Generalized linear model
From Wikipedia, the free encyclopedia
In statistics, the generalized linear model (GLM) is a flexible generalization of ordinary least squares regression. The GLM generalizes linear regression by allowing the linear model to be related to the response variable via a link function and by allowing the magnitude of the variance of each measurement to be a function of its predicted value.
Generalized linear models were formulated by John Nelder and Robert Wedderburn as a way of unifying various other statistical models, including linear regression, logistic regression and Poisson regression, under one framework.[1] This allowed them to develop a general algorithm for maximum likelihood estimation in all these models. It extends naturally to encompass many other models as well.
Contents |
[edit] Overview
In a GLM, each outcome of the dependent variables, Y, is assumed to be generated from a particular distribution function in the exponential family, a large range of probability distributions that includes the normal, binomial and poisson distributions, among others. The mean, μ, of the distribution depends on the independent variables, X, through:

where E(Y) is the expected value of Y; Xβ is the linear predictor, a linear combination of unknown parameters, β; g is the link function.
In this framework, the variance is typically a function, V, of the mean:

It is convenient if V follows from the exponential family distribution, but it may simply be that the variance is a function of the predicted value.
The unknown parameters, β, are typically estimated with maximum likelihood, maximum quasi-likelihood, or Bayesian techniques.
[edit] Model components
The GLM consists of three elements.
- 1. A distribution function f, from the exponential family.
- 2. A linear predictor η = Xβ .
- 3. A link function g such that E(Y) = μ = g-1(η).
[edit] Distribution function
The exponential family of distributions are those probability distributions, parameterized by θ and τ, whose density functions f (or probability mass function, for the case of a discrete distribution) can be expressed in the form

τ, called the dispersion parameter, typically is known and is usually related to the variance of the distribution. The functions a, b, c, d, and h are known. Many, although not all, common distributions are in this family.
θ is related to the mean of the distribution. If a is the identity function, then the distribution is said to be in canonical form. If, in addition, b is the identity and τ is known, then θ is called the canonical parameter and is related to the mean through
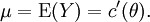
Under this scenario, the variance of the distribution can be shown to be[2]

[edit] Linear predictor
The linear predictor is the quantity which incorporates the information about the independent variables into the model. The symbol η (Greek "eta") is typically used to denote a linear predictor. It is related to the expected value of the data (thus, "predictor") through the link function.
η is expressed as linear combinations (thus, "linear") of unknown parameters β. The coefficients of the linear combination are represented as the matrix of independent variables X. η can thus be expressed as

The elements of X are either measured by the experimenters or stipulated by them in the modeling design process.
[edit] Link function
The link function provides the relationship between the linear predictor and the mean of the distribution function. There are many commonly used link functions, and their choice can be somewhat arbitrary. It can be convenient to match the domain of the link function to the range of the distribution function's mean.
When using a distribution function with a canonical parameter θ, a link function exists which allows for XTY to be a sufficient statistic for β. This occurs when the link function equates θ and the linear predictor. Following is a table of canonical link functions and their inverses (sometimes referred to as the mean function, as done here) used for several distributions in the exponential family.
| Distribution | Name | Link Function | Mean Function |
|---|---|---|---|
| Normal | Identity | 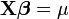 |
 |
| Exponential | Inverse |  |
 |
| Gamma | |||
| Inverse Gaussian |
Inverse squared |
 |
 |
| Poisson | Log | 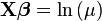 |
 |
| Binomial | Logit |  |
 |
| Multinomial |
In the cases of the exponential and gamma distributions, the domain of the canonical link function is not the same as the permitted range of the mean. In particular, the linear predictor may be negative, which would give an impossible negative mean. When maximizing the likelihood, precautions must be taken to avoid this. An alternative is to use a noncanonical link function.
[edit] Examples
[edit] General linear models
A possible point of confusion has to do with the distinction between generalized linear models and the general linear model, two broad statistical models. The general linear model may be viewed as a case of the generalized linear model with identity link. As most exact results of interest are obtained only for the general linear model, the general linear model has undergone a somewhat longer historical development. Results for the generalized linear model with non-identity link are asymptotic (tending to work well with large samples).
[edit] Linear regression
A simple, very important example of a generalized linear model (also an example of a general linear model) is linear regression. Here the distribution function is the normal distribution with constant variance and the link function is the identity, which is the canonical link if the variance is known. Unlike most other GLMs, there is a closed form solution for the maximum likelihood parameter estimates.
[edit] Binomial data
When the response data, Y, are binary (taking on only values 0 and 1), the distribution function is generally chosen to be the binomial distribution and the interpretation of μi is then the probability, p, of Yi taking on the value one.
There are several popular link functions for binomial functions; the most typical is the canonical logit link:
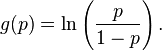
GLMs with this setup are logistic regression models.
In addition, the inverse of any continuous cumulative distribution function (CDF) can be used for the link since the CDF's range is [0, 1], the range of the binomial mean. The normal CDF Φ is a popular choice and yields the probit model. Its link is

The identity link is also sometimes used for binomial data, but a drawback of doing this is that the predicted probabilities can be greater than one or less than zero. In implementation it is possible to fix the nonsensical probabilities outside of [0,1] but interpreting the coefficients can be difficult in this model. The model's primary merit is that near p = 0.5 it is approximately a linear transformation of the probit and logit―econometricians sometimes call this the Harvard model.
The variance function for binomial data is given by:

where the dispersion parameter τ is typically fixed at exactly one. When it is not, the resulting quasi-likelihood model often described as binomial with overdispersion or quasibinomial.
[edit] Count data
Another example of generalized linear models includes Poisson regression which models count data using the Poisson distribution. The link is typically the logarithm, the canonical link.
The variance function is proportional to the mean

where the dispersion parameter τ is typically fixed at exactly one. When it is not, the resulting quasi-likelihood model is often described as poisson with overdispersion or quasipoisson.
[edit] Extensions
[edit] Correlated or clustered data
The standard GLM assumes that the observations are uncorrelated. Extensions have been developed to allow for correlation between observations, as occurs for example in longitudinal studies and clustered designs:
- Generalized estimating equations (GEEs) allow for the correlation between observations without the use of an explicit probability model for the origin of the correlations, so there is no explicit likelihood. They are suitable when the random effects and their variances are not of inherent interest, as they allow for the correlation without explaining its origin. The focus is on estimating the average response over the population ("population-averaged" effects) rather than the regression parameters that would enable prediction of the effect of changing one or more components of X on a given individual. GEEs are usually used in conjunction with Huber-White standard errors.
- Generalized linear mixed models (GLMMs) are an extension to GLMs that includes random effects in the linear predictor, giving an explicit probability model that explains the origin of the correlations. The resulting "subject-specific" parameter estimates are suitable when the focus is on estimating the effect of changing one or more components of X on a given individual. GLMMs are a particular type of multilevel model (mixed model). In general, fitting GLMMs is more computationally complex and intensive than fitting GEEs.
- Hierarchical generalized linear models (HGLMs) are similar to GLMMs apart from two distinctions:
-
- The random effects can have any distribution in the exponential family, whereas current GLMMs nearly always have normal random effects;
- They are not as computationally intensive, as instead of integrating out the random effects they are based on a modified form of likelihood known as the hierarchical likelihood or h-likelihood.
- The theoretical basis and accuracy of the methods used in HGLMs have been the subject of some debate in the statistical literature. As of 2008, the method is only available in one statistical software package, namely Genstat.[3]
[edit] Generalized additive models
Generalized additive models (GAMs) [4] are another extension to GLMs in which the linear predictor η is not restricted to be linear in the covariates X but is an additive function of the xis:

The smooth functions fi are estimated from the data. In general this requires a large number of data points and is computationally intensive.
[edit] Multinomial regression
The binomial case may be easily extended to allow for a multinomial distribution as the response. There are two ways in which this is usually done:
[edit] Ordered response
If the response variable is an ordinal measurement, then one may fit a model function of the form:
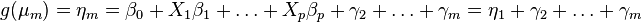 where
where  .
.
for m > 2. Different links g lead to proportional odds models or ordered probit models.
[edit] Unordered response
If the response variable nominal measurement, or the data does not satisfy the assumptions of an ordered model, one may fit a model of the following form:
 where
where  .
.
for m > 2. Different links g lead to multinomial logit or multinomial probit models. These are less efficient then the ordered response models, as more parameters are estimated.
[edit] Etymology
The term "generalized linear model", and especially its abbreviation GLM, can be confused with general linear model. John Nelder has expressed regret about this in a conversation with Stephen Senn:
Senn: I must confess to having some confusion when I was a young statistician between general linear models and generalized linear models. Do you regret the terminology?
Nelder: I think probably I do. I suspect we should have found some more fancy name for it that would have stuck and not been confused with the general linear model, although general and generalized are not quite the same. I can see why it might have been better to have thought of something else.[5]
[edit] External sources
- Dobson, A.J.; Barnett, A.G. (2008). Introduction to Generalized Linear Models, Third Edition. London: Chapman and Hall/CRC. [1]
- Hardin, James; Hilbe, Joseph (2001, 2007). Generalized Linear Models and Extensions. College Station: Stata Press. [2]
- Hardin, James; Hilbe, Joseph (2003). Generalized Estimating Equations. London: Chapman and Hall/CRC. [3]
- Hastie, T.J.; Tibshirani, R.J. (1990). Generalized Additive Models. Chapman & Hall/CRC. ISBN 9780412343902. [4]
- Wood, Simon (2006). Generalized Additive Models: An Introduction with R. Chapman & Hall/CRC. ISBN 1-584-88474-6. [5]
- McCullagh, Peter; Nelder, John (1989). Generalized Linear Models. London: Chapman and Hall. ISBN 0-412-31760-5. [6]
- Lee, Youngjo; Nelder, John Pawitan, Yudi (2006). Generalized Linear Models with Random Effects: Unified Analysis via H-likelihood. Boca Raton: Chapman and Hall/CRC. ISBN 1-584-88631-5. [7]
- Nelder, John; Robert Wedderburn (1972). "Generalized Linear Models". Journal of the Royal Statistical Society. Series A (General) 135: 370–384. doi:.
- Zeger, Scott L.; Liang, Kung-Yee; Albert, Paul S. (1988). "Models for Longitudinal Data: A Generalized Estimating Equation Approach". Biometrics 44 (4): 1049–1060. doi:. http://links.jstor.org/sici?sici=0006-341X%28198812%2944%3A4%3C1049%3AMFLDAG%3E2.0.CO%3B2-R.
[edit] References
- ^ McCullagh, Peter; Nelder, John (1989). Generalized Linear Models. London: Chapman and Hall. ISBN 0-412-31760-5. Chapter 1.
- ^ McCullagh, Peter; Nelder, John (1989). Generalized Linear Models. London: Chapman and Hall. ISBN 0-412-31760-5. Chapter 2.
- ^ Youngjo Lee; John Nelder and Yudi Pawitan (2006). Generalized Linear Models with Random Effects: Unified Analysis via H-likelihood. Chapman & Hall/CRC. http://www.crcpress.com/shopping_cart/products/product_detail.asp?sku=C6315.
- ^ Hastie, T. J. and Tibshirani, R. J. (1990). Generalized Additive Models. Chapman & Hall/CRC. ISBN 9780412343902.
- ^ Senn, Stephen (2003). "A conversation with John Nelder". Statistical Science 18 (1): 118–131. doi:. http://projecteuclid.org/euclid.ss/1056397489.

