Independent component analysis
From Wikipedia, the free encyclopedia
|
|
This article is in need of attention from an expert on the subject. WikiProject Statistics or the Statistics Portal may be able to help recruit one. (November 2008) |
Independent component analysis (ICA) is a computational method for separating a multivariate signal into additive subcomponents supposing the mutual statistical independence of the non-Gaussian source signals. It is a special case of blind source separation.
Contents |
[edit] Definition
When the independence assumption is correct, blind ICA separation of a mixed signal gives very good results. It is also used for signals that are not supposed to be generated by a mixing for analysis purposes. A simple application of ICA is the “cocktail party problem”, where the underlying speech signals are separated from a sample data consisting of people talking simultaneously in a room. Usually the problem is simplified by assuming no time delays and echoes. An important note to consider is that if N sources are present, at least N observations (e.g. microphones) are needed to get the original signals. This constitutes the square (J = D, where D is the input dimension of the data and J is the dimension of the model). Other cases of underdetermined (J < D) and overdetermined (J > D) have been investigated.
The statistical method finds the independent components (aka factors, latent variables or sources) by maximizing the statistical independence of the estimated components. Non-Gaussianity, motivated by the central limit theorem, is one method for measuring the independence of the components. Non-Gaussianity can be measured, for instance, by kurtosis or approximations of negentropy. Mutual information is another popular criterion for measuring statistical independence of signals.
Typical algorithms for ICA use centering, whitening (usually with the eigenvalue decomposition), and dimensionality reduction as preprocessing steps in order to simplify and reduce the complexity of the problem for the actual iterative algorithm. Whitening and dimension reduction can be achieved with principal component analysis or singular value decomposition. Whitening ensures that all dimensions are treated equally a priori before the algorithm is run. Algorithms for ICA include infomax, FastICA, and JADE, but there are many others also.
In general, ICA cannot identify the actual number of source signals, a uniquely correct ordering of the source signals, nor the proper scaling (including sign) of the source signals.
ICA is important to blind signal separation and has many practical applications. It is closely related to (or even a special case of) the search for a factorial code of the data, i.e., a new vector-valued representation of each data vector such that it gets uniquely encoded by the resulting code vector (loss-free coding), but the code components are statistically independent.
[edit] Mathematical definitions
Linear independent component analysis can be divided into noiseless and noisy cases, where noiseless ICA is a special case of noisy ICA. Nonlinear ICA should be considered as a separate case.
[edit] General definition
The data is represented by the random vector  and the components as the random vector
and the components as the random vector 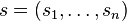 . The task is to transform the observed data x, using a linear static transformation W as
. The task is to transform the observed data x, using a linear static transformation W as
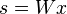 ,
,
into maximally independent components s measured by some function  of independence.
of independence.
[edit] Generative model
[edit] Linear noiseless ICA
The components xi of the observed random vector  are generated as a sum of the independent components sk,
are generated as a sum of the independent components sk,  :
:
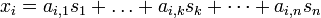
weighted by the mixing weights ai,k.
The same generative model can be written in vectorial form as  , where the observed random vector x is represented by the basis vectors
, where the observed random vector x is represented by the basis vectors 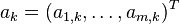 . The basis vectors ak form the columns of the mixing matrix
. The basis vectors ak form the columns of the mixing matrix  and the generative formula can be written as x = As, where
and the generative formula can be written as x = As, where  .
.
Given the model and realizations (samples) 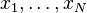 of the random vector x, the task is to estimate both the mixing matrix A and the sources s. This is done by adaptively calculating the w vectors and setting up a cost function which either maximizes the nongaussianity of the calculated sk = (wT * x) or minimizes the mutual information. In some cases, a priori knowledge of the probability distributions of the sources can be used in the cost function.
of the random vector x, the task is to estimate both the mixing matrix A and the sources s. This is done by adaptively calculating the w vectors and setting up a cost function which either maximizes the nongaussianity of the calculated sk = (wT * x) or minimizes the mutual information. In some cases, a priori knowledge of the probability distributions of the sources can be used in the cost function.
The original sources s can be recovered by multiplying the observed signals x with the inverse of the mixing matrix W = A − 1, also known as the unmixing matrix. Here it is assumed that the mixing matrix is square (n = m). If the number of basis vectors is greater than the dimensionality of the observed vectors, n < m, the task is overcomplete but is still solvable.
[edit] Linear noisy ICA
With the added assumption of zero-mean and uncorrelated Gaussian noise  , the ICA model takes the form x = As + n.
, the ICA model takes the form x = As + n.
[edit] Nonlinear ICA
The mixing of the sources does not need to be linear. Using a nonlinear mixing function 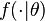 with parameters θ the nonlinear ICA model is x = f(s | θ) + n.
with parameters θ the nonlinear ICA model is x = f(s | θ) + n.
[edit] Identifiability
The independent components are identifiable up to a permutation and scaling of the sources. This identifiability requires that:
- At most one of the sources sk is Gaussian,
- The number of observed mixtures, m, must be at least as large as the number of estimated components n:
 . It is equivalent to say that the mixing matrix A must be of full rank for its inverse to exist.
. It is equivalent to say that the mixing matrix A must be of full rank for its inverse to exist.
[edit] See also
- Blind deconvolution
- Blind signal separation (BSS)
- Factor analysis
- Factorial codes
- Hilbert spectrum
- Image processing
- Non-negative matrix factorization (NMF)
- Nonlinear dimensionality reduction
- Principal component analysis (PCA)
- Projection pursuit
- Redundancy reduction
- Signal processing
- Singular value decomposition (SVD)
- Varimax rotation
[edit] References
- Pierre Comon (1994): Independent Component Analysis: a new concept?, Signal Processing, Elsevier, 36(3):287--314 (The original paper describing the concept of ICA)
- A. Hyvärinen, J. Karhunen, E. Oja (2001): Independent Component Analysis, New York: Wiley, ISBN 978-0-471-40540-5
- J.V. Stone, (2005): A Brief Introduction to Independent Component Analysis in Encyclopedia of Statistics in Behavioral Science, Volume 2, pp. 907–912, Editors Brian S. Everitt & David C. Howell, John Wiley & Sons, Ltd, Chichester, 2005 ISBN 978-0-470-86080-9
- T.-W. Lee (1998): Independent component analysis: Theory and applications, Boston, Mass: Kluwer Academic Publishers, ISBN 0 7923 8261 7
[edit] External links
- What is independent component analysis? by Aapo Hyvärinen
- Nonlinear ICA, Unsupervised Learning, Redundancy Reduction by Jürgen Schmidhuber, with links to papers
- FastICA as a package for Matlab, in R language, C++
- ICALAB Toolboxes for Matlab, developed at RIKEN
- High Performance Signal Analysis Toolkit provides C++ implementations of FastICA and Infomax
- Free software for ICA by JV Stone.
- ICA toolbox Matlab tools for ICA with Bell-Sejnowski, Molgedey-Schuster and mean field ICA. Developed at DTU.
- Demonstration of the cocktail party problem
- EEGLAB Toolbox ICA of EEG for Matlab, developed at UCSD.
- FMRLAB Toolbox ICA of fMRI for Matlab, developed at UCSD
- Discussion of ICA used in a biomedical shape-representation context
- FastICA, CuBICA, JADE and TDSEP algorithm for Python and more...

