mutual fund over the last three years is more likely to see performance decline than improve over the next three years. The most successful Hollywood actor of this year is likely to have less gross than more gross for his or her next movie. The baseball player with the greatest batting average by the All-Star break is more likely to have a lower average than a higher average over the second half of the season.
[edit] Warnings
The concept of regression toward the mean can be misused very easily.
The Law of large numbers is an unrelated phenomenon often confused with regression toward the mean. Suppose you flip a coin 100 times and measure the frequency of heads. Then you flip the coin 100 more times. The frequency of heads over the entire 200 flips is likely to be closer to the mean than the frequency over the first 100 flips. This is different from regression toward the mean. In the first place, the frequency of heads over the second 100 flips is equally likely to be closer to or farther from the mean than the frequency of heads over the first 100 flips. It is a fallacy to think the second 100 flips has a tendency to even out the total. If the first 100 flips produces 5 heads more than expected, we expect to have 5 heads more than expected at the end of 200 flips as well. The average number of heads regresses toward the mean, but the number of heads does not. This regression is toward the true mean, not the mean of the first 100 flips.
In the student test example above, it was assumed implicitly that what was being measured did not change between the two measurements. But suppose it was a pass/fail course and you had to score above 70 on both tests to pass. Then the students who scored under 70 the first time would have no incentive to do well, and might score worse on average the second time. The students just over 70, on the other hand, would have a strong incentive to study overnight and concentrate while taking the test. In that case you might see movement away from 70, scores below it getting lower and scores above it getting higher. It is possible for changes between the measurement times to augment, offset or reverse the statistical tendency to regress toward the mean. Do not confuse causal regression toward the mean (or away from it) with the statistical phenomenon.
Do not think of statistical regression toward the mean as a causal phenomenon. If you are the student with the worst score on the first day's exam, there is no invisible hand to lift up your score on the second day, without effort from you. If you know you scored in line with your ability, you are equally likely to score better or worse on the second test. On average the worst scorers improve, but that's only true because the worst scorers are more likely to have been unlucky than lucky. You know how lucky or unlucky you were, so regression toward the mean is irrelevant from your point of view.
Although individual measurements regress toward the mean, the second sample of measurements will be no closer to the mean than the first. Consider the students again. Suppose their tendency is to regress 10% of the way toward the mean of 80, so a student who scored 100 the first day is expected to score 98 the second day, and a student who scored 70 the first day is expected to score 71 the second day. Those expectations are closer to the mean, on average, than the first day scores. But the second day scores will vary around their expectations, some will be higher and some will be lower. This will make the second set of measurements farther from the mean, on average, than their expectations. The effect is the exact reverse of regression toward the mean, and exactly offsets it. So for every individual, we expect the second score to be closer to the mean than the first score, but for all individuals, we expect the average distance from the mean to be the same on both sets of measurements.
Related to the point above, regression toward the mean works equally well in both directions. We expect the student with the highest test score on the second day to have done worse on the first day. And if we compare the best student on the first day to the best student on the second day, regardless of whether it is the same individual or not, there is no tendency to regress toward the mean. We expect the best scores on both days to be equally far from the mean.
Also related to the above point, if we pick a point close to the mean on the first set of measurements, we may expect it to be farther from the mean on the second set. The expected value of the second measurement is closer to the mean than the point, but the measurement error will move it on average farther away. That is, the expected value of the distance from the mean on the second measurement is greater than the distance from the mean on the first measurement.
[edit] Regression toward everything
Notice that in the informal explanation given above for the phenomenon, there was nothing special about the mean. We could pick any point within the sample range and make the same argument: students who scored above this value were more likely to have been lucky than unlucky, students who scored below this value were more likely to have been unlucky than lucky. How can individuals regress toward every point in the sample range at once? The answer is each individual is pulled toward every point in the sample range, but to different degrees.
For a physical analogy, every mass in the solar system is pulled toward every other mass by gravitation, but the net effect for planets is to be pulled toward the center of mass of the entire solar system. This illustrates an important point. Individuals on Earth at noon are pulled toward the Earth, away from the Sun and the center of mass of the solar system. Similarly, an individual in a sample might be pulled toward a subgroup mean more strongly than to the sample mean, and even pulled away from the sample mean. Consider, for example, the pitcher with the highest batting average in the National League by the All-Star break, and assume his batting average is below the average for all National League players. His batting average over the second half of the season will regress up toward the mean of all players, and down toward the mean of all pitchers. For that matter, if he is left-handed he is pulled toward the mean of all left-handers, if he is a rookie he is pulled to the mean of all rookies, and so on. Which of these effects dominates depends on the data under consideration.
The concept does not apply, however, to supersets. While the pitcher above may be pulled to the mean of all humans, or the mean of all things made of matter, our sample does not give us estimates of those means.
In general, you can expect the net effect of regressions toward all points to pull an individual toward the closest mode of the distribution. If you have information about subgroups, and the subgroup means are far apart relative to the differences between individuals, you can expect individuals to be pulled toward subgroup means, even if those do not show up as modes of the distribution. For unimodal distributions, without strong subgroup effects or asymmetries, individuals will likely be pulled toward the mean, median and mode which should be close together. For bimodal and multimodal distributions, asymmetric distributions or data with strong subgroup effects, regression toward the mean should be applied with caution.
[edit] Regression fallacies
Misunderstandings of the principle (known as "regression fallacies") have repeatedly led to mistaken claims in the scientific literature.
An extreme example is Horace Secrist's 1933 book The Triumph of Mediocrity in Business, in which the statistics professor collected mountains of data to prove that the profit rates of competitive businesses tend toward the average over time. In fact, there is no such effect; the variability of profit rates is almost constant over time. Secrist had only described the common regression toward the mean. One exasperated reviewer, Harold Hotelling, likened the book to "proving the multiplication table by arranging elephants in rows and columns, and then doing the same for numerous other kinds of animals".[5]
The calculation and interpretation of "improvement scores" on standardized educational tests in Massachusetts probably provides another example of the regression fallacy. In 1999, schools were given improvement goals. For each school, the Department of Education tabulated the difference in the average score achieved by students in 1999 and in 2000. It was quickly noted that most of the worst-performing schools had met their goals, which the Department of Education took as confirmation of the soundness of their policies. However, it was also noted that many of the supposedly best schools in the Commonwealth, such as Brookline High School (with 18 National Merit Scholarship finalists) were declared to have failed. As in many cases involving statistics and public policy, the issue is debated, but "improvement scores" were not announced in subsequent years and the findings appear to be a case of regression to the mean.
The psychologist Daniel Kahneman referred to regression to the mean in his speech when he won the 2002 Bank of Sweden prize for economics.
| “ | I had the most satisfying Eureka experience of my career while attempting to teach flight instructors that praise is more effective than punishment for promoting skill-learning. When I had finished my enthusiastic speech, one of the most seasoned instructors in the audience raised his hand and made his own short speech, which began by conceding that positive reinforcement might be good for the birds, but went on to deny that it was optimal for flight cadets. He said, "On many occasions I have praised flight cadets for clean execution of some aerobatic maneuver, and in general when they try it again, they do worse. On the other hand, I have often screamed at cadets for bad execution, and in general they do better the next time. So please don't tell us that reinforcement works and punishment does not, because the opposite is the case." This was a joyous moment, in which I understood an important truth about the world: because we tend to reward others when they do well and punish them when they do badly, and because there is regression to the mean, it is part of the human condition that we are statistically punished for rewarding others and rewarded for punishing them. I immediately arranged a demonstration in which each participant tossed two coins at a target behind his back, without any feedback. We measured the distances from the target and could see that those who had done best the first time had mostly deteriorated on their second try, and vice versa. But I knew that this demonstration would not undo the effects of lifelong exposure to a perverse contingency. | ” |
UK law enforcement policies have encouraged the visible siting of static or mobile speed cameras at accident blackspots. This policy was justified by a perception that there is a corresponding reduction in serious road traffic accidents after a camera is set up. However, statisticians have pointed out that, although there is a net benefit in lives saved, failure to take into account the effects of regression to the mean results in the beneficial effects' being overstated. It is thus claimed that some of the money currently spent on traffic cameras could be more productively directed elsewhere.[6]
Statistical analysts have long recognized the effect of regression to the mean in sports; they even have a special name for it: the "Sophomore Slump." For example, Carmelo Anthony of the NBA's Denver Nuggets had an outstanding rookie season in 2004. It was so outstanding, in fact, that he couldn't possibly be expected to repeat it: in 2005, Anthony's numbers had dropped from his rookie season. The reasons for the "sophomore slump" abound, as sports are all about adjustment and counter-adjustment, but luck-based excellence as a rookie is as good a reason as any.
Regression to the mean in sports performance may be the reason for the "Sports Illustrated Cover Jinx" and the "Madden Curse." John Hollinger has an alternate name for the law of regression to the mean: the "fluke rule," while Bill James calls it the "Plexiglass Principle."
Because popular lore has focused on "regression toward the mean" as an account of declining performance of athletes from one season to the next, it has usually overlooked the fact that such regression can also account for improved performance. For example, if one looks at the batting average of Major League Baseball players in one season, those whose batting average was above the league mean tend to regress downward toward the mean the following year, while those whose batting average was below the mean tend to progress upward toward the mean the following year.[7]
[edit] Mathematics
Let x1, x2, . . .,xn be the first set of measurements and y1, y2, . . .,yn be the second set. Regression toward the mean tells us for all i, the expected value of yi is closer to 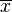 (the mean of the xi's) than xi is. We can write this as:
(the mean of the xi's) than xi is. We can write this as:

Where E() denotes the expectation operator. We can also write:

which is stronger than the first inequality because it requires that the expected value of yi is on the same side of the mean as xi. A natural way to test this is to look at the values of:

in the sample. Taking an arithmetic mean is not a good idea, because  might be zero. Even if it's only close to zero, those points could dominate the calculation, when we're really concerned about larger movements of points farther from the mean. Suppose instead we take a weighted mean, weighted by
might be zero. Even if it's only close to zero, those points could dominate the calculation, when we're really concerned about larger movements of points farther from the mean. Suppose instead we take a weighted mean, weighted by  :
:

which can be rewritten:

or:

which is the well-known formula for the regression co-efficient β. Therefore, asserting that there is regression toward the mean can be interpreted as asserting:

This will generally be true of two sets of measurements on the same sample. We would expect the standard deviation of the two sets of measurements to be the same, so the regression co-efficient β is equal to the correlation co-efficient ρ. That's enough to tell us  since
since  . If the measurements are not perfect, we expect β < 1. However, if the measurements have any information content at all, ρ > 0, so β > 0. ρ = 1 corresponds to the case of perfect measurement while ρ = 0 corresponds to the case of the measurement being all error.
. If the measurements are not perfect, we expect β < 1. However, if the measurements have any information content at all, ρ > 0, so β > 0. ρ = 1 corresponds to the case of perfect measurement while ρ = 0 corresponds to the case of the measurement being all error.
[edit] See also
[edit] Notes
- ^ Howard Raiffa and Robert Schlaifer, Applied Statistical Decision Theory, Wiley-Interscience (2000) ISBN 978-0471383499
- ^ George Casella and Roger L. Berger, Statistical Inference, Duxbury Press (2001) ISBN 978-0534243128
- ^ Reversion to the mean at MathWorld
- ^ Galton, F. (1886). "Regression Toward Mediocrity in Hereditary Stature". Nature.
- ^ Hotelling, H. (1933). Review of The triumph of mediocrity in business by Secrist, H., Journal of the American Statistical Association, 28, 433-435.
- ^ The Times, 16 December 2005 Speed camera benefits overrated
- ^ For an illustration see Nate Silver, "Randomness: Catch the Fever!", Baseball Prospectus, May 14, 2003.
[edit] References
- J.M. Bland and D.G. Altman (June 1994). "Statistic Notes: Regression towards the mean". British Medical Journal 308: 1499. PMID 8019287. http://bmj.bmjjournals.com/cgi/content/full/308/6942/1499. Article, including a diagram of Galton's original data.
- Francis Galton (1886). "Regression Towards Mediocrity in Hereditary Stature". Journal of the Anthropological Institute 15: 246–263. http://galton.org/essays/1880-1889/galton-1886-jaigi-regression-stature.pdf.
- Stephen M. Stigler (1999). Statistics on the Table. Harvard University Press. See Chapter 9.
[edit] External links
- A non-mathematical explanation of regression toward the mean.
- A simulation of regression toward the mean.
- Amanda Wachsmuth, Leland Wilkinson, Gerard E. Dallal. Galton's Bend: An Undiscovered Nonlinearity in Galton's Family Stature Regression Data and a Likely Explanation Based on Pearson and Lee's Stature Data (A modern look at Galton's analysis.)
- Massachusetts standardized test scores, interpreted by a statistician as an example of regression: see discussion in sci.stat.edu and its continuation.
- Kahneman's Nobel speech [1]
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||

