Kruskal's algorithm
From Wikipedia, the free encyclopedia
| Graph search algorithms |
|---|
| Search |
Kruskal's algorithm is an algorithm in graph theory that finds a minimum spanning tree for a connected weighted graph. This means it finds a subset of the edges that forms a tree that includes every vertex, where the total weight of all the edges in the tree is minimized. If the graph is not connected, then it finds a minimum spanning forest (a minimum spanning tree for each connected component). Kruskal's algorithm is an example of a greedy algorithm.
It works as follows:
- create a forest F (a set of trees), where each vertex in the graph is a separate tree
- create a set S containing all the edges in the graph
- while S is nonempty
- remove an edge with minimum weight from S
- if that edge connects two different trees, then add it to the forest, combining two trees into a single tree
- otherwise discard that edge
At the termination of the algorithm, the forest has only one component and forms a minimum spanning tree of the graph.
This algorithm first appeared in Proceedings of the American Mathematical Society, pp. 48–50 in 1956, and was written by Joseph Kruskal.
Other algorithms for this problem include Prim's algorithm, Reverse-Delete algorithm, and Borůvka's algorithm.
Contents |
[edit] Performance
Where E is the number of edges in the graph and V is the number of vertices, Kruskal's algorithm can be shown to run in O(E log E) time, or equivalently, O(E log V) time, all with simple data structures. These running times are equivalent because:
- E is at most V2 and logV2 = 2logV is O(log V).
- If we ignore isolated vertices, which will each be their own component of the minimum spanning forest, V ≤ E+1, so log V is O(log E).
We can achieve this bound as follows: first sort the edges by weight using a comparison sort in O(E log E) time; this allows the step "remove an edge with minimum weight from S" to operate in constant time. Next, we use a disjoint-set data structure to keep track of which vertices are in which components. We need to perform O(E) operations, two 'find' operations and possibly one union for each edge. Even a simple disjoint-set data structure such as disjoint-set forests with union by rank can perform O(E) operations in O(E log V) time. Thus the total time is O(E log E) = O(E log V).
Provided that the edges are either already sorted or can be sorted in linear time (for example with counting sort or radix sort), the algorithm can use more sophisticated disjoint-set data structures to run in O(E α(V)) time, where α is the extremely slowly-growing inverse of the single-valued Ackermann function.
[edit] Example
| Image | Description |
|---|---|
 |
This is our original graph. The numbers near the arcs indicate their weight. None of the arcs are highlighted. |
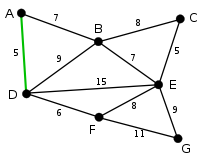 |
AD and CE are the shortest arcs, with length 5, and AD has been arbitrarily chosen, so it is highlighted. |
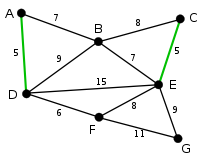 |
CE is now the shortest arc that does not form a cycle, with length 5, so it is highlighted as the second arc. |
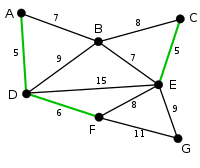 |
The next arc, DF with length 6, is highlighted using much the same method. |
 |
The next-shortest arcs are AB and BE, both with length 7. AB is chosen arbitrarily, and is highlighted. The arc BD has been highlighted in red, because there already exists a path (in green) between B and D, so it would form a cycle (ABD) if it were chosen. |
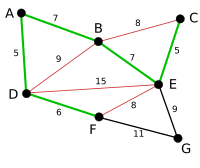 |
The process continues to highlight the next-smallest arc, BE with length 7. Many more arcs are highlighted in red at this stage: BC because it would form the loop BCE, DE because it would form the loop DEBA, and FE because it would form FEBAD. |
 |
Finally, the process finishes with the arc EG of length 9, and the minimum spanning tree is found. |
[edit] Proof of correctness
The proof consists of two parts. First, it is proved that the algorithm produces a spanning tree. Second, it is proved that the constructed spanning tree is of minimal weight.
[edit] Spanning tree
Let P be a connected, weighted graph and let Y be the subgraph of P produced by the algorithm. Y cannot have a cycle, since the last edge added to that cycle would have been within one subtree and not between two different trees. Y cannot be disconnected, since the first encountered edge that joins two components of Y would have been added by the algorithm. Thus, Y is a spanning tree of P.
[edit] Minimality
The proof is by reductio ad absurdum. Assume that Y is not a minimal spanning tree and among all minimum weight spanning trees pick Y1 which has the smallest number of edges which are not in Y. Consider the edge e which was first to be added by the algorithm to Y of those which are not in Y1.
 has a cycle. Being a tree, Y cannot contain all edges of this cycle. Therefore this cycle contains an edge f which is not in Y. The graph
has a cycle. Being a tree, Y cannot contain all edges of this cycle. Therefore this cycle contains an edge f which is not in Y. The graph  is also a spanning tree and therefore its weight cannot be less than the weight of Y1 and hence the weight of e cannot be less than the weight of f. Y2 By another application of the reductio ad absurdum we shall prove that the weight of f cannot be less than that of e. Assume the contrary and remember that the edges are considered for addition to Y in the order of non-decreasing weight. Therefore f would have been considered in the main loop before e, i.e., it would be tested for the addition to a subforest
is also a spanning tree and therefore its weight cannot be less than the weight of Y1 and hence the weight of e cannot be less than the weight of f. Y2 By another application of the reductio ad absurdum we shall prove that the weight of f cannot be less than that of e. Assume the contrary and remember that the edges are considered for addition to Y in the order of non-decreasing weight. Therefore f would have been considered in the main loop before e, i.e., it would be tested for the addition to a subforest  (recall that e is the first edge of Y which is not in Y1). But f does not create a cycle in Y1, therefore it cannot create a cycle in Y3, and it would have been added to the growing tree.
(recall that e is the first edge of Y which is not in Y1). But f does not create a cycle in Y1, therefore it cannot create a cycle in Y3, and it would have been added to the growing tree.
The above implies that the weights of e and f are equal, and hence Y2 is also a minimal spanning tree. But Y2 has one more edge in common with Y than Y1, which contradicts to the choice of Y1, Q.E.D.
[edit] Pseudocode
1 function Kruskal(G)
2 for each vertex v in G do
3 Define an elementary cluster C(v) ← {v}.
4 Initialize a priority queue Q to contain all edges in G, using the weights as keys.
5 Define a tree T ← Ø //T will ultimately contain the edges of the MST
6 // n is total number of vertices
7 while T has fewer than n-1 edges do
8 // edge u,v is the minimum weighted route from/to v
9 (u,v) ← Q.removeMin()
10 // prevent cycles in T. add u,v only if T does not already contain a path between u and v.
11 // Note that the cluster contains more than one vertex only if an edge containing a pair of
12 // the vertices has been added to the tree.
13 Let C(v) be the cluster containing v, and let C(u) be the cluster containing u.
14 if C(v) ≠ C(u) then
15 Add edge (v,u) to T.
16 Merge C(v) and C(u) into one cluster, that is, union C(v) and C(u).
17 return tree T
[edit] References
- Joseph. B. Kruskal: On the Shortest Spanning Subtree of a Graph and the Traveling Salesman Problem. In: Proceedings of the American Mathematical Society, Vol 7, No. 1 (Feb, 1956), pp. 48–50
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Section 23.2: The algorithms of Kruskal and Prim, pp.567–574.
- Michael T. Goodrich and Roberto Tamassia. Data Structures and Algorithms in Java, Fourth Edition. John Wiley & Sons, Inc., 2006. ISBN 0-471-73884-0. Section 13.7.1: Kruskal's Algorithm, pp.632.

