Database normalization
From Wikipedia, the free encyclopedia
In the field of relational database design, normalization is a systematic way of ensuring that a database structure is suitable for general-purpose querying and free of certain undesirable characteristics—insertion, update, and deletion anomalies—that could lead to a loss of data integrity.[1] E.F. Codd, the inventor of the relational model, introduced the concept of normalization and what we now know as the first normal form in 1970.[2] Codd went on to define the second and third normal forms in 1971[3]; and Codd and Raymond F. Boyce defined the Boyce-Codd normal form in 1974 .[4] Higher normal forms were defined by other theorists in subsequent years, the most recent being the sixth normal form introduced by Chris Date, Hugh Darwen, and Nikos Lorentzos in 2002.[5]
Informally, a relational database table (the computerized representation of a relation) is often described as "normalized" if it is in the third normal form (3NF).[6] Most 3NF tables are free of insertion, update, and deletion anomalies, i.e. in most cases 3NF tables adhere to BCNF, 4NF, and 5NF (but typically not 6NF).
A standard piece of database design guidance is that the designer should begin by fully normalizing the design, and selectively denormalize only in places where doing so is absolutely necessary to address performance issues.[7] However, some modeling disciplines, such as the dimensional modeling approach to data warehouse design, explicitly recommend non-normalized designs, i.e. designs that in large part do not adhere to 3NF.[8]
Contents |
[edit] Objectives of normalization
A basic objective of the first normal form defined by Codd in 1970 was to permit data to be queried and manipulated using a "universal data sub-language" grounded in first-order logic.[9] (SQL is an example of such a data sub-language, albeit one that Codd regarded as seriously flawed.)[10] Querying and manipulating the data within an unnormalized data structure, such as the following non-1NF representation of customers' credit card transactions, involves more complexity than is really necessary:
| Customer | Transactions
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Jones |
|
|||||||||
| Wilkins |
|
|||||||||
| Stevens |
|
To each customer there corresponds a repeating group of transactions. The automated evaluation of any query relating to customers' transactions therefore would broadly involve two stages:
- Unpacking one or more customers' groups of transactions allowing the individual transactions in a group to be examined, and
- Deriving a query result based on the results of the first stage
For example, in order to find out the monetary sum of all transactions that occurred in October 2003 for all customers, the system would have to know that it must first unpack the Transactions group of each customer, then sum the Amounts of all transactions thus obtained where the Date of the transaction falls in October 2003.
One of Codd's important insights was that this structural complexity could always be removed completely, leading to much greater power and flexibility in the way queries could be formulated (by users and applications) and evaluated (by the DBMS). The normalized equivalent of the structure above would look like this:
| Customer | Tr. ID | Date | Amount |
|---|---|---|---|
| Jones | 12890 | 14-Oct-2003 | -87 |
| Jones | 12904 | 15-Oct-2003 | -50 |
| Wilkins | 12898 | 14-Oct-2003 | -21 |
| Stevens | 12907 | 15-Oct-2003 | -18 |
| Stevens | 14920 | 20-Nov-2003 | -70 |
| Stevens | 15003 | 27-Nov-2003 | -60 |
Now each row represents an individual credit card transaction, and the DBMS can obtain the answer of interest, simply by finding all rows with a Date falling in October, and summing their Amounts. All of the values in the data structure are on an equal footing: they are all exposed to the DBMS directly, and can directly participate in queries, whereas in the previous situation some values were embedded in lower-level structures that had to be handled specially. Accordingly, the normalized design lends itself to general-purpose query processing, whereas the unnormalized design does not.
The objectives of normalization beyond 1NF were stated as follows by Codd:
- 1. To free the collection of relations from undesirable insertion, update and deletion dependencies;
- 2. To reduce the need for restructuring the collection of relations as new types of data are introduced, and thus increase the life span of application programs;
- 3. To make the relational model more informative to users;
- 4. To make the collection of relations neutral to the query statistics, where these statistics are liable to change as time goes by.
- —E.F. Codd, "Further Normalization of the Data Base Relational Model"[11]
The sections below give details of each of these objectives.
[edit] Free the database of modification anomalies


When an attempt is made to modify (update, insert into, or delete from) a table, undesired side-effects may follow. Not all tables can suffer from these side-effects; rather, the side-effects can only arise in tables that have not been sufficiently normalized. An insufficiently normalized table might have one or more of the following characteristics:
- The same information can be expressed on multiple rows; therefore updates to the table may result in logical inconsistencies. For example, each record in an "Employees' Skills" table might contain an Employee ID, Employee Address, and Skill; thus a change of address for a particular employee will potentially need to be applied to multiple records (one for each of his skills). If the update is not carried through successfully—if, that is, the employee's address is updated on some records but not others—then the table is left in an inconsistent state. Specifically, the table provides conflicting answers to the question of what this particular employee's address is. This phenomenon is known as an update anomaly.
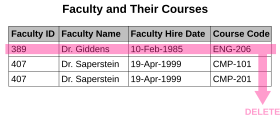
- There are circumstances in which certain facts cannot be recorded at all. For example, each record in a "Faculty and Their Courses" table might contain a Faculty ID, Faculty Name, Faculty Hire Date, and Course Code—thus we can record the details of any faculty member who teaches at least one course, but we cannot record the details of a newly-hired faculty member who has not yet been assigned to teach any courses. This phenomenon is known as an insertion anomaly.
- There are circumstances in which the deletion of data representing certain facts necessitates the deletion of data representing completely different facts. The "Faculty and Their Courses" table described in the previous example suffers from this type of anomaly, for if a faculty member temporarily ceases to be assigned to any courses, we must delete the last of the records on which that faculty member appears. This phenomenon is known as a deletion anomaly.
[edit] Minimize redesign when extending the database structure
When a fully normalized database structure is extended to allow it to accommodate new types of data, the pre-existing aspects of the database structure can remain largely or entirely unchanged. As a result, applications interacting with the database are minimally affected.
[edit] Make the data model more informative to users
Normalized tables, and the relationship between one normalized table and another, mirror real-world concepts and their interrelationships.
[edit] Avoid bias towards any particular pattern of querying
Normalized tables are suitable for general-purpose querying. This means any queries against these tables, including future queries whose details cannot be anticipated, are supported. In contrast, tables that are not normalized lend themselves to some types of queries, but not others.
[edit] Background to normalization: definitions
- Functional dependency: Attribute B has a functional dependency on attribute A (i.e., A → B) if, for each value of attribute A, there is exactly one value of attribute B. If value of A is repeating in tuples then value of B will also repeat. In our example, Employee Address has a functional dependency on Employee ID, because a particular Employee ID value corresponds to one and only one Employee Address value. (Note that the reverse need not be true: several employees could live at the same address and therefore one Employee Address value could correspond to more than one Employee ID. Employee ID is therefore not functionally dependent on Employee Address.) An attribute may be functionally dependent either on a single attribute or on a combination of attributes. It is not possible to determine the extent to which a design is normalized without understanding what functional dependencies apply to the attributes within its tables; understanding this, in turn, requires knowledge of the problem domain. For example, an Employer may require certain employees to split their time between two locations, such as New York City and London, and therefore want to allow Employees to have more than one Employee Address. In this case, Employee Address would no longer be functionally dependent on Employee ID.
Another way to look at the above is by reviewing basic mathematical functions:
Let F(x) be a mathematical function of one independent variable. The independent variable is analogous to the attribute A. The dependent variable (or the dependent attribute using the lingo above), and hence the term functional dependency, is the value of F(A); A is an independent attribute. As we know, mathematical functions can have only one output. Notationally speaking, it is common to express this relationship in mathematics as F(A) = B; or, B → F(A).
There are also functions of more than one independent variable—commonly, this is referred to as multivariable functions. This idea represents an attribute being functionally dependent on a combination of attributes. Hence, F(x,y,z) contains three independent variables, or independent attributes, and one dependent attribute, namely, F(x,y,z). In multivariable functions, there can only be one output, or one dependent variable, or attribute.
- Trivial functional dependency
- A trivial functional dependency is a functional dependency of an attribute on a superset of itself. {Employee ID, Employee Address} → {Employee Address} is trivial, as is {Employee Address} → {Employee Address}.
- Full functional dependency
- An attribute is fully functionally dependent on a set of attributes X if it is
- functionally dependent on X, and
- not functionally dependent on any proper subset of X. {Employee Address} has a functional dependency on {Employee ID, Skill}, but not a full functional dependency, because it is also dependent on {Employee ID}.
- Transitive dependency
- A transitive dependency is an indirect functional dependency, one in which X→Z only by virtue of X→Y and Y→Z.
- Multivalued dependency
- A multivalued dependency is a constraint according to which the presence of certain rows in a table implies the presence of certain other rows.
- Join dependency
- A table T is subject to a join dependency if T can always be recreated by joining multiple tables each having a subset of the attributes of T.
- Superkey
- A superkey is an attribute or set of attributes that uniquely identifies rows within a table; in other words, two distinct rows are always guaranteed to have distinct superkeys. {Employee ID, Employee Address, Skill} would be a superkey for the "Employees' Skills" table; {Employee ID, Skill} would also be a superkey.
- Candidate key
- A candidate key is a minimal superkey, that is, a superkey for which we can say that no proper subset of it is also a superkey. {Employee Id, Skill} would be a candidate key for the "Employees' Skills" table.
- Non-prime attribute
- A non-prime attribute is an attribute that does not occur in any candidate key. Employee Address would be a non-prime attribute in the "Employees' Skills" table.
- Primary key
- Most DBMSs require a table to be defined as having a single unique key, rather than a number of possible unique keys. A primary key is a key which the database designer has designated for this purpose.
[edit] Normal forms
The normal forms (abbrev. NF) of relational database theory provide criteria for determining a table's degree of vulnerability to logical inconsistencies and anomalies. The higher the normal form applicable to a table, the less vulnerable it is to inconsistencies and anomalies. Each table has a "highest normal form" (HNF): by definition, a table always meets the requirements of its HNF and of all normal forms lower than its HNF; also by definition, a table fails to meet the requirements of any normal form higher than its HNF.
The normal forms are applicable to individual tables; to say that an entire database is in normal form n is to say that all of its tables are in normal form n.
Newcomers to database design sometimes suppose that normalization proceeds in an iterative fashion, i.e. a 1NF design is first normalized to 2NF, then to 3NF, and so on. This is not an accurate description of how normalization typically works. A sensibly designed table is likely to be in 3NF on the first attempt; furthermore, if it is 3NF, it is overwhelmingly likely to have an HNF of 5NF. Achieving the "higher" normal forms (above 3NF) does not usually require an extra expenditure of effort on the part of the designer, because 3NF tables usually need no modification to meet the requirements of these higher normal forms.
The main normal forms are summarized below.
| Normal form | Defined by | Brief definition |
|---|---|---|
| First normal form (1NF) | Two versions: E.F. Codd (1970), C.J. Date (2003)[12] | Table faithfully represents a relation and has no "repeating groups" |
| Second normal form (2NF) | E.F. Codd (1971)[13] | No non-prime attribute in the table is functionally dependent on a part (proper subset) of a candidate key |
| Third normal form (3NF) | E.F. Codd (1971)[14]; see also Carlo Zaniolo's equivalent but differently-expressed definition (1982)[15] | Every non-prime attribute is non-transitively dependent on every key of the table |
| Boyce-Codd normal form (BCNF) | Raymond F. Boyce and E.F. Codd (1974)[16] | Every non-trivial functional dependency in the table is a dependency on a superkey |
| Fourth normal form (4NF) | Ronald Fagin (1977)[17] | Every non-trivial multivalued dependency in the table is a dependency on a superkey |
| Fifth normal form (5NF) | Ronald Fagin (1979)[18] | Every non-trivial join dependency in the table is implied by the superkeys of the table |
| Domain/key normal form (DKNF) | Ronald Fagin (1981)[19] | Every constraint on the table is a logical consequence of the table's domain constraints and key constraints |
| Sixth normal form (6NF) | Chris Date, Hugh Darwen, and Nikos Lorentzos (2002)[20] | Table features no non-trivial join dependencies at all (with reference to generalized join operator) |
[edit] Denormalization
Databases intended for Online Transaction Processing (OLTP) are typically more normalized than databases intended for Online Analytical Processing (OLAP). OLTP Applications are characterized by a high volume of small transactions such as updating a sales record at a super market checkout counter. The expectation is that each transaction will leave the database in a consistent state. By contrast, databases intended for OLAP operations are primarily "read mostly" databases. OLAP applications tend to extract historical data that has accumulated over a long period of time. For such databases, redundant or "denormalized" data may facilitate business intelligence applications. Specifically, dimensional tables in a star schema often contain denormalized data. The denormalized or redundant data must be carefully controlled during ETL processing, and users should not be permitted to see the data until it is in a consistent state. The normalized alternative to the star schema is the snowflake schema. It has never been proven that this denormalization itself provides any increase in performance, or if the concurrent removal of data constraints is what increases the performance. In many cases, the need for denormalization has waned as computers and RDBMS software have become more powerful, but since data volumes have generally increased along with hardware and software performance, OLAP databases often still use denormalized schemas.
Denormalization is also used to improve performance on smaller computers as in computerized cash-registers and mobile devices, since these may use the data for look-up only (e.g. price lookups). Denormalization may also be used when no RDBMS exists for a platform (such as Palm), or no changes are to be made to the data and a swift response is crucial.
[edit] Non-first normal form (NF² or N1NF)
In recognition that denormalization can be deliberate and useful, the non-first normal form is a definition of database designs which do not conform to the first normal form, by allowing "sets and sets of sets to be attribute domains" (Schek 1982). This extension is a (non-optimal) way of implementing hierarchies in relations. Some academics have dubbed this practitioner developed method, "First Ab-normal Form"; Codd defined a relational database as using relations, so any table not in 1NF could not be considered to be relational.
Consider the following table:
| Person | Favorite Colors |
|---|---|
| Bob | blue, red |
| Jane | green, yellow, red |
Assume a person has several favorite colors. Obviously, favorite colors consist of a set of colors modeled by the given table.
To transform this NF² table into a 1NF an "unnest" operator is required which extends the relational algebra of the higher normal forms (one would allow "colors" to be its own table). The reverse operator is called "nest" which is not always the mathematical inverse of "unnest", although "unnest" is the mathematical inverse to "nest". Another constraint required is for the operators to be bijective, which is covered by the Partitioned Normal Form (PNF).
[edit] Further reading
- Litt's Tips: Normalization
- Date, C. J. (1999), An Introduction to Database Systems (8th ed.). Addison-Wesley Longman. ISBN 0-321-19784-4.
- Kent, W. (1983) A Simple Guide to Five Normal Forms in Relational Database Theory, Communications of the ACM, vol. 26, pp. 120–125
- Date, C.J., & Darwen, H., & Pascal, F. Database Debunkings
- H.-J. Schek, P. Pistor Data Structures for an Integrated Data Base Management and Information Retrieval System
[edit] Notes and references
- ^ Codd, E.F. The Relational Model for Database Management: Version 2. Addison-Wesley (1990), p. 271
- ^ Codd, E.F. (June 1970). "A Relational Model of Data for Large Shared Data Banks". Communications of the ACM 13 (6): 377–387. doi:. http://www.acm.org/classics/nov95/toc.html.
- ^ Codd, E.F. "Further Normalization of the Data Base Relational Model." (Presented at Courant Computer Science Symposia Series 6, "Data Base Systems," New York City, May 24th-25th, 1971.) IBM Research Report RJ909 (August 31st, 1971). Republished in Randall J. Rustin (ed.), Data Base Systems: Courant Computer Science Symposia Series 6. Prentice-Hall, 1972.
- ^ Codd, E. F. "Recent Investigations into Relational Data Base Systems." IBM Research Report RJ1385 (April 23rd, 1974). Republished in Proc. 1974 Congress (Stockholm, Sweden, 1974). New York, N.Y.: North-Holland (1974).
- ^ C.J. Date, Hugh Darwen, Nikos Lorentzos. Temporal Data and the Relational Model. Morgan Kaufmann (2002), p. 176
- ^ C.J. Date. An Introduction to Database Systems. Addison-Wesley (1999), p. 290
- ^ Chris Date, for example, writes: "I believe firmly that anything less than a fully normalized design is strongly contraindicated ... [Y]ou should "denormalize" only as a last resort. That is, you should back off from a fully normalized design only if all other strategies for improving performance have somehow failed to meet requirements." Date, C.J. Database in Depth: Relational Theory for Practitioners. O'Reilly (2005), p. 152.
- ^ Ralph Kimball, for example, writes: "The use of normalized modeling in the data warehouse presentation area defeats the whole purpose of data warehousing, namely, intuitive and high-performance retrieval of data." Kimball, Ralph. The Data Warehouse Toolkit, 2nd Ed.. Wiley Computer Publishing (2002), p. 11.
- ^ "The adoption of a relational model of data ... permits the development of a universal data sub-language based on an applied predicate calculus. A first-order predicate calculus suffices if the collection of relations is in [first] normal form. Such a language would provide a yardstick of linguistic power for all other proposed data languages, and would itself be a strong candidate for embedding (with appropriate syntactic modification) in a variety of host Ianguages (programming, command- or problem-oriented)." Codd, "A Relational Model of Data for Large Shared Data Banks", p. 381
- ^ Codd, E.F. Chapter 23, "Serious Flaws in SQL", in The Relational Model for Database Management: Version 2. Addison-Wesley (1990), p. 371-389
- ^ Codd, E.F. "Further Normalization of the Data Base Relational Model", p. 34
- ^ Date, C. J. "What First Normal Form Really Means" in Date on Database: Writings 2000-2006 (Springer-Verlag, 2006), pp. 127-128.
- ^ Codd, E.F. "Further Normalization of the Data Base Relational Model." (Presented at Courant Computer Science Symposia Series 6, "Data Base Systems," New York City, May 24-25, 1971.) IBM Research Report RJ909 (August 31st, 1971). Republished in Randall J. Rustin (ed.), Data Base Systems: Courant Computer Science Symposia Series 6. Prentice-Hall, 1972.
- ^ Codd, E.F. "Further Normalization of the Data Base Relational Model." (Presented at Courant Computer Science Symposia Series 6, "Data Base Systems," New York City, May 24-25, 1971.) IBM Research Report RJ909 (August 31, 1971). Republished in Randall J. Rustin (ed.), Data Base Systems: Courant Computer Science Symposia Series 6. Prentice-Hall, 1972.
- ^ Zaniolo, Carlo. "A New Normal Form for the Design of Relational Database Schemata." ACM Transactions on Database Systems 7(3), September 1982.
- ^ Codd, E. F. "Recent Investigations into Relational Data Base Systems." IBM Research Report RJ1385 (April 23, 1974). Republished in Proc. 1974 Congress (Stockholm, Sweden, 1974). New York, N.Y.: North-Holland (1974).
- ^ Fagin, Ronald (September 1977). "Multivalued Dependencies and a New Normal Form for Relational Databases". ACM Transactions on Database Systems 2 (1): 267. doi:. http://www.almaden.ibm.com/cs/people/fagin/tods77.pdf.
- ^ Ronald Fagin. "Normal Forms and Relational Database Operators". ACM SIGMOD International Conference on Management of Data, May 31-June 1, 1979, Boston, Mass. Also IBM Research Report RJ2471, Feb. 1979.
- ^ Ronald Fagin (1981) A Normal Form for Relational Databases That Is Based on Domains and Keys, Communications of the ACM, vol. 6, pp. 387-415
- ^ C.J. Date, Hugh Darwen, Nikos Lorentzos. Temporal Data and the Relational Model. Morgan Kaufmann (2002), p. 176
- Paper: "Non First Normal Form Relations" by G. Jaeschke, H. -J Schek ; IBM Heidelberg Scientific Center. -> Paper studying normalization and denormalization operators nest and unnest as mildly described at the end of this wiki page. The paper contains the Formalization through Set Theory of 1NF and NF^2 relations.
[edit] See also
- Canonical form
- Optimization
- Refactoring
- Business rules
- Aspect (computer science)
- Cross-cutting concern
[edit] External links
- Database Normalization Basics by Mike Chapple (About.com)
- Database Normalization Intro, Part 2
- An Introduction to Database Normalization by Mike Hillyer.
- Normalization by ITS, University of Texas.
- Rules of Data Normalization by Data Model.org
- A tutorial on the first 3 normal forms by Fred Coulson
- DB Normalization Examples
- Description of the database normalization basics by Microsoft
- Database Normalization and Design Techniques by Barry Wise, recommended reading for the Harvard MIS.
|
||||||||||||||||||||
|
||||||||

